








公众号/机器之心
机器之心整理
参与:思源、蛋酱、泽南
从反传的自动微分机制,到不平行语料的翻译模型,ICLR 2020 这 9 篇满分论文值得你仔细阅读。
早在去年12月,ICLR 2020的论文接收结果就已经出来了,其接收率达到了26.5%。ICLR 2020今年4月26日将在埃塞俄比亚首都亚的斯亚贝巴举行,因为这次会议只保留了四个等级:reject、weak reject、weak accept和accept,因此有30多篇论文获得了“满分”。
在这篇文章中,我们将简介其中的9篇满分(全8分)论文,它们最终都被接收为Talk 论文,届时论文作者会在大会上做长达十多分钟的演讲报告。

论文:BackPACK: Packing more into Backprop
链接:https://openreview.net/forum?id=BJlrF24twB
机构:图宾根大学、不列颠哥伦比亚大学
在深度学习中,自动微分框架只在计算梯度时才是最强的。但实际上,小批量梯度的方差或者其它逼近海塞矩阵的方法,可以和梯度一样高效地计算。研究者对这些计算值非常感兴趣,但DL框架并不支持自动计算,且手动执行又异常繁杂。
为了解决这个问题,来自图宾根大学的研究者在本文中提出一种基于PyTorch的高效框架BackPACK,该框架可以扩展反向传播算法,进而从一阶和二阶导数中提取额外信息。研究者对深度神经网络上额外数量的计算进行了基准测试,并提供了一个测试最近几种曲率估算优化的示例应用,最终证实了BackPACK的性能。
BackPACK项目地址:https://github.com/toiaydcdyywlhzvlob/backpack

图注:BACKPACK可以和PyTorch无缝拼接,并在反向传播中获得更多的信息,如上右图可以获取梯度的方差信息。
评审决定:接收为Talk论文;
评审意见:这篇论文高效的计算了各种反传的量,包括梯度的方差估计、多种海塞矩阵近似量,以及梯度量。与此同时,论文还提供了软件包,所有评审者都认为改论文是非常好的工作,大会应该接收它。
论文:Mirror-Generative Neural Machine Translation
链接:https://openreview.net/forum?id=HkxQRTNYPH
机构:南京大学、字节跳动
训练神经机器翻译模型通常需要大量平行语料,它们是非常昂贵的,那么我们为什么不考虑充分利用非平行语料训练翻译模型?
在这篇论文中,研究者提出了一种名为镜像-生成式NMT的模型(MGNMT),它由单一的架构组成。该架构集成了源语言到目标语言的翻译模型、目标语言到源语言的翻译模型,其中两种翻译模型与语言模型都共享相同的潜在语义空间。因此,整个架构的两种翻译模型都可以从非并行数据中更高效地学习。
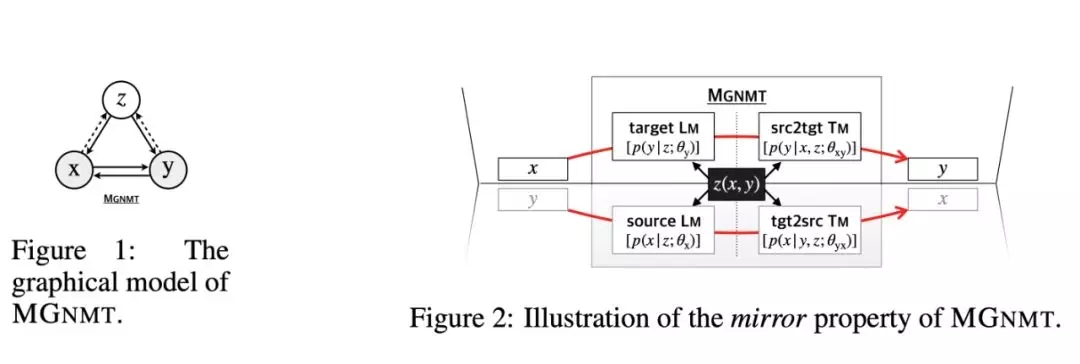
上面图1和图2分别展示了MGNMT的图示与镜像属性。在图1中,x和y分别是不同的语言,它们之间是需要互译的,与此同时,这两种语言同时共享隐藏语义空间z。在图2中,研究者展示了x、y、z三者具体的关系是什么样的,不论是语言模型还是翻译模型,隐藏变量z都是共享的。
评审决定:接收为Talk论文;
评审意见:这篇论文提出了一种新方法以考虑生成式神经机器翻译模型中的双向互译,该方法显著提升了翻译准确度。三位评审者都非常欣赏这篇论文,尽管他们注意到性能收益会随着模型复杂度的提升而变小。不管怎么样,该基线结果是非常有竞争力的,也许在这些数据集上的提升以后并不会特别大了。总体而言,我发现这篇论文非常优秀,并且强烈建议接收这篇论文,也许它可以作为口头报告论文。
论文:GenDICE: Generalized Offline Estimation of Stationary Values
链接:https://openreview.net/forum?id=HkxlcnVFwB
机构:杜克大学,谷歌
马尔可夫链的平稳分布(stationary distribution)所定义的数量是强化学习和蒙特卡洛方法中的一个重要问题。在实际应用程序中,许多对基础转换运算符的访问仅限于已经收集的固定数据集,而不包括与环境的其他交互。
研究者认为,在固定数据的情况下,完成一致的估计仍然是有可能的,重要的应用中仍然可以实现有效估计。研究者提出了GenDICE算法,并证明了该方法在一般条件下的一致性。此外,研究者还提供了详细的错误分析,并演示了在基准任务上的强大经验性能。
评审决定:接收为Talk论文;
评审意见:作者开发了应用于Infinite Horizon强化学习任务的离策略价值评估框架,用于评估马尔可夫链的平稳分布。审稿人对这项工作印象非常深刻。
论文:A Theory of Usable Information under Computational Constraints
链接:https://openreview.net/forum?id=r1eBeyHFDH
机构:北京大学、斯坦福大学等
研究者提出了一个用于在复杂系统中进行信息推理的新框架。该研究的基础是香农信息理论的变体扩展,该方法考虑了观察者的建模能力与计算约束。与香农的互信息不同,新框架并不违反数据处理不平衡的情况,可以通过计算构建F-information。这与深度学习分层抽取特征信息的表达方式类似。
根据实验,研究者证明预测性F-information比相互信息对结构学习和公平表示学习更有效。
评审决定:接收为Talk论文;
评审意见:所有评审者都接收了该论文。
论文:CATER: A diagnostic dataset for Compositional Actions & TEmporal Reasoning
链接:https://openreview.net/forum?id=HJgzt2VKPB
机构:卡内基梅隆大学
在这篇论文中,研究者假设当前视频数据集存在一些隐式偏差,尤其是在场景和目标结构上,这可能会使时间结构改变。为此,研究者构建了一个具有完全可观察和可控制的目标、场景偏置,这样的视频数据集确实需要时空的理解才能解决,研究者将该数据集命名为CATER。
除了具有挑战性外,CATER还提供了许多诊断工具,可以通过完全可观察和可控制的方式来分析现代时空视频架构。通过CATER,我们可以洞悉某些最新的深度视频体系结构。
评审决定:接收为Talk论文;
评审意见:总体来说,所有评审者都发现该论文比较易读,并且对于数据集构造、任务定义、实验设定与分析都提供了足够的信息。该论文收到所有评审员的一致赞同(3 accepts)。
论文:Dynamics-Aware Unsupervised Skill Discovery
链接:https://openreview.net/forum?id=HJgLZR4KvH
机构:谷歌、剑桥大学

通过新方法DADS,人形智能体可以在无奖励机制的情况下自行发现运动的合理机制。
传统上,基于模型的强化学习(MBRL)是旨在学习全环境动态的模型。优秀的模型应该倾向于让算法生成多种不同问题的解法。在这项工作中,研究人员结合了基于模型和无模型的基本学习方法,从而简化了基于模型的计划,提出了无监督学习算法Dynamics-Aware Discovery of Skills(DADS)。这种方法能发现可预测的行为并学习其动态。从理论上讲,这种方法可以学习无数种行为动态。
实验证明,这种zero-shot规划方法显著优于标准MBRL和无模型目标条件RL方法,可以处理稀疏奖励任务。
评审决定:接收为Talk论文;
评审意见:这是一篇非常有意思的无监督技能学习论文,它基于技能效果的可预测性,并将它们整合到基于模型的强化学习中。因为所表达想法和写作的清晰,同时因为令人信服的实验,这篇论文很明确应给被接收。
论文:Restricting the Flow: Information Bottlenecks for Attribution
链接:https://openreview.net/forum?id=S1xWh1rYwB
机构:慕尼黑工业大学、柏林自由大学
归因方法(Attribution method)提供了对机器学习模型(如人工神经网络)决策的见解。对于给定的输入样本,这类方法为每个单独的输入变量(例如图片的像素)分配相关性分数。在这项工作中,作者将信息瓶颈概念用于归因。通过将噪声添加到中间特征图,我们可以限制信息流,并量化(以bit为单位)图像区域中提供的信息。作者在VGG-16和ResNet-50上与十个不同基线模型进行了比较,新方法在六种配置上有五种优于所有基线。
评审决定:接收为Talk论文;
评审意见:三个评审者都强烈建议接收该论文。该项研究非常清晰、新颖,同时对该领域有显著的贡献。
论文:Mathematical Reasoning in Latent Space
链接:https://openreview.net/forum?id=Ske31kBtPr
机构:自谷歌研究院
作者设计了一种简单的实验,以研究神经网络是否可以在固定维度的隐空间中执行近似推理的多个步骤,发现算法可以成功地对语句执行的一组重写(即转换),表示该语句的基本语义特征。实验证明,图神经网络可以对语句的重写成功进行效果很好地预测,在隐形传播的多步骤情况下也是如此。
评审决定:接收为Talk论文;
评审意见:这篇论文受到了评审者的一致好评,其主题也非常有意思,关注潜在空间中的数学推理。领域主席统一推荐该论文接收为口头报告论文,因此可以更形象地展示本文所进行的工作。
论文:Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity
链接:https://openreview.net/forum?id=BJgnXpVYwS¬eId=KA65jj-wX
机构:麻省理工学院
作者提供了梯度剪裁在训练深度神经网络时有效性的合理解释。其关键因素是在实际神经网络训练样本中导出的新平滑度条件。研究人员观察到的梯度平滑,是一阶优化算法分析的核心概念,通常被认为是一个常数,证明了沿深度神经网络训练轨迹的显著变化。此外,该平滑度与梯度范数成正相关,并且与其他研究中的标准假设相反:它可以随着梯度范数而增长。这些观察结果限制了现有算法理论的适用性,后者依赖于平滑度的固定界限。
评审决定:接收为Talk论文;
评审意见:梯度裁剪目前变得越来越重要,因此很高兴能看到论文能从理论的角度挖掘它的优秀性能。所有评审都非常欣赏该项工作与最终结果。

 友情链接
友情链接