








公众号/AI前线
作者 | Chris Ying 等
编译 | 郝毅
编辑 | Natalie
AI 前线导读: 随着技术、算力的发展,在 ImageNet 上训练 ResNet-50 的速度被不断刷新。2018 年 7 月,腾讯机智机器学习平台团队在 ImageNet 数据集上仅用 6.6 分钟就训练好 ResNet-50,创造了 AI 训练世界纪录;一周前,壕无人性的索尼用 2176 块 V100 GPU 将这一纪录缩短到了 224 秒;如今,这一纪录再次被谷歌刷新……
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
深度学习非常依赖于硬件条件,它是一个计算密集型的任务。硬件供应商通过在大型计算集群中部署更快的加速器来做出更快的相应。在 petaFLOPS(运算能力单位,每秒千万亿次浮点数运算)规模的设备上训练深度学习模型需要同时面临算法和系统软件两方面的挑战。Google 于近日推出了一种大规模计算集群的图像分类人物训练解决方案,相关论文发表于 Arxiv:Image Classification at Supercomputer Scale。本文的作者使用 Google TPU v3 Pod 训练 ResNet-50,在识别率没有降低的情况下,仅使用了 2.2 分钟。

深度神经网络的成功应用与发展离不开疯狂增长的算力,在许多领域,深度学习的发展可以说是由硬件驱动的。在深度网络的训练过程中,最关键的部分就是使用随机梯度下降算法(SGD)优化网络权重。通常情况下,模型需要使用 SGD 在一个数据集上进行多次的便利才能达到收敛。在整个过程中,浮点数运算能力显得至关重要。例如,在 ImageNet 数据库上训练 ResNet-50 模型,遍历一次数据库需要 3.2 万万亿次浮点数运算。而使模型达到收敛,通常需要遍历 90 次数据库。
尽管硬件加速设备(例如 GPU、TPU)已经加快了迭代的次数,使用单个加速设备在大规模数据库训练大型的神经网络仍然需要几个小时或数天的时间。最常见的加速方法便是通过分布式的 SGD 算法使用多个设备并行训练,将每个 mini-batch 分布在多个相同的加速设备上。
以往大家都喜欢用异步分布式 SGD 算法在将多个线程联合起来进行训练,但是近期的一些工作发现,异步分布式 SGD 算法优化的模型在收敛程度和验证准确率方面都不如同步分布式 SGD 训练出的模型。但是,为了保证在提速的同时模型的质量不会有所损失,在使用同步分布式 SGD 算法的过程中,会遇到很多技术和硬件方面的瓶颈,作者总结出以下几点:
本文的作者提出了一种同步的分布式 SGD 优化算法,同时还提出了几个大规模分布式深度学习训练过程中使用的机器学习方法和优化方法,在加速收敛的过程中保证模型的质量没有损失。

本文的作者受之前大规模训练方法的启发,在实验过程中使用了以下一些技术:
批归一化在图像分类任务中有着不可或缺的作用,它通过对一个 mini-batch 内的数据进行归一化,使得经过 batch-norm 层的数据服从相同均值与方差的分布,使得下层神经元可以更好的对数据分布情况进行学习。
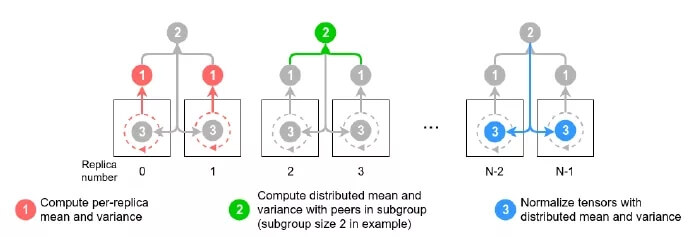
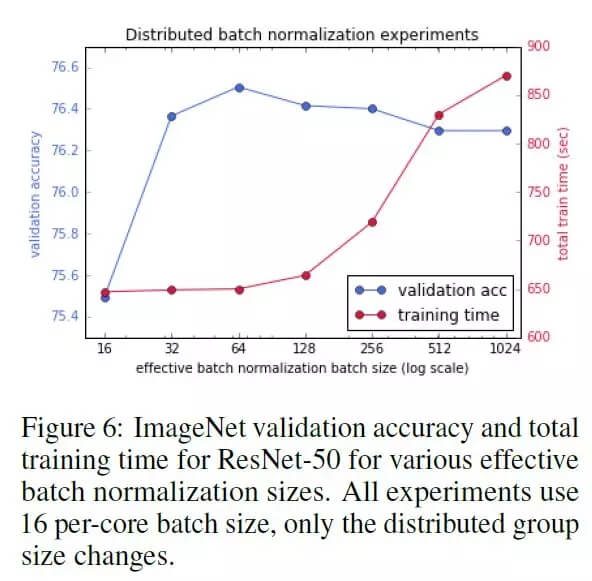
在分布式训练过程中,通常让每个计算节点独立的进行 batch norm, 这样的好处是可以大大缩短训练时间,因为每个计算节点之间无需额外的通信过程。在实验过程中,作者发现 BN 的批大小(例如计算节点的批大小)对模型的验证准确率有重要影响。已经有研究证明在计算节点的批大小小于 32 时,ResNet-50 的最终训练结果在验证数据上的准确率并不能收敛。
当使用数据并行的方法在大规模计算机集群上进行部署时,需要同时对全局的 batch size 大小进行扩大,同时对每个节点的局部 batch size 进行缩小。考虑到 BN 层的影响,作者主要针对每个节点上的 batch size 较小的情况进行研究。
作者通过对几个计算节点组成的子节点做分布式的批归一化来实现对 BN 这一过程的增强。具体算法如图所示:
训练模型过程中,输入管道包括了数据读取、数据分析、预处理、旋转和批量化等操作。如果输入管道的吞吐量不能和 TPU 等模型管道(前向或反向传播过程)的吞吐量相匹配,整个过程将会由于输入管道的问题产生吞吐量上的瓶颈。导致输入管道与模型管道吞吐量差异的主要原因是专用硬件加速设备与 CPU 之间的性能差异,因为模型管道是完全在专用硬件加速设备上执行的。
在本文中, 作者使用了很多关键的优化方法来解决输入管道导致的瓶颈。此前,还未有工作对这些技术进行整合。具体方法如下:
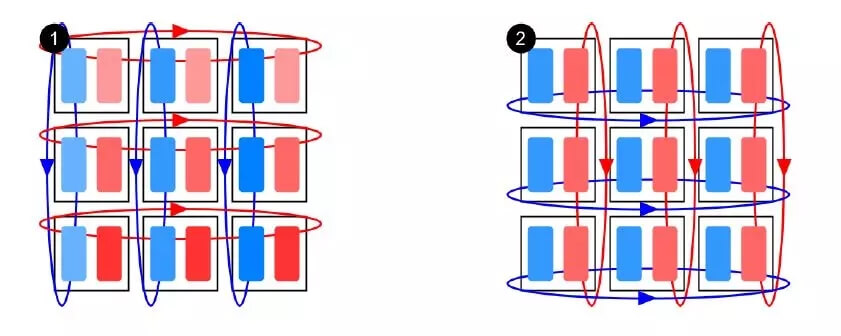
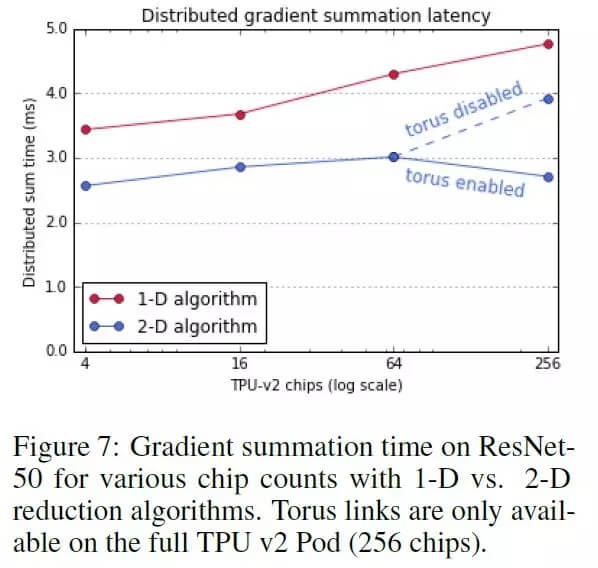
本文的作者提出了一种二维梯度求和方法,用于多个计算节点之间的梯度的计算和传播。在传统的一维方法中,梯度求和这一步的时间复杂度是 O(n^2),使用二维求和后,时间复杂度可以降到 O(n)。具体计算方法如下图所示。
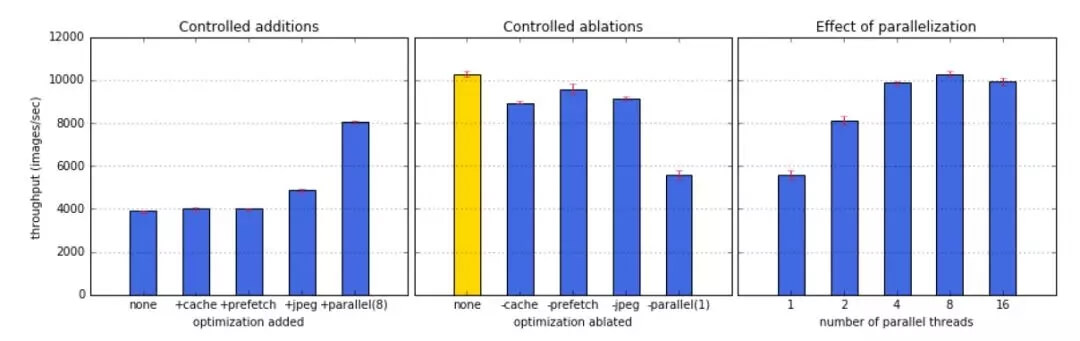
作者进行了多个实验,对文中提到的几个技术细节进行论证。
分布式归一化的结果如下图所示,实验使用了 TPU v2 Pod 进行训练,并且没有使用 LARS 优化。
左图是逐渐增加每种优化方法的实验结果,中间的图是组合优化的结果与逐渐减少其他优化方法的结果对比,右图是并行化数量对实验结果的影响。所有的实验结果都以数据吞吐量为指标。
下图是二维梯度求和算法与一维梯度求和算法的比较,可见使用二维梯度求和在各个配置的情况下都可以有效的减少分布式求和的时间。
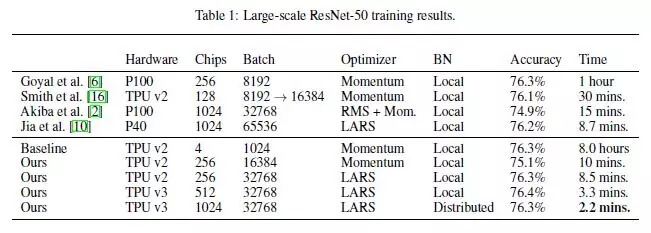
最后,作者与目前最好的分布式计算方法进行了比较,在准确率相同的情况下,本文提出的方法相比之前的方法大大减少了时间消耗。
目前谷歌云已经上线 Cloud TPU v3 测试版,单台设备价格每小时 2.4 美元到 8 美元,也不是很贵,你也可以动手试试看哦~
论文原文链接:https://arxiv.org/pdf/1811.06992v1.pdf

 友情链接
友情链接