








公众号/AI前线
作者|微软 Mark Hamilton 等
编译| 吴少杰
编辑|Debra
AI 前线导读:目前,有很多深度学习框架支持与 Spark 集成,如 Tensorflow on Spark 等。然而,微软开源的 MMLSpark 不仅集成了机器学习框架(CNTK 深度学习计算框架、LightGBM 机器学习框架),还可以将这些计算资源作为一种服务,以 HTTP 服务的形式对外提供给用户。近日,微软 MMLSpark 团队发表了一篇论文对 MMLSpark 的架构进行详细解读,我们将基于这篇论文,就 MMLSpark 的相关组件的特性和一个利用 MMLSpark 进行物体识别的案例展开介绍。本文是 AI 前线第 55 篇论文导读。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
微软开源 MMLSpark 机器学习生态系统,旨在扩展 Apache Spark 分布式计算库,以解决深度学习、微服务编排、梯度提升、模型可解释性等现代计算领域的问题。

微软针对 Spark 生态系统,做了以下三个主要的贡献:
(1)将机器学习组件 CNTK、LightGBM 和 Spark 统一;
(2)集成了 Azure 云端的 Cognitive Services 和实现了 Spark 的 HTTP 服务;
(3)部署所有的 Spark 计算,作为一种分布式的 web 服务。
借助微软的 Cognitive Toolkit(CNTK) 深度学习框架,可以在 Spark 上做 GPU 加速。CNTK 是类似 Tensorflow、PyTorch、MxNet 的深度学习框架,可以帮助工程师和研究员解决各种机器学习问题,还可以编写一些 GPU 加速代码。为了让 Spark 用户可以调用和训练 CNTK 模型,我们在基于 C++ 语言实现的 CNTK 前提下,对 CNTK 进行了简单的包装和接口的生成,提供了 Java 的绑定。这样使 Java,Scala 和其他基于 JVM 语言的用户对 CNTK 的可操作性大大增强。同时,我们还为 Spark transformers 自动生成了 PySpark、SparklyR 的绑定。在广播模型方面,我们用 Bit-Torrent 对其进行优化,重新使用 C++ 对象,减少垃圾回收开销,异步处理 mimi-batch 数据、本地线程共享权重,以减少内存溢出的问题。同时借助微软内部的预训练模型、工具,可以做很多图像方面的工作,包括野生动物识别、生物医疗实体抽取、加油站的火灾探测。
我们将微软开源的梯度提升算法库 LightGBM 集成到 Spark 里。LightGBM 是一种现在非常流行且优秀的决策树算法框架。LightGBM on Spark 基于 Message Passing Interface(MPI)进行通讯,其通讯次数要比 Spark ML 自带的梯度提升算法库少很多,因此 LightGBM on Spark 比 Spark ML 的 GradientBoosted Tree 训练速度快将近 30% 。LightGBM 在训练过程中,worker 之间需要通讯,为了统一 Spark 的 API,我们将控制转移到 Spark 的“MapPartitions”,更具体的说,是通过 driver 节点发送 MPI 指令,worker 节点之间进行通讯来实现的。Spark 和 LightGBM 的集成可以让用户很方便地创建各种分类、回归任务。
除了通过转换控制将框架集成到 Spark 中,我们还扩展了 SparkML 的本地算法库,其中一个例子就是 Local Interpretable Model Agnostic Explanations (LIME) 的分布式实现。同时 LIME 提供了一种”解释“方式,这种方式可以在不参考任何模型函数的情况下来解释任何模型的预测结果。更具体的说,LIME 通过一个抽样过程构造了一个局部线性近似的算法,从而解释了黑盒子函数。
以图像分类为例,局部遮挡会影响模型的最终输出,那么则说明遮挡的这一部分对分类结果非常关键。更正式地说,通过将图像随机块或将”超级像素“设置为中性颜色来创造大量扰动的图像,然后,将这些扰动的图像灌注给模型,从而观察其如何影响模型的输出。 最后,使用局部加权 Lasso 模型来学习超像素“状态”的布尔向量与模型输出结果之间的映射关系。
为了解释图像分类器进行图像分类的过程,我们需要对成千上万的扰动图像进行抽样分析。更实际的说,如果你的建模需要花费一个小时,那么使用 LIME 计算来解释你的模型则需要大约 50 天。现在我们已经在 Spark 上实现了 LIME 的分布式计算,另外我们还选择了一种并行化的方案来加速每个单独的解释,这可以说大大减少了计算时间。之后,我们对输入图像进行超像素分解并将其并行化,然后,迭代这一过程从而为每一个输入图像创造一个新的并行化的“状态样本”集合。最后,我们将一个分布式线性模型拟合到一个内部集合,并将其权重添加到与原始并行的集合中。由于这种与以往不同的并行化方案,使这一集成过程可以完全受益于快速编译的 Scala 和 Spark SQL, 而不是像工具 Py4J 那样把现有的 LIME 代码集成到 Spark 中。
通过 Java Native Interface (JNI) 和函数的 dispatch,将 CNTK、LightGBM 等机器学习组件和 Spark 统一起来。考虑到涉及不同的系统,编写这样的代码非常繁琐、复杂。现在,我们借助微软内部开发的类似 HTTP 一样的协议来解决这个问题,可以将 HTTP 的 Request 和 Response 转换为 Spark SQL 类型,这样用户可以使用 Spark SQL 的 map、reduce 等算子来处理 HTTP 的请求和回应。微软的 Cognitive Services、Kubernete 都可以用这种方式来与 Spark 进行集成,这样可以借助外部的智能服务,让 Spark 的计算更智能。 每一个 Congnitive Service 就是一个 SparkML 的转换,用户可以添加智能计算服务到自己的 SparkML 工作流中。另外,将每个请求的参数作为 dataframe 中的一列做分布式处理,对于处理大量的请求非常有帮助。
MMLSpark 集成了 Spark Serving,Spark Serving 可以像调用 Web 服务那样使用 Spark 的计算资源。Spark Serving 建立在 Spark Structured Streaming 之上,可以通过 Spark SQL 编写相关任务的计算逻辑,然后执行 Streaming 的查询。Spark Serving 作为 Structured Streaming 的一种扩展,是一项特殊的 Streaming 任务。这种 Web 服务更像是一种 Streaming 的 pipeline:首先通过 HTTP 请求原数据,然后处理数据结果从而对外提供 HTTP 服务。 Spark Serving 可以部署 Spark 上的任何资源,包括如:CNTK、LightGBM、SparkML、Cognitive Services、HTTP Services 等。这样可以让开发者不需要导出训练模型,再花费时间使用其他语言编写对外提供的模型服务接口,对开发者而言十分有效。
目前,MMLSpark 支持大部分机器学习领域的常见问题,包括:文本、图像、语音。最近,我们的研究者在无标注的情况下,利用微软 Bing 的图像搜索功能和 MMLSpark 的图像识别功能,完成了拍摄照片中雪豹的物体识别工作,从而为保护野生动物(雪豹)提供了一个方案。
下面以雪豹物体识别的例子, 来解释具体如何使用 MMLSpark:
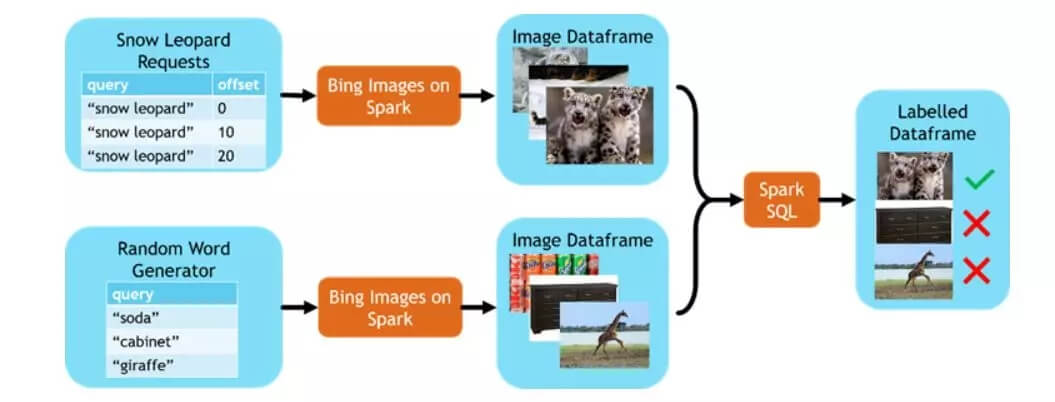
整体架构图
机器学习中最困难的部分是收集数据。传统的办法是人工标记,人工标记数据耗费大量的时间和精力。没有高质量的标记数据集,算法模型在实际应用项目中很难落地。现在,通过微软的 Bing 图片搜索结果可以辅助我们标记大量的数据集,这样就解决了人工标记耗时耗力的问题。Bing 图片搜索已经和 Spark 集成到一起了。
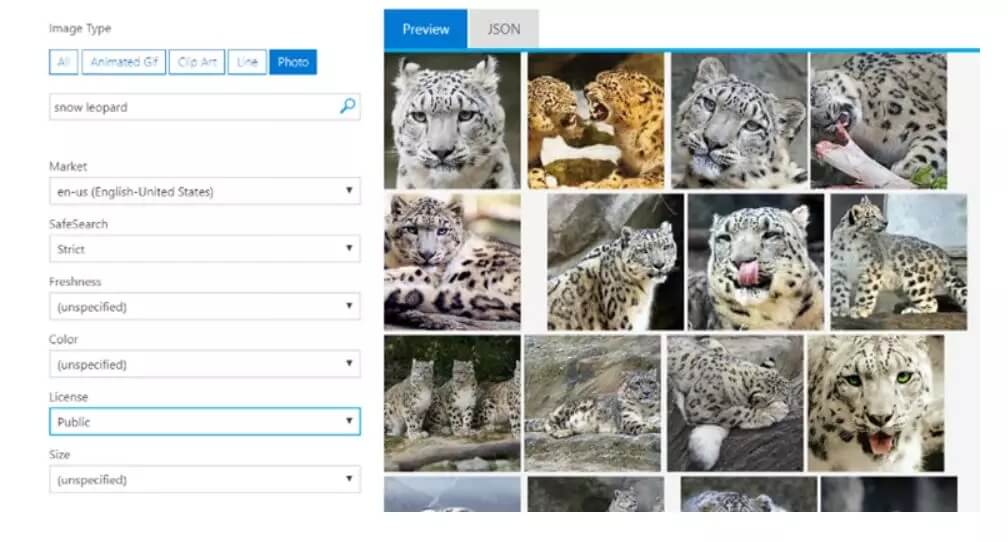
雪豹在微软 Bing 图片搜索的结果
基于 Bing 图片搜索结果的数据集,可以在 Spark 上创建各种应用。以收集雪豹数据集为例,只需要两个 Spark 查询就可以完成数据集收集,其中一个查询收集正样本(雪豹相关的图片),另外一个查询收集负样本(随机图片)。然后,将结果数据集拉取到 Spark 集群,通过 Spark SQL 做预处理,比如:添加标签、删除重复数据等。Spark 在 Azure 集群上并行处理,只需要花费几秒钟的时间就可以通过 Bing 搜索获取到世界各地的上千张图片。然后,通过 MMLSpark 的 OpenCV on Spark 对图片进行快速处理。
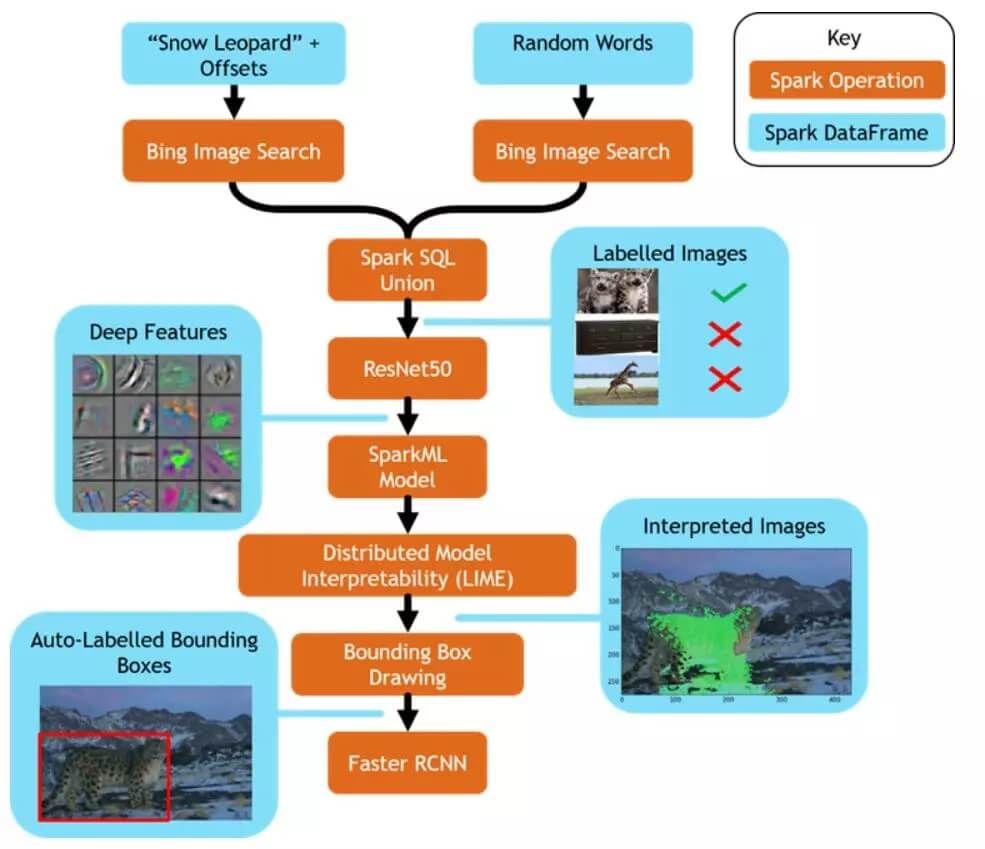
上一步,数据集已经创建完成。下面开始构建模型,卷积神经网络(CNN)是图像处理中比较流行的深度学习网络模型。为了构建深度神经网络,可以借助 MMLSpark 上的 Cognitive Service on Spak(CNTK 深度学习工具)。迁移学习是目前比较流行的解决新任务的技术,MMLSpark 上做迁移学习任务非常容易。现在,对于雪豹物体识别的新任务,你不需要从零开始构建一个全新的网络结构,只需要借助微软预先训练好的模型和借助迁移学习技术就可以解决这一问题。这个物体识别过程非常像人的思考过程是基于历史的记忆,来学习、判断、和识别新事物。通过残差网络在数百万图片上训练的通用深度网络模型,我们现在可以拿来使用,只需要剪切最后几层网路结构并且使用 Spark ML 中的 LR(逻辑回归)做替换,构成新的网路结构。也就是说,将前面几层网络输出的雪豹图片特征,输入到逻辑回归,最后输出的结果是雪豹的概率值。
此外,我们还可以借助 LightGBM on Spark ,在图片预处理方面做一些改进,比如:图像增强、数据不平衡处理等操作,以提高最后识别的精确度。
上一步,我们做了图片分类,得到这个图片是雪豹的概率多大。但是,在实际应用中,我们更期望能得到雪豹在图片中的具体位置,以便了解野外还有多少只雪豹。雪豹的数量,对于保护雪豹至关重要。在 Bing 图片搜索中,并没有给出雪豹的位置边框。在物体识别中,识别的物体需要用边框框起来。传统的办法是人工来标注,非常费力。根据上面介绍的 LIME 原理,现在,我们可以通过 LIME 的方法,给要识别的物体标记上边框。

如上图,我们可以通过 LIME 的方法,解释雪豹在图片中位置的特征对雪豹分类器非常重要,那么我们就认为这个图片的这部分就是雪豹所在的图片位置,然后,我们用矩形边框将其框住。这样办法,可以帮助我们快速建立非常丰富的带边框的物体识别数据集。
LIME 计算会耗费大量的计算资源,现在 MMLSpark 已经将 LIME 集成到 Spark 中,这样可以借助 Spark 强大的分布式计算资源,解决单机版本的计算瓶颈。
我们利用 Bing 图片搜索结果,迁移学习技术和 LIME 方法,快速完成了非常复杂,非常耗时、耗精力的工作。下面我们开始使用 COCO(微软开源的物体识别数据集)数据集预训练的模型,结合迁移学习技术,构建新的网路结构,并进行模型训练。
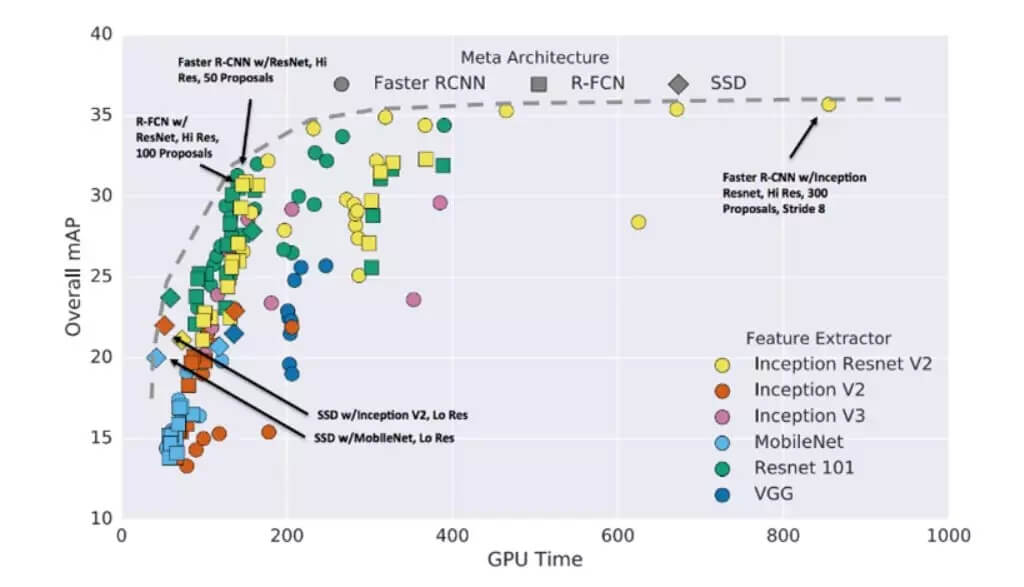
经过对比,我们最后选用了 Faster R-CNN 网络和 Inception Resnet v2 网络,它们结合起来,在准确率、性能、速度方面目前是最优的。从最后识别结果来看,跟人类标记非常接近。如下图所示:

在检测过程中,我们也发现了一些问题,比如下图中:1、图片中真实的雪豹是两只,我们的算法仅仅识别到一只;2、有些雪豹隐蔽性很强,我们的算法没有识别出来。

造成上面结果的主要原因是:1、在使用 LIME 进行边框标记是,仅仅标记了一个边框;2、收集数据集的时候,Bing 图片搜索中存在一些偏见,比如:Bing 返回的图片结果都是高清的。
为了减少这些问题对结果的影响,我们可以通过下面的办法来克服:1、使用 LIME 方法,标记物体框的时候,对超高像素区域进行聚类算法,以识别帧是否存在多个识别对象,再添加标记边框;2、在使用 Bing 搜索结果,收集数据数据集的时候,尽量通过随机结果,多轮挖掘更多的正负样本。
MMLSpark 将 Web Serving 组件集成到 Spark 中,可以将上面训练好的模型部署到生产环境上,给用户提供实时的查询服务。在 MMLSpark v0.14 的版本上,延迟减少了近 100 倍,现在可以在 1 毫秒内返回查询的相应结果,可以为世界各地的用户提供查询服务。
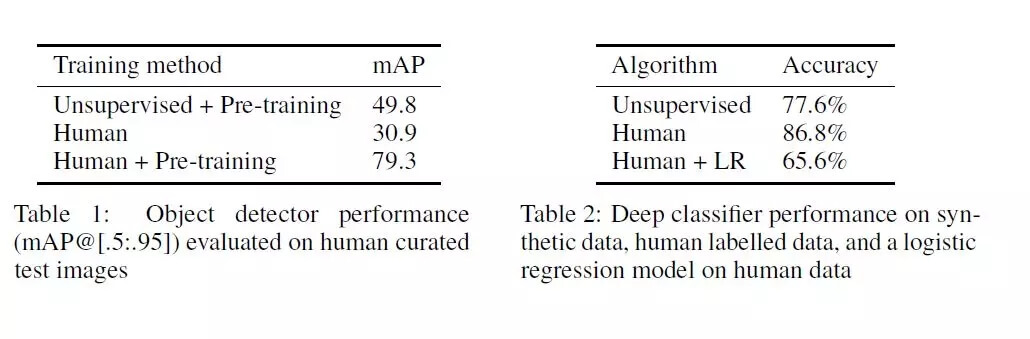
我们发现大多数的图像我们完全无监督的目标检测器绘制的边界框非常接近人类绘制的水平。下图表 1 和表 2 表明,我们的方法可以逼近人类的分类效果和人类的物体识别能力。在物体检测方面,无监督 + 预训练模型的 mAP 值达到 49.8,超过了人类的 30.9,小于人类 + 预训练模型的 mAP 值 79.3。图像分类方面,无监督的精确率为 77.6%,比人类的 86.8% 低,但是,高于人类 +LR(逻辑回归) 的精确率 65.6%。
MMLSpark 提供获取数据源的途径(Bing on Spark),整合数据预处理 (Spark SQL)、模型训练(CNTK on Spark),模型输出对外提供服务(Spark Serving)等过程,仅仅通过很少量的代码开发工作就可以完成非常复杂的应用。
我们总结一下常规的搭建一个应用的步骤:
2、训练深度学习模型,使用 CNTK on Spark;
3、解释分类模型,获取感兴趣的区域,标注数据框,借助 LIME on Spark;
4、借助迁移学习技术,结合 LIME 的输出结果,做物体检测;
5、部署模型,对外给用户提供服务,使用 Spark Serving.
论文原文链接:
https://arxiv.org/pdf/1810.08744.pdf
应用案例链接:
https://blogs.technet.microsoft.com/machinelearning/2018/10/03/deep-learning-without-labels/

 友情链接
友情链接