








公众号/将门创投
From: Google 编译:T.R
数据对于深度学习来说至关重要,而数据增强策略对于提升训练样本数据量、改善模型稳定性和鲁棒性,提高对于真实世界的适应性和泛化性具有重要的作用。
虽然在图像分类中数据增强有着广泛的使用,但将数据增强用于目标检测的系统性研究还较少。此外由于目标检测数据的标记成本比图像分类更高,数据增强策略在有限数据的情况下除了能提高模型表现同时还能节省数据成本。
来自谷歌的研究人员针对目标检测任务提出了一种基于学习的数据增强策略,通过在训练数据上进行增强策略搜索和验证集的性能测试来寻找最优的数据增强方法,有效地提升了模型的表现,同时学习到的数据增强策略对于不同数据、基础网络和模型架构都具有效的泛化性和适应性。值得一提的是,文章的作者来自提出著名的神经架构搜索及其相关方法的研究团队。
数据增强广泛是机器学习中常用的数据处理手段,不同的数据集通常会利用针对性的数据处理手段来处理。例如MNIST大多使用尺度、旋转和平移的操作,也有加入颜色、噪声等变换,而针对自然图像,更多采用进行和随机裁剪的方法来进行。还包括以对象为中心的裁剪、针对图像片的增减和变换等,但这些方法大都针对特定的数据来处理并集中于图像分类问题。
但由于数据标记的成本很高,数据增强对于目标检测有着更为重要的实际意义。由于目标检测的复杂性使得有效的数据增强策略难以获取。为了得到有效的数据增强策略并应用于目标检测任务中,研究人员希望利用算法搜索到一套新颖的检测数据增强策略,并能够有效地应用于不同的数据集、数据尺寸、基础网络和检测架构上,有效提升算法的性能。
对于目标检测来说通常需要考虑目标框(bounding box, bbox)与变换后图像连续性,研究人员针对bbox内部的图像提出了一系列变换,同时探索了图像整体变化时如何调整bbox的策略。通过定义一系列子策略集和多个图像操作变换,最终将这一问题归结为离散空间中的优化问题来进行求解。
首先研究人员将图像增强策略定义为K个子策略的无序集合,在训练时从中随机选取策略对图像进行数据增强。而其中每一个策略则包含了N个图先变换,这些图像变换将依次作用于被增强的数据,研究的目的在于从中搜索出最有效的策略。
这些变量共同定义了一个离散优化问题的搜索空间,针对目标检测任务的数据增强,研究人员将设置K=5,N=2。其中搜索空间总共包含了五个子策略,每个子策略包含了2种图像操作,而每个操作同时包含了这个操作对应的概率p和操作的具体数值m两个参数。这里的概率定义的增强策略在数据样本上进行的随机性,而m则定义了增强的幅度。
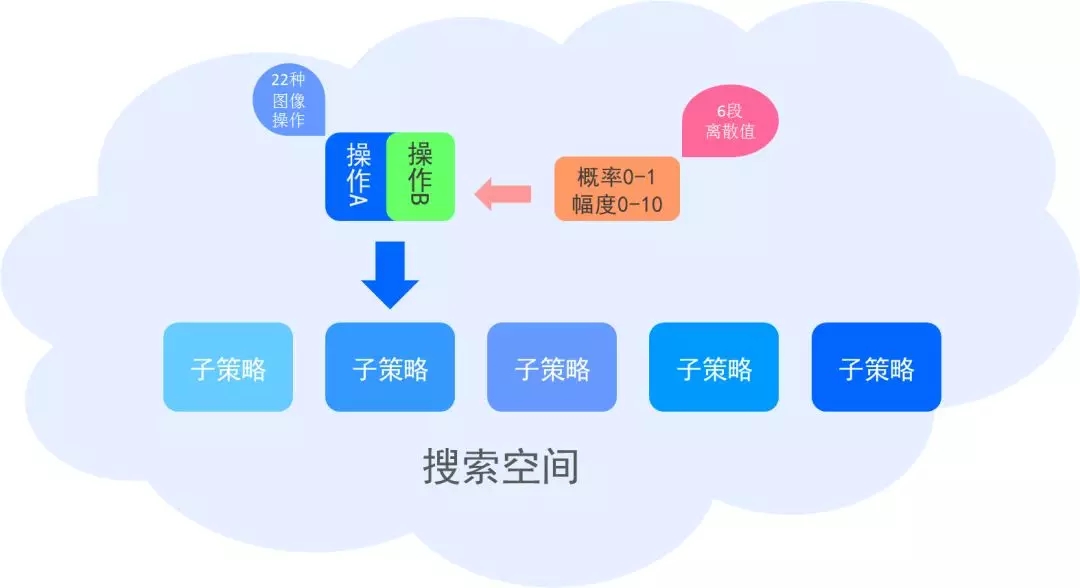
具体来说,研究人员从实验中总结了22中有利于检测的数据增强算法,分别是颜色操作、几何变换和bbox操作。
在使用过程中,研究人员将每种操作的幅度都归一化到[0,10],对应L=6等间距的空间,对应概率也是一个M=6的等间距空间,这一取值平衡了强化学习算法计算的可追溯性和学习能力。
针对这样的数值定义可以计算出每个策略需要搜索的空间包含(22LM)^2,而五个策略对应的空间为(22*6*6)^10~9.6*10^18如此大的搜索空间一定需要高效的方法才能进行有效的处理。
在这篇文章中研究人员采用了基于RNN输出空间表示离散值,同时利用RL算法来更新模型权重。其中PPO(proximal policy optimization)被用于搜索策略。RNN每次需要进行30步来预测输出,这来自于5个子策略,每个子策略两个操作,每个操作包含概率、幅度和操作本身三个参数,其乘积即为30。
在训练过程中,研究人员为了减小整体计算量从COCO数据集中选取了5K图像来训练增强算法。算法利用了ResNet-50作为主干网络、RetinaNet检测器来从零开始构建目标检测器,并利用在7392张COCO子验证集上的mAP作为奖励信号来更新控制器迭代搜索空间参数。
这一算法需要消耗巨大的算力,在400个TPUs上训练了48个小时完成了20K增强策略的训练,最终得到的数据增强策略使得目标检测得到了较大的提升,其中最好的几个策略能够广泛应用到不同的数据集、大小和架构上去。
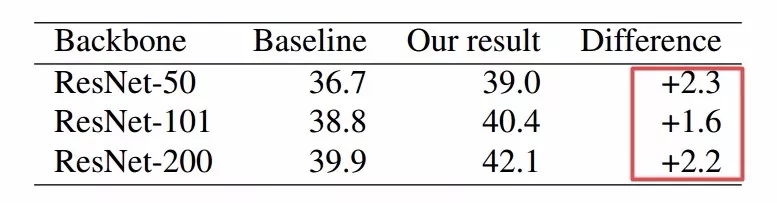
训练后的结果显示,算法通过验证集的测试得到最多的图像增强操作是旋转操作,同时图像均衡和bbox在Y方向上的平移操作也是排名较为靠前的操作。研究人员首先将学习到的策略进行了整体评测,在Res-Net和RetinaNet检测器上都实现了较大幅度的提升:
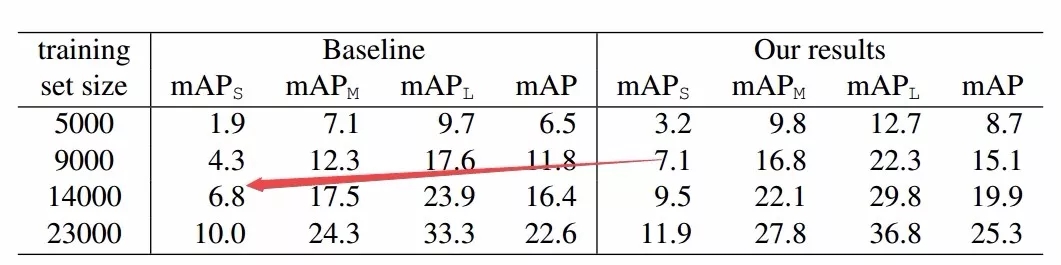
为了探索哪些操作对于目标检测算法带来的优势较大,研究人员将增强操作拆解成了颜色、几何与bbox相关操作,并分别测试了对于基准网络的提升,下表显示了不同操作叠加下对于目标检测性能的影响。

此外研究人员还探索了不同模型下数据增强策略的有效性,并通过增加图像分辨率和锚的数量实现了50.7mAP!

同时也在不同的数据上验证了这一算法的有效性。研究人员还探索了用于训练数据增强策略数据集的大小对于目标检测算法提升的效果,虽然随着训练数据的增加,数据增强的效果逐渐减弱。
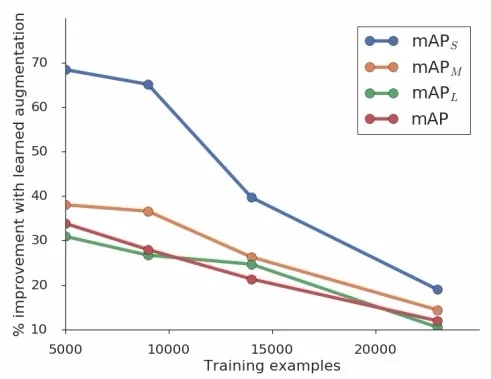
但这种方法针对小数据集和小物体的检测却具有明显的效果。同时对于较为困难的AP75任务也有较好的表现,这意味着数据增强策略帮助算法学习到了bbox位置出更细粒度的空间细节特征,这也同时改善了小物体的检测性能。下表中mAPs显示了小物体检测提升的情况。
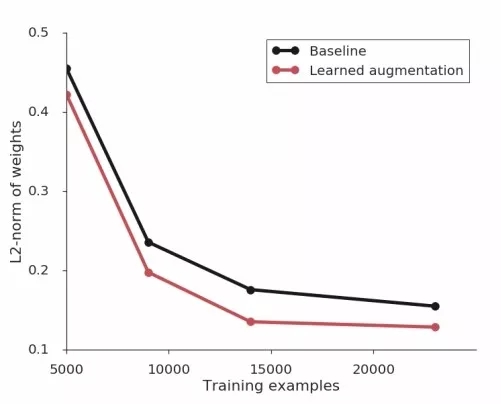
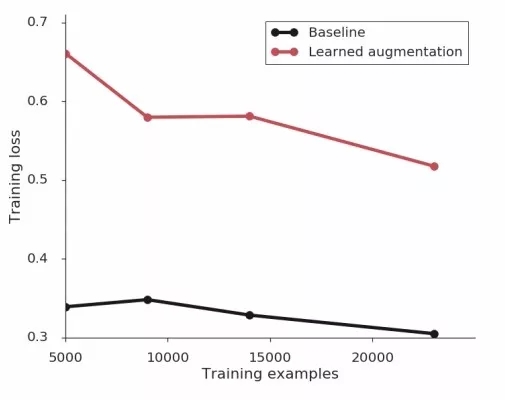
在改进模型正则化方面,研究人员发现了训练数据大的情况下损失会提升,同时随着数据量的增加L2会变小,数据增强策略进一步减少了权重的衰减。研究人员发现在使用有效数据增强策略的同时,就不需要正则化技术来帮助网络更好的训练了。
如果想要了解更多详细信息,请参看论文:
https://arxiv.org/pdf/1906.11172.pdf
https://twitter.com/ekindogus
https://twitter.com/quocleix
https://github.com/tensorflow/tpu/tree/master/models/official/detection
https://lilianweng.github.io/lil-log/FAQ.html
pic from:
https://cdn.dribbble.com/users/1044993/screenshots/5262629/sniffing_dribbble.png
https://cdn.dribbble.com/users/1884663/screenshots/6450429/vehicle-detection_1x.jpg
https://lilianweng.github.io/lil-log/FAQ.html
https://dribbble.com/shots/3020827-The-CRM-Lab

 友情链接
友情链接