








选自Medium
作者:Zhiting Hu
机器之心编译
参与:刘晓坤、路、邹俏也
Petuum 和 CMU 合作的论文《On Unifying Deep Generative Models》提出深度生成模型的统一框架。该框架在理论上揭示了近来流行的 GAN、VAE(及大量变体),与经典的贝叶斯变分推断算法、wake-sleep 算法之间的内在联系;为广阔的深度生成模型领域提供了一个统一的视角。7 月份在 ICML 2018 的名为「深度生成模型理论基础和应用」的研讨会将更进一步探讨深度生成模型的研究。
近年来,人们对深度生成模型的兴趣开始复苏,并开发出了生成对抗网络(GAN)、变分自编码器(VAE)、自回归网络(例如 pixelRNN、RNN 语言模型)等多种新模型及其变体和扩展,它们在大量应用中展现出了优越的性能。研究者在生成仿真高分辨率的图像、操控和改变文本、学习可解释性数据表征、自动增强数据(用于其它模型的训练)等方面实现了巨大的进步。
今年 7 月份,邢波教授、Ruslan Salakhutdinov、Andrew Wilson 和我将在 ICML 2018 主持一场名为「深度生成模型理论基础和应用」的研讨会。我们很高兴能有机会促进对深度生成模型(DGM)的广泛层面的思想交流,这次研讨会将涉及从理论性质、方法论到实践和现实应用等多个层面。
深度生成模型是一个很活跃的研究领域,有很长的研究历史,并且发展得很快。我对深度生成模型的不同类别之间的理论联系研究很感兴趣。与将这些方法看成区别显著的建模/学习范式的文献不同,本文提出的统一视角可以带来理论和统计上的优势,例如,它可以:
为不同模型的行为提供新的洞察。例如,人们普遍发现 GAN 倾向于生成清晰但多样性较低的图像,而 VAE 则倾向于生成较为模糊的图像。在通用的框架内构建 GAN 和 VAE 模型可以促进它们之间的形式化对比,并且对上述实证的结果做出解释。
在统一的框架内研究大量深度生成模型的变体和扩展可以得到对生成式建模的广泛层面的更本质的理解,并绘制该领域进展的路线图。
以理论化的方式实现不同研究路线之间的技术迁移。例如,用于提升 VAE 的技术可以轻松地应用到 GAN 上,反之亦然。
我和同事尝试研究这个统一观点:我们推导了 GAN 和 VAE 的新的公式,可以在这些近期流行的模型之间建立形式化联系,并回溯到经典变分推断算法和 wake-sleep 算法上。新公式可以很容易地扩展到流行的模型变体,如 InfoGAN、VAE-GAN 联合模型(如 VAE/GAN)、CycleGAN、对抗自编码器、对抗域适应(adversarial domain adaptation)等等。
弥合 GAN 和 VAE 之间的鸿沟
GAN 和 VAE 都有一个生成模型(即生成器),它通常被参数化为一个深度神经网络。特别是,GAN 假定了一个隐式的生成模型,它可以通过下式生成一个样本 x:
x = G(z; θ), z ~ p(z)
即,首先从先验分布 p(z) 上采样一个噪声向量 z,然后通过神经网络 G_θ将 z 进行变换,并输出最后的样本 x。该模型是隐式的,因为它只能生成样本而不能评估似然度。上式实际上定义了对 x 的分布 p(x; θ),其中θ是我们想学习的参数。相反,VAE 假定了一个显式的生成模型:
x ~ p(x|z; θ), z ~ p(x)
这里 x 是从显式生成分布 p(x|z; θ) 上采样得到的,可以显式地计算 x 的似然度。
这些对生成模型的不同假设在我们的统一观点中并不重要,它们仅仅是可替换的建模选择。
那是什么使得 GAN 和 VAE 的联系不够显然呢?是它们学习生成参数 θ 的不同范式造成的:
VAE 额外地学习了一个变分分布(即推断模型)q(z|x; η),它是真实后验分布 p(z|x; θ) 的近似,并正比于 p(x|z; θ)p(z)。使用变分 EM 算法的经典框架,该模型可以训练来最小化变分分布和真实后验分布之间的 KL 散度:KL( q(z|x; η) || p(z|x; θ) )。
与此相反,GAN 通过设置一个对抗博弈将生成器和判别器 q_φ配对,其中判别器被训练分辨真实数据和生成(fake)样本,而生成器被训练生成足够好的能欺骗判别器的样本。
初步看来,GAN 和 VAE 的学习范式明显不同。然而,我们提出了一个 GAN 的关于θ的新公式,它和变分推断很相似:
KL( p_θ || Q_φ0 ) – JSD_θ
p_θ和 Q 分别是由生成器 p_θ(x) 和判别器 q_φ0(其中φ被固定为某个值φ0)定义的某种分布;JSD_θ 是依赖于θ的 Jensen-Shannon 散度。
通过将 p_θ看做变分分布和将 Q_φ0 看做真实后验,该公式的第一个项就是变分推断目标函数的标准形式。即,通过将 GAN 中的样本生成视为后验推断,新公式将 GAN 和变分推理以及 VAE 联系了起来。注意:这仅仅是新公式的粗略形式,用于概念化地展示 GAN 和变分推断之间的联系。我们还将 VAE 重新形式化,以揭示 VAE 实际上包含了一个退化的对抗机制,该机制阻止了生成样本在模型训练中的使用,仅允许用真实样本进行模型训练。
该统一视角给我们提供了关于这两类模型的很多新的理解:
从这两个公式中,我们可以看到 VAE 和 GAN 分别涉及最小化对应后验分布和推断分布的 KL 散度,但生成模型参数θ在 KL 散度中的位置相反。由于 KL 散度的不对称性,这直接解释了上述 GAN 和 VAE 明显不同的模型行为:GAN 中的 KL 散度倾向于驱使生成模型分布塌缩到真实后验分布的少数几个高密度区域,这使得 GAN 通常能够生成清晰图像,但是缺少样本多样性。对比来看,VAE 中的 KL 散度会驱使生成模型分布覆盖真实后验分布的所有区域,包括真实后验分布的低密度区域,这通常导致生成模糊图像。此类互补属性自然促进 GAN 和 VAE 目标的结合,以解决每个孤立模型的问题(Larsen et al., 2015; Che et al., 2017a; Pu et al., 2017)。
以上的统一视角使 GAN 和 VAE 之间能轻松地相互借鉴并产生新变体来加强各自的建模。例如,重要性加权自编码器原本是为了增强 VAE 而开发的,该技术可以移植到 GAN,带来增强的重要性加权 GAN。类似地,GAN 中的对抗机制可应用于 VAE,使用模型自己生成的样本进行模型训练。
推断和生成的对称视角
这一新的形式化建模的一个关键思想是将 GAN 中的样本生成视为后验推断。该思想可进一步扩展到一般性的生成建模上。传统的生成建模通常清晰地区分生成和推断(或区分隐变量和可见变量),并用不同的方式处理它们,我们认为这种区分有时并非必要(图 1),相反,将它们视作对称的过程可能有助于建模和理解。
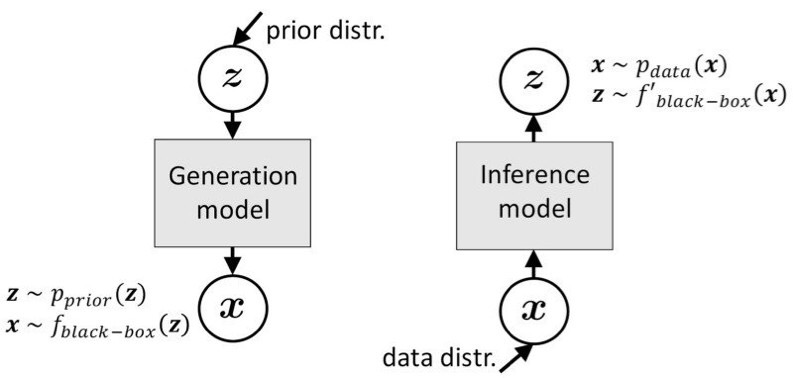
图 1:生成过程和推断过程的对称观点。二者的形式没有明显差别:使用隐式分布建模和黑箱式的神经网络变换,两个过程都只涉及在隐空间和可见空间之间的模拟(采样)和变换。
实证数据分布 p_data(x) 通常是隐式的,即易于采样,但较难估计似然度。相反,先验 p(z) 通常被定义为易于估计似然度的显式分布。幸运的是,GAN 中的对抗方法和其他技术(如密度比估计、近似贝叶斯计算)提供了弥补该差距的有效工具。
例如,隐式生成模型(如 GAN)只需要在生成过程中进行采样,无需显式的似然估计。其中隐变量的先验分布的使用方式和实证数据分布一样,即涉及从分布中采样。
对于基于显式似然度的模型,对抗自编码器(AAE)利用对抗方法允许在隐空间上使用隐式先验分布。近期的多项研究使用隐式变分分布作为推断模型,从而扩展了 VAE。实际上 VAE 中的再参数化技巧(reparameterization trick)非常类似隐式变分分布的构造。由于 KL 散度最小化无法直接应用在隐式变分分布和先验分布之间,这些算法使用对抗方法来替换 KL 散度最小化。
两种分布在复杂度方面差别很大,数据空间通常比较复杂,而隐空间较为简单。这引导我们选择合适的工具(如对抗方法 vs. 重建优化等)来最小化需要学习的分布与相应的目标分布之间的差距。
例如,VAE 和 AAE 都通过最小化变分后验分布和特定先验分布之间的距离来正则化模型,不过 VAE 选择 KL 散度损失而 AAE 选择对抗损失。
通过对生成和推断的对称性观点,以及将对抗方法作为与其他传统方法(如 KL 散度最小化和最大似然估计)同等的工具,我们可以使不同方法之间的联系更加明显。这反过来促进了新模型和新算法的出现,例如,根据问题属性相应地替换这些工具,我们能获得新的适用于该问题的模型。
论文:ON UNIFYING DEEP GENERATIVE MODELS
论文地址:https://arxiv.org/pdf/1706.00550.pdf

 友情链接
友情链接