








公众号/将门创投
From: Google 编译: T R

近年来,机器翻译飞速进展,极大地促进了自动翻译任务的进步。目前针对语料资源丰富的语言已经开发出了非常多的技术来提升翻译能力,但针对语料资源匮乏的语言 (Low-Resource Languages, LRL),其翻译质量的提升还有很长的路要走。来自谷歌的研究人员在针对语言的翻译质量提升上取得了一系列突破,特别是针对LRL的翻译性能得到了大幅提升。通过对最新进展的创新组合与外延拓展实现了将语言模型应用于大规模的、带噪声的网络挖掘文本上。
机器翻译近年来的飞速进展极大地促进了自动翻译任务的进步,像GNMT等神经翻译模型的引入极大地促进了100多种语言翻译质量的提升。然而除了针对具体的翻译任务,先进的神经翻译模型和人类翻译相比在整体上却还有着不小的差距。
目前针对语料资源丰富的语言,包括德语和西班牙语等研究人员已经开发出了非常多的技术来提升翻译能力,但针对像约鲁巴语和马拉雅拉姆语等语料资源匮乏的语言,其翻译质量的提升还有很长的路要走。虽然在可控的实验室环境下人们提出了诸多方法来提升LRL的翻译质量,但却难以有效处理实际应用中来自于网络的大规模多样性数据。
近日,来自谷歌的研究人员在针对语言的翻译质量提升上取得了一系列突破,特别是针对LRL的翻译性能得到了大幅提升。通过对最新进展的创新组合与外延拓展实现了将语言模型应用于大规模的、带噪声的网络挖掘文本上。这些技术既包括了改进模型的结构和训练过程,对于数据集噪声的处理,通过M4建模增加多语言迁移的学习以及单语言数据的利用能力。下图显示了最新的技术进展在100多种语言上实现了平均+5 BLEU的分数提升:
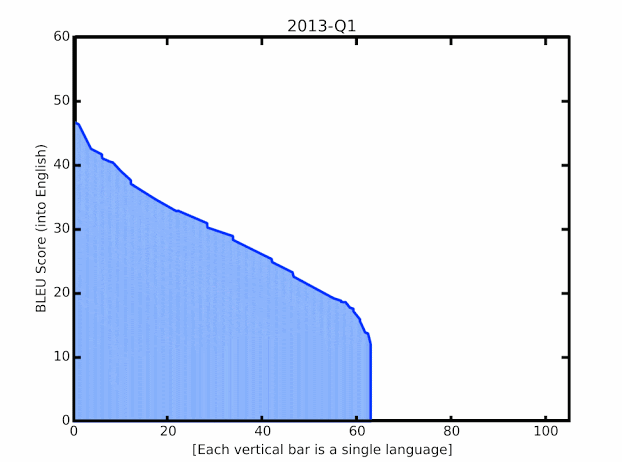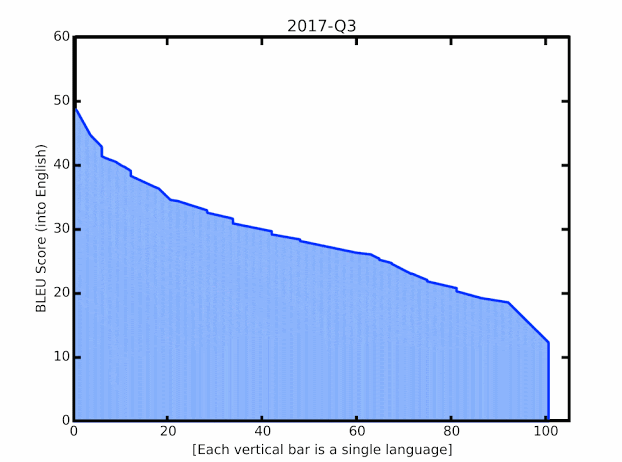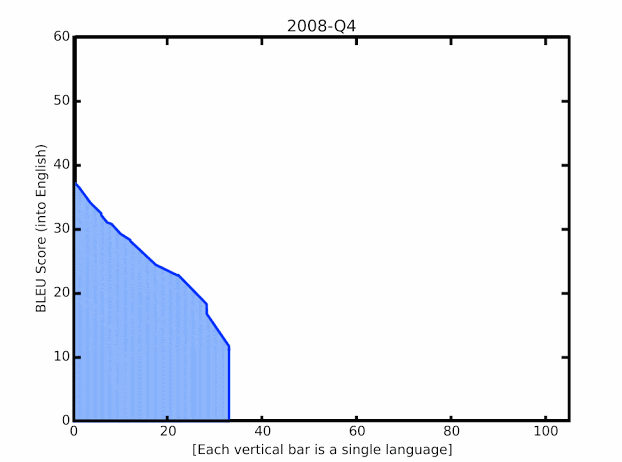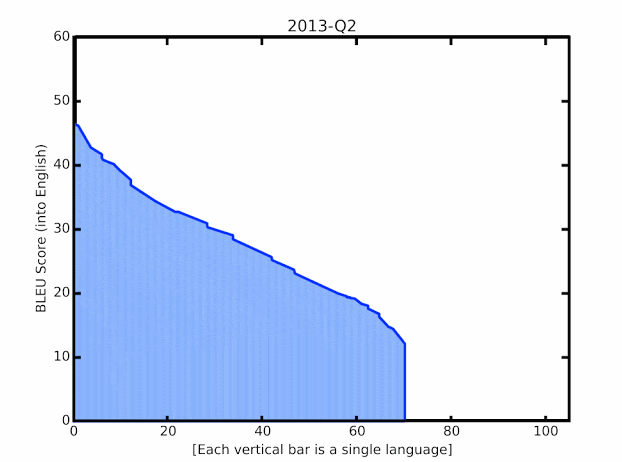
谷歌翻译模型在BLEU分数上的提升,绿色显示了去年以来的质量提升进展。
翻译模型在资源丰富和
资源匮乏语言上的最新进展
混合模型:在四年前谷歌就引入了基于RNN的GNMT模型,使得翻译质量大幅提升同时也增加了覆盖的语言范围。在解耦模型不同部分的表现后,研究人员将原始的GNMT系统中的训练模型模型替换为了transformer编码器和RNN解码器,并利用了Lingvo框架进行了实现。
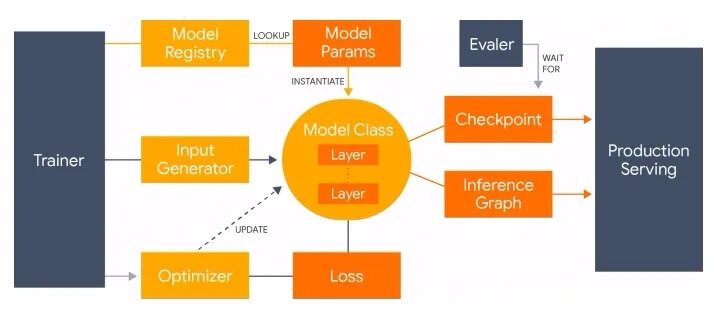
基于Tensorflow的Lingvo框架,用于Sequence-to-Sequence Modeling
Transformer模型在机器翻译任务中一般都会比RNN模型更有效,但研究发现性能增益主要来源于transformer的编码器,而解码器部分与RNN相比却没有显著的性能提升。由于RNN模型在推理时具有显著的速度优势,研究人员针对性地进行了多用优化以便于与Transformer编码器有效耦合。实验表明,混合模型的质量更好,训练稳定延时较小。
网络:神经机器翻译需要利用翻译好的句子和文件进行训练,这些数据一般从公开网络上爬取。与基于短语的翻译技术相比,神经机器翻译对于数据的质量更为敏感。为了获取更为高质量的数据,研究人员将原先的数据收集系统替换为了聚焦于精度和召回率的新数据挖掘系统。此外还将网络爬虫从基于字典的模型转换为了基于嵌入的模型并应用在了14个语言对上。这种方法在不损失精度的情况下,平均增加了29%的句子收集量。
数据噪声建模:训练数据中的噪声会造成模型性能的下降,为了解决噪声问题研究人员应用了去噪神经机器翻译训练的结果为每一个训练样本赋予分数,模型首先在噪声数据集上训练,而后又在干净的数据集上进行调优。这个问题被转换为了渐进学习的问题,既模型首先在所有数据上训练,而后逐渐在更小更干净的子数据集上进行调优学习。
针对资源匮乏语言翻译的最新进展
回译:回译在数据资源匮乏语言的神经翻译模型中被广泛应用,这项技术使用了合成的并行数据来增强现有数据 (每种语言中的每个句子与其翻译配对构成),其中一种语言的句子由人类撰写,而其翻译结果则由神经翻译模型生成。通过与谷歌翻译模型的回译进行写作,使得研究人员可以利用更为丰富的多语言文本数据来更好地训练网络上的LRL数据。这对于增加LRL的流利程度特别有效。
M4 建模:M4使用中用于LRL建模的有效技术,它使用单一庞大的模型来训练所有语言对英语的翻译模型,这使得大规模的迁移学习得以展开。例如像依地语这样的微小语种将从与其他大语种的联合训练中受益 (例如德语、丹麦语、荷兰语等),虽然这上百种语言并没有直接的语言联系,但还是能为模型提供有益的训练信号。
模型质量的判定
目前常用的机器翻译指标是BLEU分数,它基于系统翻译结果与人类翻译结果间的相似性进行评分。在最新的翻译模型上,相比GNMT平均提升了5个点,而针对资源较为匮乏的50种语言则得到了平均7分的提升。这一巨大的提升和四年前从基于短语翻译向神经机器翻译的进步一样令人瞩目。
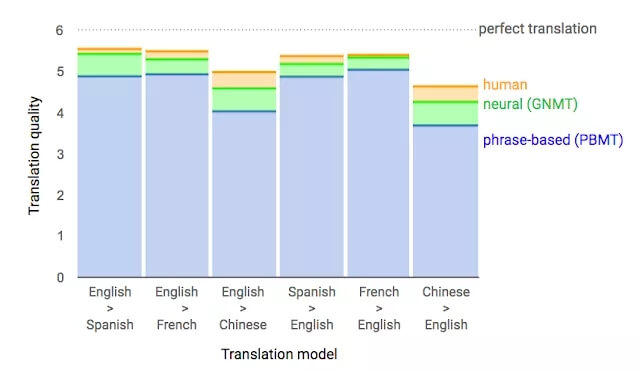
四年前GNMT的进步
尽管BLUE评分是广为人知的近似测评标准,但对于高质量的翻译系统还有一系列坑。先前就有工作研究过源端或者目标端的翻译(腔)效果是如何对BLUE分数造成偏颇影响的。这会使得翻译结果读起来很拗口。因此这一工作同时还引入了人类对于所有新模型进行测评,以保证BLUE上取得的分数提升真实有效。
除了对整体性能的增强外,新模型还提升了对于“魔性”机器翻译的鲁棒性,这种现象主要是在输入无意义的内容时,机器会生成奇怪魔幻的翻译结果。这一问题普遍存在于训练数据量较小的模型中,对很多训练数据匮乏的语言有着显著的影响。比如输入一串特鲁古语“ష ష ష ష ష ష ష ష ష ష ష ష ష ష ష”,原先的翻译模型会生成“Shenzhen Shenzhen Shaw International Airport (SSH)”,这也许是模型阐释着模仿语言对应的声音结果,而新的语言则能正确的翻译出下面的结果“Sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh”。鲁棒性得到了很好的提升。
结论
最近的进步使得机器翻译模型性能更强,针对108种语言特别是资源匮乏的语言都展现出了较好的翻译能力。但我们需要保持清醒的是,自动机器翻译的质量还有很大的提升空间,这些模型依然会受到典型翻译错误的困扰,包括在特定领域内性能下降、混杂不同方言、直译过多、非正式和口语上性能不佳等。在神经机器翻译的道路上,我们取得了不错的成绩,但是还有很长的路要走!
ref:
https://zhuanlan.zhihu.com/p/77286602
Lingvo: https://arxiv.org/pdf/1902.08295.pdf
phrase NT:https://blog.csdn.net/mmc2015/article/details/73379986
GPT:https://jalammar.github.io/illustrated-gpt2/
images:https://in.pinterest.com/pin/411516484672331831
icon:https://www.iconfinder.com/icons/5882211/google_logo_translate_translation_icon

 友情链接
友情链接