





但这种情况正在开始改变。借助一种称为稀疏卷积神经网络 (Sparse Convolutional Neural Network,SCNN) 的机器学习工具,研究人员可以专注于数据的相关部分并筛选出其余部分。

PENCIL的分类模式识别特定表型富集的亚群,与差异丰度测试算法具有相同的应用。然而,基于监督学习的 PENCIL 框架提供了一种更灵活的方式来同时选择基因和识别亚群。为了证明这一独特的特征,与其他方法进行比较的模拟被设计为需要基因选择。

在这里,艾伦图灵研究所、伦敦大学、罗氏制药以及 Genentech 的研究人员,概述了该领域的研究进展,并提出了从具有结构化缺失的数据中学习的一系列重大挑战。

机器学习和基础学科交叉在近年受到越来越多的关注。能够从大量数据中学习的 AI,是否能够像人类一样,从数据中发现规律?当神经网络被用于解决物理问题时,是否有可能学习到物理知识?



Bülent Kızıltan 博士既是一名科学家也是一位企业高管,他通过将创业思维与卓越科学相结合从而推动创新。目前,他在诺华负责因果分析和预测分析的创新工作。以下是他关于药物发现中的数据科学、预测分析和人工智能的访谈内容。



公众号/ ScienceAI(ID:Philosophyai) 作者/凯霞 空气动力学面临的挑战之一是改进描述 […]


近日,普渡大学(Purdue University)一个科研团队创造出一项全新技术,旨在用彩色“数字字符”取代莫尔斯码,以实现光存储的现代化。


「弱人工智能」对应深度学习,围绕单一任务点,需要大量数据做支撑,有时候不那么可靠,可移植性差/移植过后需要大量重新训练。




公众号/大数据文摘 大数据文摘出品 来源:verturebeat 编译:蔡婕、夏雅薇 新型冠状病毒的传播,导致 […]
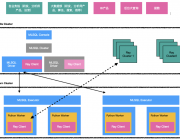
大数据在语言层面以 Java/Scala/SQL 为主导,其中 SQL 是交互语言,Java/Scala 则是大数据体系的构建语言。AI 则是以 Python/C++ 为主导,其中 Python 为交互语言,C++ 为算法体系的构建语言。
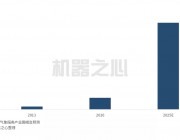




那么对于数据驱动的机器人方法也不仅仅需要发展优秀的强化学习算法,同时也需要建立大规模的机器人学数据。










 友情链接
友情链接