








大数据文摘出品
编译:张秋玥、M、浩哥儿、睡不着的iris、钱天培
近年来,机器在自然语言领域屡屡战胜人类的报道层出不穷。
机器能够像人类一样阅读文档并回答问题,确定某一给定的语句是否在语义上蕴含另一给定的语句,还能处理翻译任务。更重要的是,机器的表现甚至优于人类。
如此一来,我们理应得出这样的结论:如果机器能够胜任所有这样的任务,那么他们一定具备真正的语言理解与推理能力。
然而,事实并非如此。大量最新研究表明,这些先进的模型其实异常脆弱。
比如,在不改变原意的情况下修改文本时,模型就会出现各种错误。
例如~
jia与Liang发现了BiDAF阅读理解模型存在的问题。

上图来自Jia与Liang。在阅读理解任务中,“精确度”的准确含义可在脚注2查阅。
Belinkov与Bisk发现了基于字符的神经机器翻译模型存在的问题。

上图来自Belinkov与Bisk。BLEU是一个常用评估方法,对文本的候选翻译与一或多段参考翻译做比较,得出分数。
Iyyler与其合作者发现了树形结构双向LSTM情感分类模型存在的问题。
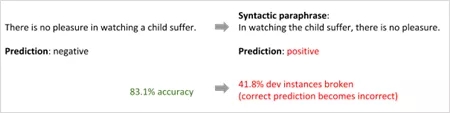
上图来自Iyyler与其合作者
他们经常会记住人为现象与偏差,并不真正进行学习。
Gururangan及其合作者发现,在没有观察前提的情况下,模型就能够为基准数据集内超过50%的自然语言推论样本进行准确分类。
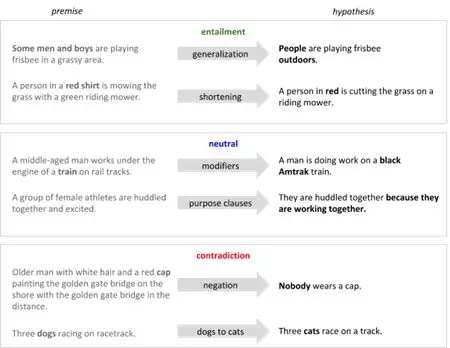
上图来自Gururangan等人在论文中展示的例子。
Moosavi与Strube的研究表明,解决共指解析(coreference resolution)任务的深度指代(deep-coref)模型总是将带有“country”一词的专有名词或普通名词与训练集数据中的国家名称联系到一起。
因此,在训练集数据未提到的国家名称的自然语言片段上,模型的表现就很糟糕。同时,Levy与其合作者在研究用于识别两个单词间词汇推理关系的模型,例如,上下位关系。
译者注:上下位关系是语言学概念。概括性较强的单词叫做特定性较强的单词的上位词,特定性较强的单词叫做概括性较强的单词的下位词。例如,猩红色、鲜红色、胭脂红、绯红色都是“红色”的下位词,而红色则是猩红色的上位词。
他们发现模型不是学习词汇间的关系特征,而是学习某个词汇的独立属性:这个词是否为“典型的上位词”,例如,“动物”一词。

左图:来自Moosavi与Strube;右图:来自Levy及其合作者。
Agrawal及其合作者的研究表明,基于CNN与LSTEM模型的视觉问答模型经常在只“读到”问题的一半就收敛于一个预测出的答案。这意味着模型严重依赖于训练数据的表面相关性,缺乏组合性——回答关于已知概念以未知方式组合出的问题的能力。

上图来自Agrawal等
尽管现代NLP技术在基准数据集上表现优良,但对于未知自然语言文本的语言理解与推理方面远不及人类的水平。这些见解促使Yonatan Bisk,Omer Levy与Mark Yatskar决定组织一场NAACL研讨会来讨论处于机器学习核心地位的泛化问题。研讨会主要讨论两大问题:
1.如何充分衡量模型在新的、从未见过的输入数据上的表现?或者说,如何衡量系统的泛化能力?
2.如何修改模型使其具备更好的泛化能力?
这些都是极其困难的问题,一天的研讨会明显不能够解决他们。然而,在这场研讨会中,自然语言处理大神们提出了许多值得注意的方法与观点。具体来说,这场大讨论可被概括成三个主题:巧妙利用归纳偏置,向NLP模型灌输常识,以及在未见过的分布与任务上进行研究。
归纳偏置是被用于学习从输入数据到输出数据的映射函数的一系列假设。对于其到底应当被减少还是增加的讨论从未休止。
例如,就在去年Yann LeCun与Christopher Manning进行了一场大辩论,讨论在深度学习架构中应当引入什么样的固有先验(innate priors)。
Manning认为,引入结构性偏好,系统可以从更少的数据获得更多的知识,有助于进行高阶推理;而LeCun则认为“结构是必要的魔鬼”,它使我们不得不做出一些限制性的假设,这些假设对部分数据是错误的,也可能是过时的。
LeCun的观点(减少归纳偏置)有一条很有利的论据:使用语言学偏好的现代模型,在许多基准任务上无法获得最佳结果。
然而,NLP界广泛支持Manning的观点;在ACL2017上,一项值得关注的趋势是在神经结构中引入语言学结构。既然这样,语言结构在实操中达不到预想的效果,我们可以得出这样的结论:一个好的模型需要以新的方式改善归纳偏置。以Manning的话来说就是:
我们应当引入更多的归纳偏置。我们对如何引入该偏置一无所知,因此我们扩充数据集并创建伪训练数据来表现该偏差。这种方法感觉很奇怪啊。
这个问题被Yejin Choi在NLG问题(Natural Language Generation,自然语言生成。)领域研究了这一问题。她展示了一个通用语言模型生成评论的例子。该例使用一项带有定向搜索解码器的门控RNN模型。模型通过训练得出概率最大(正确预测)的下一个词(token)。
自然语言输入:
“总而言之,我向所有希望交通方便的人强烈推荐这家酒店。”
重复,矛盾且平淡的非自然输出:
“总而言之,我向所有希望交通方便,且希望交通方便的人强烈推荐这家酒店。如果你希望交通方便,这里不适合你。然而,如果你想交通便利,你就该选择这里。”
她认为,现今的语言模型正在生成不自然的语言,因为它们是:
1.被动的学习者。尽管它们学习输入数据然后生成输出数据,但与人类学习者不同,它们并不思考它们生成的结果是否符合语言学要求(比如相关性,文风,重复性以及隐藏含义)。换句话说,他们不“练习”写作。
2. 肤浅的学习者。他们不关心事实、实体、事件或活动之间更高层次的关系,然而对于人类来说这恰恰是理解语言的关键所在。他们对我们的世界一无所知。
如果我们鼓励他们使用特定的损失函数以数据驱动的方式学习语言特征,例如相关性,风格,重复和蕴涵,那么语言模型可以“练习”写作。 相比使用自然语言理解(NLU)工具的输出,这种方法更优,因为NLU一般仅用于处理自然语言,无法理解机器语言是否不自然,例如在上例中重复,矛盾、平淡无奇的文字。
因为NLU不理解机器语言,所以使用NLU工具生成的文本以教NLG判断什么样的文本不自然、并根据这种理解行事是没有意义的。总之,我们应该改进学习这些偏置的数据驱动方法,而不是开发引入结构偏置的新神经架构。
NLG并不是我们寻求更好地优化学习器的唯一NLP任务。 在机器翻译中,我们优化中的一个严重问题是机器翻译模型的训练,我们使用诸如交叉熵或预期句子级别BLEU之类的损失函数训练模型。这些函数已经被证明存在偏好,而且与人类判断不充分相关。只要我们使用这种简单的度量标准训练我们的模型,预测结果与人类对文本的判断就会出现不匹配。 鉴于目标比较复杂,强化学习似乎是NLP的一个完美选择,因为它允许模型在模拟环境中通过反复试验来学习类似人类的监督信号(“奖励”)。
Wang和其合作者提出了一种用于视觉叙事的训练方法(描述图像或视频的内容)。 首先,他们研究了已经提出的训练方法,这些方法利用强化学习直接在不可微分的度量上训练图像字幕系统,例如在测试时使用的METEOR,BLEU或CIDEr等度量。王和其合作者表示,如果METEOR得分被用作采用策略的奖励,则METEOR得分会显着提高,但其他得分则受到严重影响。他们展示了一个平均METEOR得分高达40.2的例子:
We had a great time to have a lot of the. They were to be a of the. They were to be in the. The and it were to be the. The, and it were to be the.
相反,当使用其他一些指标(BLEU或CIDEr)来评估故事时,情况恰恰相反:许多相关且连贯的故事得分非常低(几乎为零)。机器正在戏谑这些指标。
因此,作者提出了一种新的训练方法,旨在从人类注释的故事和抽样预测中获得类似人类的奖励。 然而,深度强化学习是脆弱的,并且比有监督的深度学习,它的样本复杂度更高。一个真正的解决方案可能是“人在其中”的机器学习算法,即在学习过程中需要人工介入。
虽然“常识”对人类来说很常见,但很难教给机器。为什么进行对话,回复电子邮件或总结文档等任务这么难呢?
这些任务缺乏输入和输出之间的一对一的映射,需要机器具备抽象能力、认知能力和推理能力,并掌握人类世界有最广泛的知识。换句话说,只要模式匹配(大多数现代NLP)没有人类常识的概念,即所有人类都应该知道的关于世界的事实,就不可能解决这些问题。
Choi用一个简单而有效的新闻标题说明了“芝士汉堡刺伤事件”(Cheeseburger stabbing)来说明了这一点。
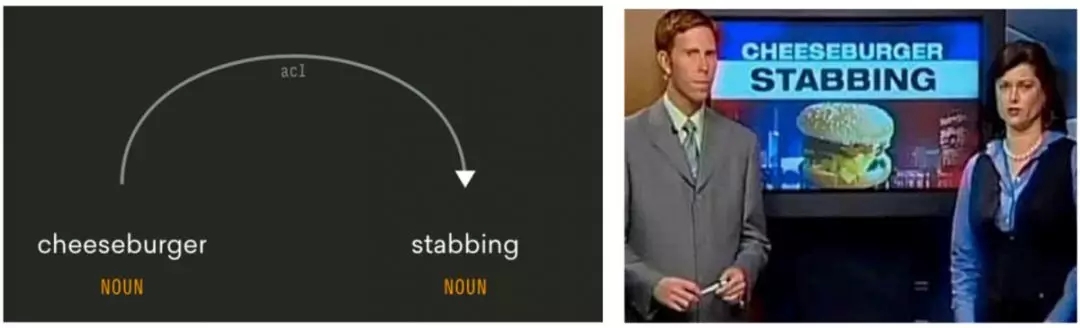
只知道“刺伤” (stabbing)与依存名词“芝士汉堡”(cheeseburger)的主要acl关系(acl relation),不足以理解“芝士汉堡刺”的真正含义。 这幅图片来自Choi的演讲。
关于这个标题,机器可能会问的合理问题是:
有人因为一个芝士汉堡刺伤了其他人?
有人刺了一个芝士汉堡?
一个芝士汉堡刺伤了某人?
芝士汉堡刺了另一个芝士汉堡?
如果机器有社会和物理常识,他们不会问那些你无法想象的荒谬问题。社会常识可以提醒机器,第一种选择是合理的,因为刺伤某人是坏事,有新闻价值,而刺伤芝士汉堡则不然。物理常识表明第三和第四种选择是不可能的,因为芝士汉堡不能用来刺伤任何东西。
除了整合常识知识外,Choi还建议将“通过标签理解”(专注于“所说的内容”)改为“通过模拟理解”。这模拟了文本隐含的因果效应,不仅关注“说了什么”,还应该关注 “没说但是暗示了什么”。 Bosselut及其同事展示了一个例子来说明为什么对文本中实体的隐含因果的预测很重要:
根据“将蓝莓添加到松饼混合物中,然后烘烤半小时”的说明,机器必须能够预见到一些必要的事实,例如,蓝莓现在在烤箱中; 他们的“温度”会增加。
Mihaylov和Frank也认识到我们必须通过模拟来帮助机器理解。与许多其他更复杂的替代方案不同,在完形填空式阅读理解任务中,模型用于推断答案的大部分信息来自给定的故事,但仍然需要额外的常识知识来预测答案:马是动物,动物用于被骑,“坐骑”这个词与动物有关。
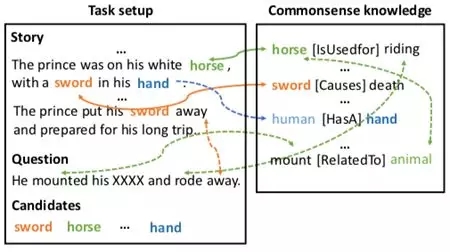
完形填空式的阅读理解案例,需要常识。 来自Mihaylov和Frank。
我们必须承认,现代NLP技术的工作方式就像“没有大脑的嘴巴”,为了改变这一点,我们必须为他们提供常识知识,并教导他们推理表面上没有但隐含的内容。

RNNs是没有大脑的嘴吗?来自Choi所做的演讲的幻灯片。
用监督学习去解决一个问题的标准方法包涵以下几步
1.决定如何标注数据
2.手动标注数据
3.把已经标注的数据分成训练集,测试集和验证集。如果可以的话,通常建议确保训练,测试和验证集均有同样的分布。
4.决定如何表达输入。
5.学习从输入到输出的映射函数。
6.选取合适的度量,在测试集上验证学习效果。
按照这种方法,解决下面的问题,需要标记数据来训练识别单元的模型,同时考虑多种表征和解释(图片,文本,布局,拼写,语音),并将它们放在一起。该模型确定了“最佳”全局解释,并与人们对这个问题的解释相符。
很难被标注的数据示例,图片由Dan Roth提供。
在DanRoth认为:
标准方法不可扩展。我们永远不会有足够的标注数据来训练我们所需任务的所有模型。为了解决上述难题,我们需要带标注的训练数据至少满足于五个不同模块,或者需要大量数据来训练端到端模型。尽管可以使用诸如ImageNet之类的开放资源来解决识别单元之类的任务,但是它仍然不足以让模型意识到在这种语境下单词“world”比单词“globe”更好。即使有人进行了大量的标注工作,数据也必须每天不断同步更新,与流行文化保持同步。
Roth提醒我们注意这样一个事实:存在大量的数据,既独立于给定任务,又有提示作用,通常足以推断出一系列任务的监督信号。这就是附带监督(incidental supervision)想法的由来。
他是这么阐述的。
附带信号(Incidental signals)指的是存在于数据和环境中的微弱信号的集合,与当前的任务相独立。这些信号与目标任务相关联,采用适当的算法,这些信号便可发挥一定的监督作用,并促进学习效果。例如,考虑命名实体(NE)音译的任务 ——基于实体之间的语音相似性将NE从源语言转录到某种目标语言的过程(例如,确定如何用希伯来语表示奥巴马)。已有的时序信号与当前的音译任务相独立。当把它与当前的任务、其他信号和某些推断相关联,便可以发挥监督作用,无需任何大规模的注释工作。
Percy Liang认为,如果训练和测试数据分布一致,“任何具有足够数据的表达模型都可以完成任务。”然而,另一种推断,如果训练和测试数据分布有很大差异——我们实际上必须设计出更“正确的“模型。
在训练和测试时对相同任务进行推断被称作领域自适应(domain adaptation),近年来受到很多关注。
但是附带监督,或者在训练时与测试时对不同的任务推断的情况,并不常见。Li和合作者仅使用给定句子的属性标签训练一个文本属性迁移的模型,而不需要将具有不同属性和相同内容的句子配对的平行语料库。换句话说,他们训练了一个文本属性迁移模型,只需训练为一个能够预测给定句子的属性的分类器。同样的,Selsam和合作者训练了一个解决SAT问题的模型,只需训练一个预测可满足性的分类器。值得注意的是,两种模型都具有强烈的归纳偏置。前者使用的假设是属性通常表现在局部的判别性短语中。后者则捕获了调查传播算法(survey propagation)的归纳偏置。
Percy发表了这样的宣言:
每篇论文,连同其对应的测试集的评估,都应评估新的分布或新任务,因为我们的目标是解决任务,而不是数据集。
当我们使用机器学习时也要像机器学习一样思考,至少在评估时该如此。因为机器学习就像龙卷风一样吸收所有东西,但不关心常识,逻辑推理,语言现象或直观物理。

幻灯片来自 Liang的报告
研讨会与会者想知道我们是否应该要构建用于压力测试的数据集——即测试超出正常运行能力的数据,通常是测试一个突破点,以便观察我们模型真正的泛化能力。
我们有理由相信,只有在解决了更容易的案例之后,模型才有可能解决更难的例子。为知道是否解决了较容易的案例,梁建议我们应该根据难度对案例进行分类。Devi Parikh强调,只有一部分任务或数据集是适用这种情况,即如果你已经解决了较简单的例子,你就可以确定解决难的例子是可能的。那些不在此范围内的任务(如视觉问题回答)不适合此框架。目前尚不清楚哪些模型能够解决哪些图像-问题对(image-question pairs),便能够确定可以解决其他可能更难的图像-问题对。因此,如果我们一开始便让模型去解答“更难”的案例,那么这可能有点危险。
研讨会与会者担心压力测试集可能会减缓进度。什么才是良好的压力测试,可以使我们更好地理解泛化能力,鼓励研究人员构建泛化能力更强的系统,同时不会使得研究人员因为资金减少或研究成果较少而感到压力?对此问题,研讨会没有得出任何结果。
聚焦于深度学习和自然语言处理泛化能力新形式的NAACL研讨会是对现代NLP技术的语言理解和推理能力重新考虑的开始。这一重要讨论将在在ACL-计算语言学协会年会上继续进行。Denis Newman-Griffis报道ACL参与者反复建议我们需要开始考虑更广泛的泛化和无法反映训练数据分布的测试场景,并且Sebastian Ruder反馈NAACL研讨会的主题也在RepL4NLP期间进行了讨论,其中RepL4NLP是颇受欢迎的自然语言处理表征学习的ACL研讨会。
这些事件表明,关于如何修改模型来提高模型的泛化能力,我们并不是毫无头绪。但仍有很大的空间提出新的建议。
我们应该使用更多的归纳偏置,但是我们必须找出最合适的方法,将它们集成到神经架构中,这样才能真正为我们带来预期的改进。
我们必须通过一些类似人类的常识概念来提升先进的模式匹配模型,使他们能够捕捉更高层次的事实,实体,事件或活动之间的关系。但是挖掘这些常识概念是具有挑战性的,因此我们需要更新的、创造性的方法来提取这些常识概念。
最后,我们应该处理那些未曾见过的数据分布和任务,否则“任何具有足够数据的模型都能完成任务。”显然,训练这样的模型更难,效果也不会马上就很好。作为研究人员,我们必须大胆地开发这样的模型,作为审稿人,我们不应该惩罚那些试图这样做的工作。
在NLP领域内的这种讨论反映了人工智能领域内整体上更大的趋势——即反思深度学习的缺陷和优势。在计算机视觉领域,Yuille和Liu写了一篇题为《深度网络:他们到底为计算机视觉做了什么?》 。Gary Marcus一直倡导,在人工智能领域,应该考虑采用深度学习以外的方法。这是一个健康的信号,人工智能研究人员非常清楚地了解深度学习的局限性,并在努力解决这些问题。
相关报道:
https://thegradient.pub/frontiers-of-generalization-in-natural-language-processing/?nsukey=TP2AOdclyXEU0xiC0su1Fq%2BMJL0NWwXC6ywxEz0Jw1PpUobjntE7%2FgCzkpZ7noh86TNwbqGHaNnWio4cd%2BSOFIYtyxUnVGVcIqQvF2y3U8NT9EXAgA7vnf6FiUP2R8mkWGz7OOPk6x1ckQd2nLnXEgRqcC8eIiKIKb5b%2F1XTkBCzBrZjQs6Zw7buHxzVKb6sR%2Bgo40qwxiMbitkXVwoTZA%3D%3D

 友情链接
友情链接