








公众号/AI前线
策划编辑|Natalie
作者|MARAT DUKHAN 等
译者|无明
编辑|Debra
AI 前线导读:Facebook 正式开源 QNNPACK,一款针对移动 AI 进行优化的高性能内核库。这个库加速了多项操作,包括高级神经网络架构所使用的深度卷积。QNNPACK 已经被集成到 Facebook 应用程序中,并被部署到了数十亿台设备上。在 MobileNetV2 等基准测试中,QNNPACK 在各种手机上的性能表现比之前最好的实现高出 2 倍。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
为了将最新的计算机视觉模型引入移动设备,Facebook 开发了 QNNPACK,一个针对低强度卷积进行优化的函数库。
QNNPACK 是 Quantized Neural Network PACKage 的简写,已经被集成到 Facebook 的一系列应用程序中,并被部署在全球的 10 亿台移动设备上。有了这个新库,Facebook 可以执行高级计算机视觉任务,例如在手机上实时运行 Mask R-CNN 和 DensePose,或者在低配置的移动设备上执行图像分类,所需时间低于 100 毫秒。
Facebook 将 QNNPACK 开源,为量化推理提供全面支持,并作为 PyTorch 1.0 平台的一部分。QNNPACK 已经可以支持 Caffe2 模型表示,此外,Facebook 也正在开发其他实用程序,以便将模型从 PyTorch 的 Python 前端导出成图表示,并在移动平台以外的其他平台上对这些操作进行优化。
由于移动设备的处理能力只有数据中心服务器的十分之一甚至千分之一,因此,要在移动设备上运行人工智能,需要经过多次调整才能充分利用硬件的所有可用性能。QNNPACK 提供了针对量化张量的卷积、反卷积和完全连接操作,具备很高的性能。在 QNNPACK 之前,并不存在针对几种常见神经网络原语(分组卷积、扩张卷积)的高效开源实现,因此,ResNeXt、CondenseNet 和 ShuffleNet 等研究模型未能得到充分利用。
不直接从事科学计算或深度学习的软件工程师可能不熟悉库是如何实现矩阵乘法的,因此,在深入研究 QNNPACK 的细节之前,需要先描述一下矩阵乘法。
在下面的示例中,A 是输入,B 是权重,C 是输出。 B 推理运行期间保持不变,因此可以在没有运行时成本的情况下转换为任意内存布局。
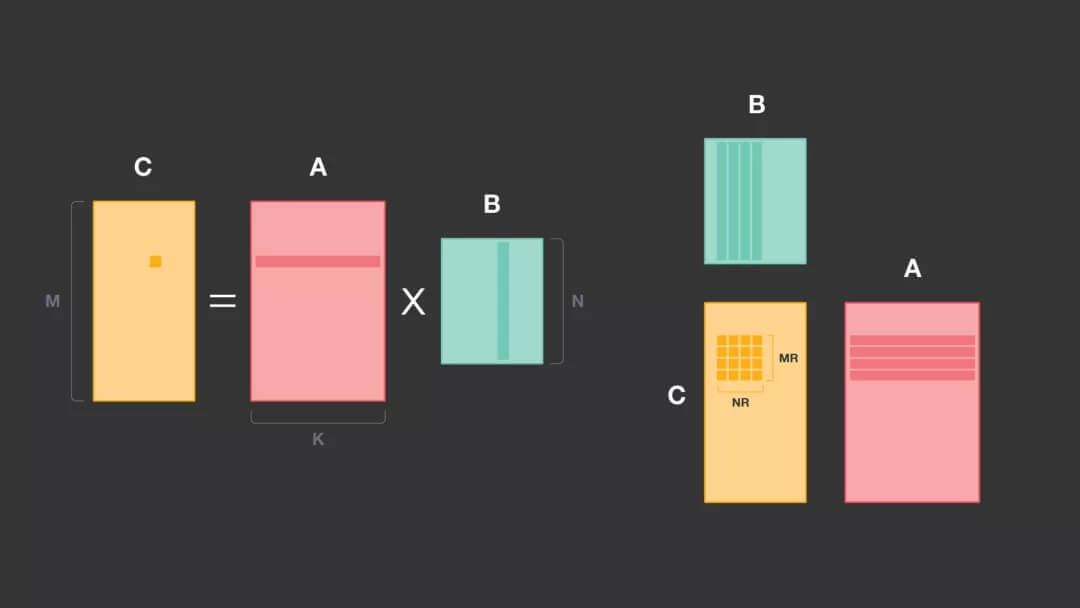
M x K 的矩阵 A 和 K x N 的矩阵 B 之间的乘法将产生 M × N 的矩阵 C。C 中的每个元素可以认为是 A 的相应行和 B 的相应列之间的点积。
Facebook 可以在点积原语之上实现整个矩阵乘法,但是这种实现非常低效。在点积中,他们为每个乘加运算加载两个元素,而在现代处理器上,这种实现会受到内存或缓存带宽的限制,这与乘加单元的计算能力无关。但如果做出略微修改——同时计算 A 的多个行和 B 的多个列的点积——就可以显著提高性能。
修改后的原语加载 A 的 MR 元素和 B 的 NR 元素,然后执行 MR x NR 乘加运算。虽然 MR 和 NR 的最大值受寄存器数量和处理器体系结构的限制,但在大多数现代系统中,它们提供了足够大的空间,并且所有的高性能矩阵乘法实现都是建立在这个原语(通常称为 PDOT 微内核,即面板点积)之上。
QNNPACK 使用与 Android 神经网络 API 兼容的线性量化方案。它假定量化值 q[i] 表示为 8 位无符号整数,并与实值表示 r[i] 有如下的关系:
r[i] = scale * (q[i] – zero_point)其中 scale 是正浮点数,而 zero_point 是无符号 8 位整数,与 q[i] 一样。
虽然 QNNPACK 利用了 PDOT 微内核,就像其他 BLAS 库一样,但它更专注于具有 8 位元素的量化张量,并且移动 AI 用例为性能优化带来了截然不同的视角。大多数 BLAS 库针对科学计算用例,其矩阵可以大到包含数千个双精度浮点元素,但 QNNPACK 的输入矩阵源于低精度、特定于移动设备的计算机视觉模型,并且具有非常不同的维度。在 1×1 卷积中,K 是输入通道的数量,N 是输出通道的数量,M 是图像中的像素数量。在实际的移动优化网络中,K 和 N 不大于 1,024,通常在 32-256 之间。
移动架构的限制要求 MR 和 NR 不超过 8。因此,即使是在具有 1,024 个通道的大型模型中,PDOT 微内核读取的内存块最多为 16KB,即使是超低配置的设备也能把它塞进 L1 缓存。这是 QNNPACK 与其他 GEMM 实现之间的重要区别:其他库重新打包 A 和 B 矩阵,以便更好地利用缓存层次结构,希望在大量计算中分摊打包开销,而 QNNPACK 针对 A 和 B 可以塞进 L1 缓存进行了优化。因此,它移除了对于计算来说不是绝对必要的内存转换。
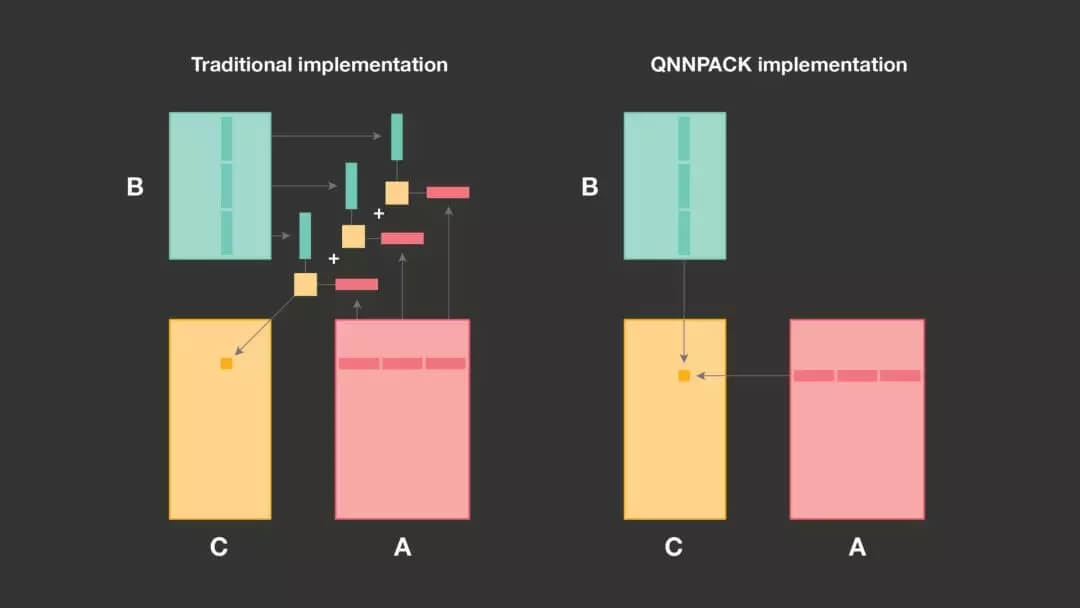
在量化矩阵乘法中,8 位整数的乘积通常被累加到 32 位中间结果中,然后重新量化以产生 8 位输出。传统的实现主要针对大矩阵进行优化,因为 K 可能太大,导致无法将 A 和 B 放入缓存。为了有效利用缓存层次结构,传统的 GEMM 实现将 A 和 B 沿着 K 维分割成固定大小的子面板,因此每个面板都可以塞进 L1 缓存。这种缓存优化要求 PDOT 微内核输出 32 位中间结果,最终将它们相加并重新量化为 8 位整数。
由于 QNNPACK 针对移动网络进行了优化,A 和 B 面板始终可以塞进 L1 缓存,因此可以在一个微内核调用中处理 A 和 B 面板。由于无需在微内核之外累积 32 位中间结果,QNNPACK 将 32 位中间结果的重新量化融合到微内核中,并输出 8 位值,从而节省了内存带宽和缓存占用空间。
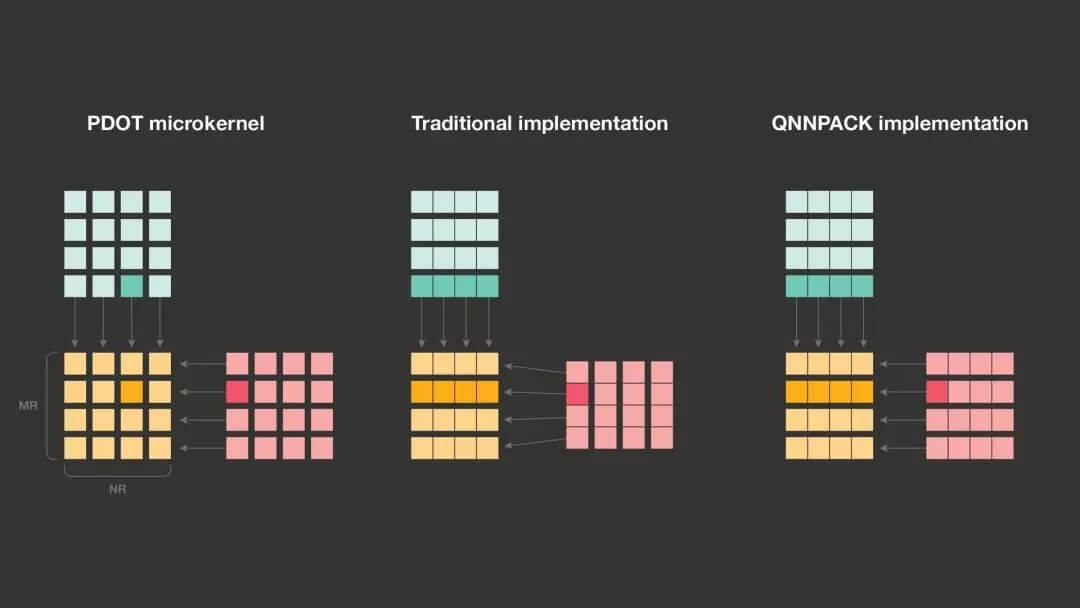
因为可以将 A 和 B 的整个面板塞入到缓存中,所以可以在 QNNPACK 中进行另一个优化:避免矩阵 A 的重打包。与包含了静态权重,并且可以一次性转换为任意内存布局的矩阵 B 不同,矩阵 A 包含了卷积输入,每次推理都会发生变化。因此,每次重打包矩阵 A 都会产生额外的开销。传统的 GEMM 之所以要重打包矩阵 A 主要基于两个原因:有限的缓存关联性和微内核效率。在没有重打包的情况下,微内核必须基于可能很大的步幅读取 A 的行。如果步幅恰好是 2 的次幂,来自 A 不同行的元素可能会落入相同的缓存中。如果这种冲突数量超过了缓存关联性,性能就会急剧下降。幸运的是,当面板可以塞入 L1 时,这种情况就不会发生。
打包对微内核效率的影响与 SIMD 矢量指令的使用密切相关。这些指令加载、存储或计算固定大小的元素向量,而不是单个标量。关键是要充分利用向量指令来提升矩阵乘法的性能。在传统的 GEMM 实现中,微内核将重打包的 MR 元素加载到向量寄存器的 MR 通道中。而在 QNNPACK 实现中,MR 元素在内存中不连续,微内核必须将它们加载到不同的向量寄存器中。寄存器压力的增加迫使 QNNPACK 使用更小的 MRxNR,但差异其实很小,而且可以通过消除打包开销来弥补。例如,在 32 位 ARM 架构上,QNNPACK 使用 4×8 微内核,其中 57%的向量指令是乘加。另一方面,gemmlowp 库使用稍微高效的 4×12 微内核,其中 60%的向量指令是乘加。
微内核加载 A 的几个行,乘以 B 的几个列,然后累加结果,最后执行重新量化并输出量化的和。A 和 B 的元素被量化为 8 位整数,但乘法结果被累加到 32 位。大多数 ARM 和 ARM64 处理器没有直接执行这种操作的指令,因此必须将其分解为多个操作。QNNPACK 提供了两个版本的微内核,它们的区别在于指令序列上,这些指令序列用于 8 位值相乘以及将它们累加到 32 位结果。
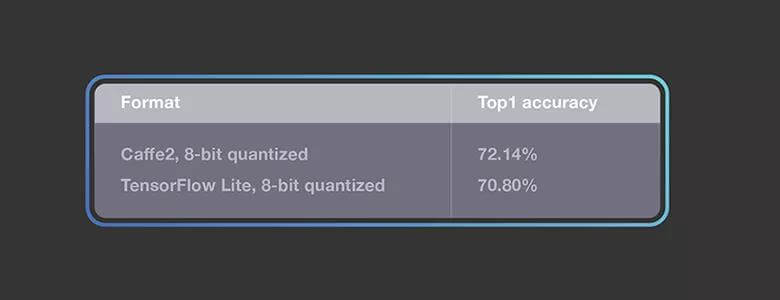
Facebook 的测试表明,QNNPACK 在端到端基准测试中具备一定的性能优势。在量化 MobileNet v2 架构中,基于 QNNPACK 的 Caffe2 运算在各种手机上的速度比 TensorFlow Lite 快约 2 倍。Facebook 同时还开源了 Caffe2 量化 MobileNet v2 模型(https://github.com/caffe2/models/tree/master/mobilenet_v2_quantized),与相应的 TensorFlow 模型相比,top-1 准确率提高了 1.3%。
MobileNet 架构的第一个版本率先使用深度卷积来让模型更适用于移动设备。MobileNetV1 几乎完全由 1×1 卷积和 3×3 深度卷积组成。Facebook 从 TensorFlow Lite 转换了量化 MobileNetV1 模型,并在 TensorFlow Lite 和 QNNPACK 的 32 位 ARM 版本上进行了基准测试。两个运行时都使用了 4 个线程,Facebook 发现,QNNPACK 比 TensorFlow Lite 快了 1.8 倍。

作为移动视觉任务最先进的架构之一,MobileNetV2 引入了瓶颈构建块,以及瓶颈之间的快捷连接。Facebook 基于 MobileNetV2 分类模型对 QNNPACK 的 Caffe2 操作进行了基准测试,并与 TensorFlow Lite 实现进行对比。Facebook 发布了量化 Caffe2 MobileNetV2 模型(https://github.com/caffe2/models/tree/master/mobilenet_v2_quantized),并使用了官方存储库中的量化 TensorFlow Lite 模型(https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/g3doc/models.md)。下图显示了常用的测试数据集的 top1 准确率:
Facebook 在各种手机上通过 Facebook AI 性能评估平台进行了基准测试。对于 TensorFlow Lite 的线程设置,Facebook 尝试了一到四个线程,并报告了最快的结果。Facebook 发现,在这些手机上使用四个线程时,TensorFlow Lite 表现最佳,因此 Facebook 在 TensorFlow Lite 和 QNNPACK 的基准测试中使用了四个线程。下图显示了结果,在典型的智能手机和高端手机上,基于 QNNPACK 的操作明显快于 TensorFlow Lite。
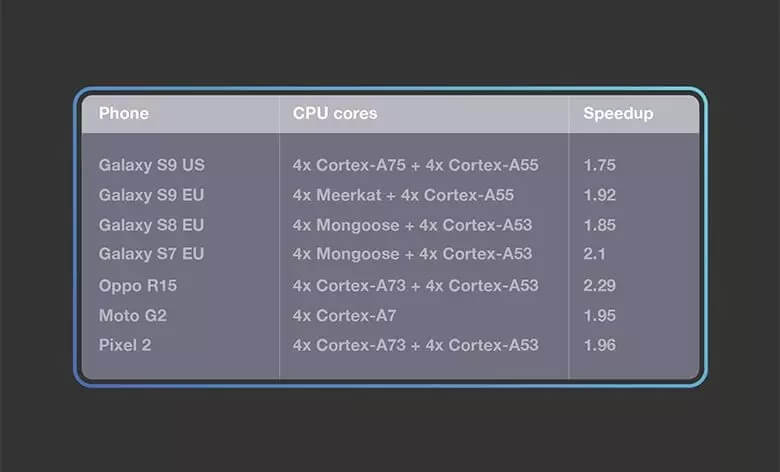
借助 QNNPACK,Facebook 的系列应用程序已经将人工智能部署到全球的移动设备上。Facebook 正在探索 QNNPACK 的新性能增强,包括 FP16 格式的低精度计算,利用 NEON 点积(VDOT)指令和 16 位累积,让 AI 在移动设备上变得更轻量级。Facebook 还期待通过 PyTorch API 公开 QNNPACK 操作支持,并通过扩展为移动开发人员提供工具。Facebook 希望 QNNPACK 能够通过提升模型的移动性能,让 AI 研究人员和开发人员从中受益。
英文原文:https://code.fb.com/ml-applications/qnnpack/

 友情链接
友情链接