








公众号/OReillyData
在本文中我分享了一些幻灯片和笔记。它们来自于我在2017年12月新加坡Strata 数据会议上发表的讲话,针对积极部署机器学习驱动产品的公司,这些资料提供了一些建议。在过去几年中,数据社区一直专注于用于数据收集的基础架构和平台,这其中包括了强大的数据管线,以及高度可扩展的、用于数据分析的存储系统。 据LinkedIn最近的一份报告显示,『机器学习工程师』和『数据科学家』占据了新兴职业岗位的前两名位置。大量公司开始将数据基础架构推向实战,机器学习将在未来几年变得更加普遍。
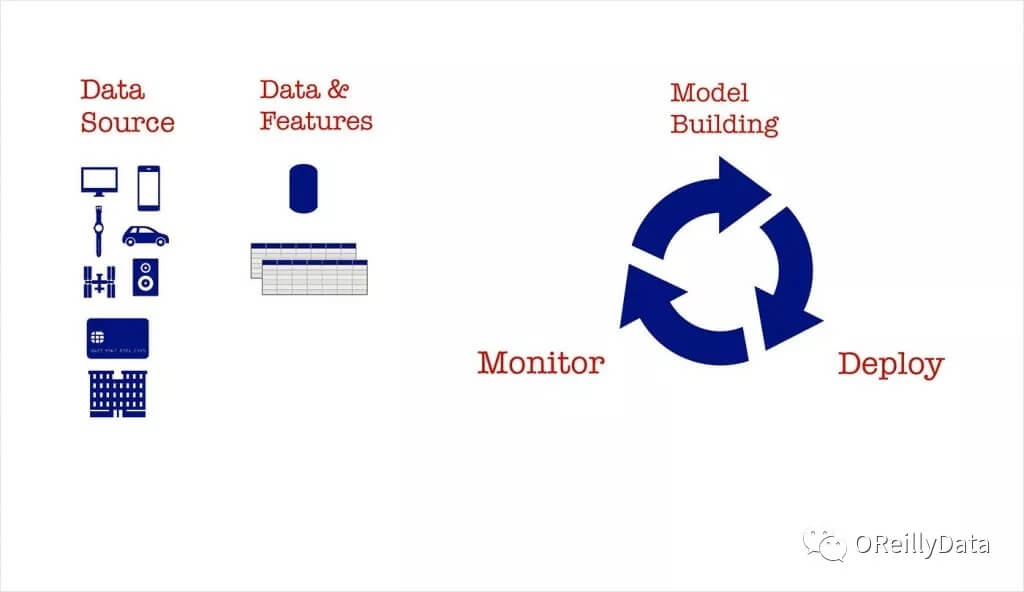
图1. 来自Ben Lorica的幻灯片
随着越来越多的公司开始在产品,工具和业务流程中使用机器学习,我们简单介绍一下模型构建,模型部署和模型管理的流程。 事实证明,一旦建立模型,在生产环境中对其进行部署和管理是需要工程技巧的。今年的早些时候,我们注意到,一些公司已经为负责在生产环境维护机器学习模型的人员创造了一个新的角色——机器学习(或者深度学习)工程师。
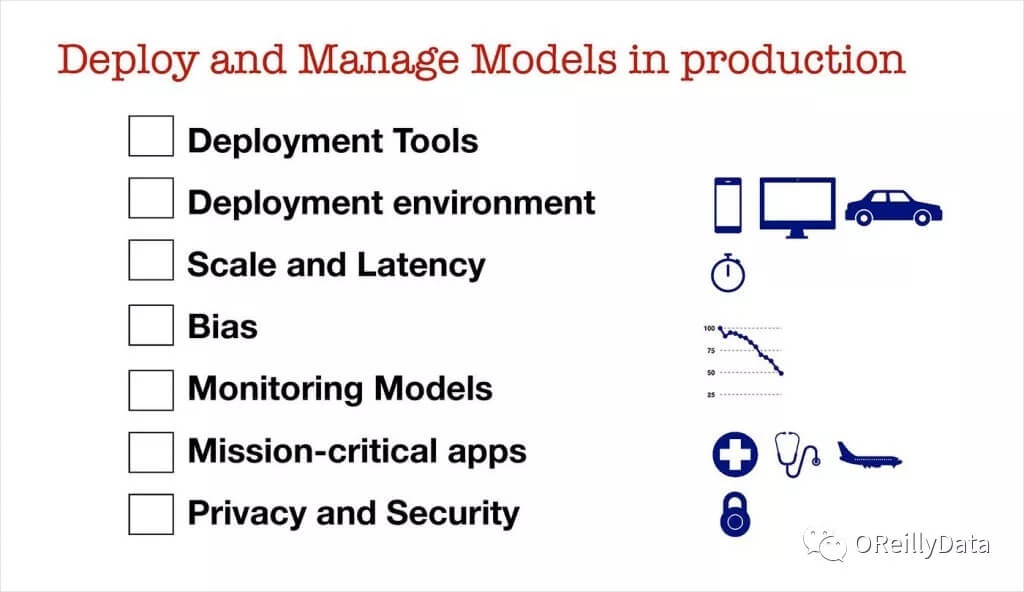
图2. 来自Ben Lorica的幻灯片
当前流行的机器学习库和类似『notebook』的工具,使构建模型变得日益简单。新的数据科学家需要确保他们理解业务问题,并在这种基础上针对业务问题对模型进行优化。 在类似东南亚这种文化多元化地区,因为东盟(ASEAN)国家的情况和场景有所不同,需要对模型进行本地化。
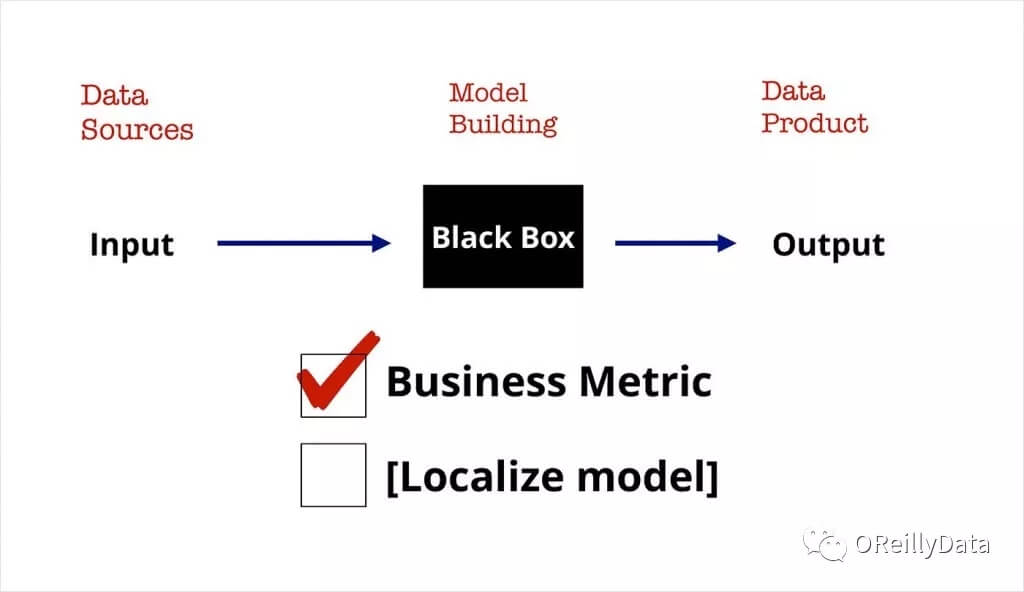
图3. 来自Ben Lorica的幻灯片
展望2018,人们对于算法偏见所造成的影响、算法的公平性/透明度的重要性渐渐有所认知,这意味着,数据科学家要做的绝不仅仅只是简单地优化业务指标。我们需要认真对待这些问题,就像我们投入真金白银来解决数据安全、数据隐私问题一样,来处理这些问题。

图4. 来自Ben Lorica的幻灯片
虽然不存在一张面面俱到的清单,可以让人系统性地解决有关公平性,透明度和问责制度的相关问题,不过一个好消息是,机器学习研究社区已经为建模人员提供了一些建议和新手起步指南。让我举几个简单的例子。
假定,在机器学习模型里你已经有了一个重要的特征(比如说,与特定地点的距离)。不过在样本总体中,存在一些分组(比如,高收入/低收入分组),在不同的分组中,特征呈现出全然不同的分布。可能发生的事情是,你的模型,对于这两个群体会产生差异性影响。 一个相关的例子是Staples推出的在线定价模型:该模型基于用户不同的地理位置,给出了不同的建议价格。
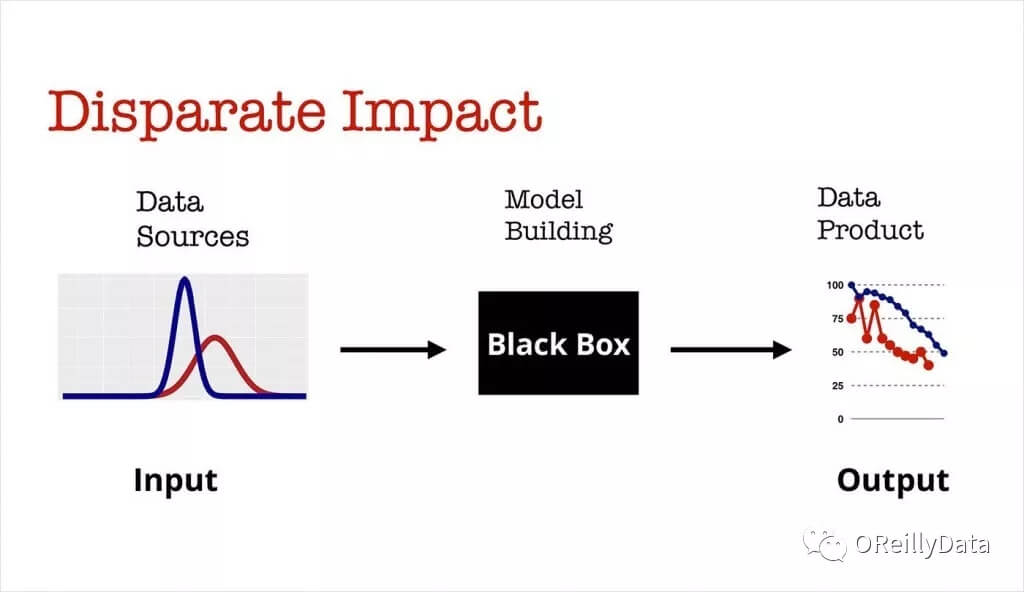
图5. 来自Ben Lorica的幻灯片
2014年,一组研究人员提供了一种数据重整化方法来消除差异性影响:
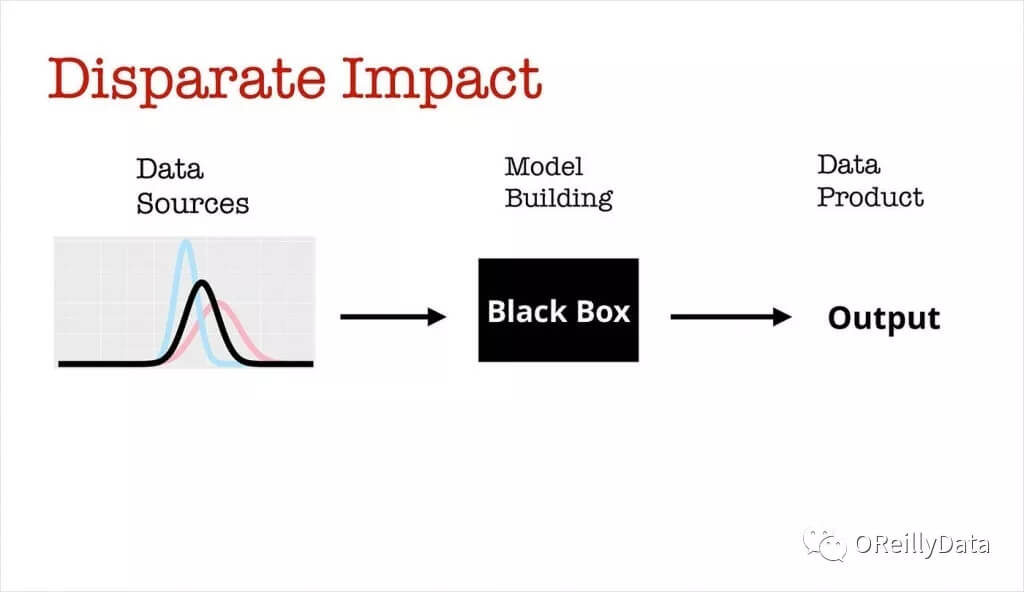
图6. 来自Ben Lorica的幻灯片,参考链接
另一个例子与预测错误有关:一旦我们对某个错误概率感到满意,我们是不是已经做好准备将我们的模型部署到生产环境中去了?考虑一下在医疗护理项目中使用机器学习模型的情况:在模型构建过程中,与老年人(蓝色)相比,千禧一代(红色)的训练数据样本量大得多。正确率有一种和训练样本大小正相关的倾向,因此,对于老年人预测的错误概率就比对千禧一代年轻人的预测错误率要高。
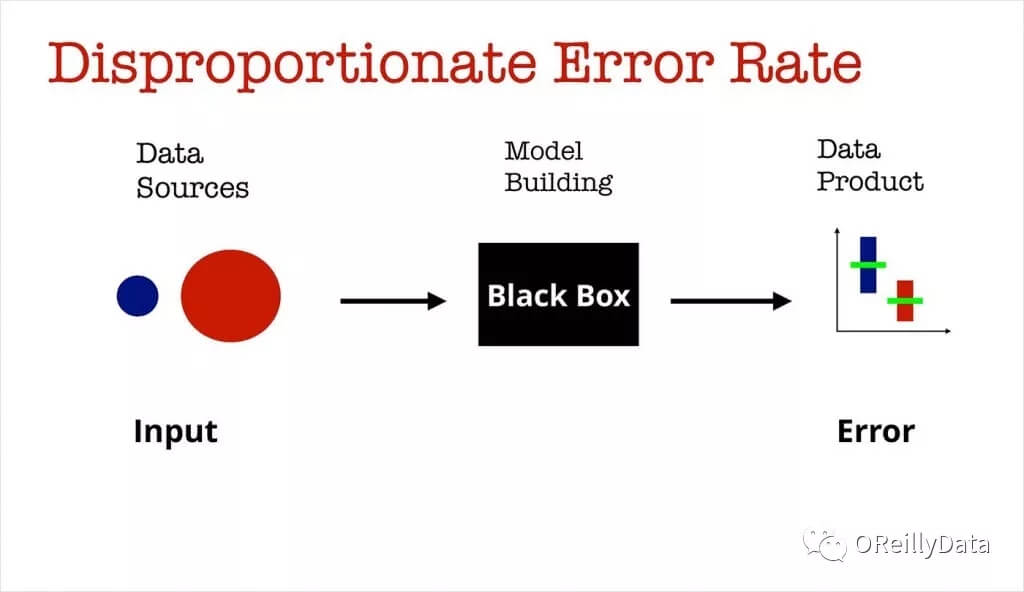
图7. 来自Ben Lorica的幻灯片
针对类似的情况,一些研究者引入了一个名为『等几率』的概念,缓解不同类间错误率不等的情况,保证不同组的『真阳性率』(True Positive Rate)接近。参考这篇论文,并结合交互式可视化方案进行阅读。
因此,当提到『数据关联错误』的时候,至少有几项是我们必须检查的:

图8. 来自Ben Lorica的幻灯片, 参考链接
为了发现不可靠的数据关联性, 我们需要使用工具来辅助我们的数据科学家和机器学习工程师。 有时候,模型的输出空间太大,以至于无法进行人工复核和检查。在2015年,包含了一个自动化图片标注工具的Google相册,在某些情况下失效很严重。谷歌受到了强烈的批评(理应如此),不过值得赞扬的是,他们人工介入了这一情况,并及时提出了一个解决方案。这里有一个例子,在这个例子中当输出空间,也就是可能的标签数目足够大的情况下,目标很容易检测不到。机器学习工程师可以使用QA测试工具,在生产环境部署这个模型之前,能够暴露出潜在的问题,方便工程师进行手动复查。
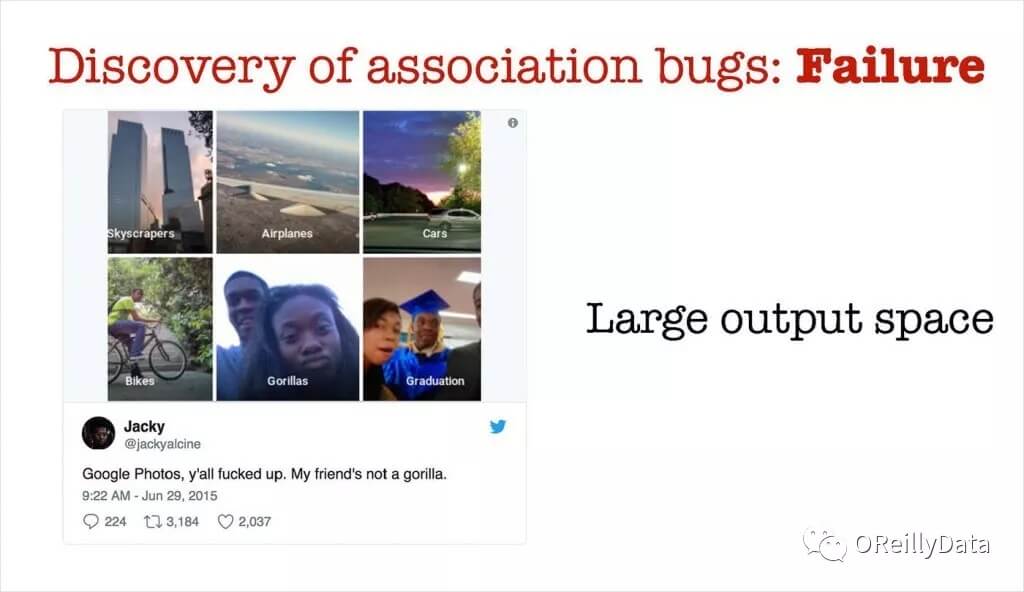
图9. 来自Ben Lorica的幻灯片。Twitter用户@jackyalcine的推文
生产环境中用于部署和管理模型的初始清单包含了一些我曾经讨论过的问题:
• 监测模型 :在许多情况下,模型性能下降,需要定期重新训练。 除了监测机器学习目标或业务指标之外,引入一些能够检测『不可靠的数据关联』的工具,防止模型变蠢,也是十分合理的。
• 关键任务应用程序 :随着机器学习在关键场合下进行部署,部署的门槛会进一步提高。模型的可重复性以及误差估计将是必需的。
• 安全和隐私 :公平而无偏见的模型,可能会受到攻击,其预测行为将会变得没有保障。用户和监管机构也将开始要求模型能够满足最严格的隐私保护条例。
让我们拿起为机器学习工程师准备的清单,并添加一些『入门级预防偏见』的流程。
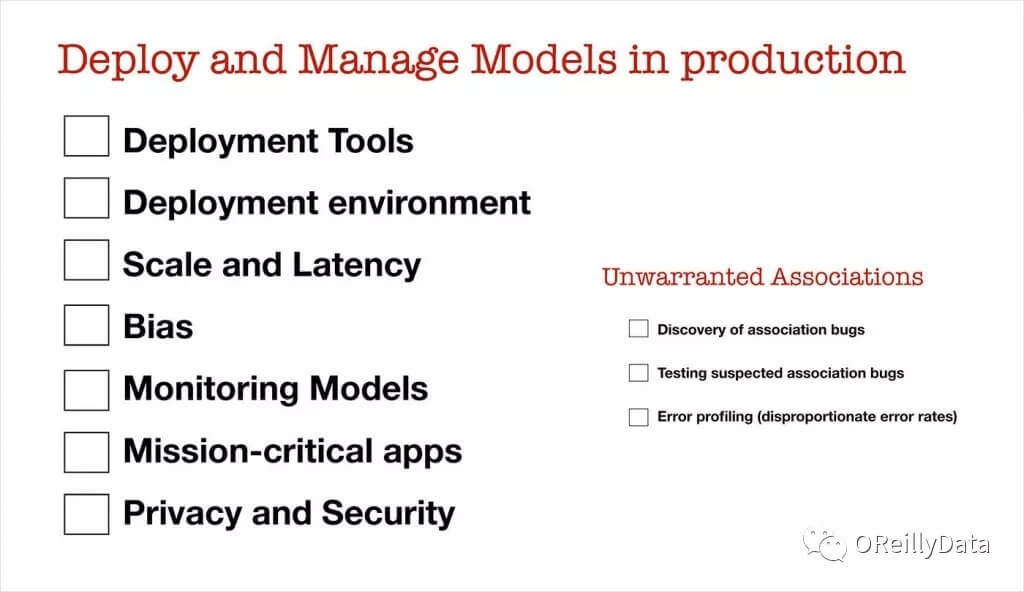
图10. 来自Ben Lorica的幻灯片
这是针对单个模型(或单个模型集成)来设计的。展望未来,我们知道许多公司要将机器学习融入许多产品,工具和业务流程中。真实情况下,机器学习工程师要负责生产环境中的大量模型:

图11. 来自Ben Lorica的幻灯片
我们如何帮助我们的机器学习工程师识别很坏的模型? 请注意,这与我们之前遇到的问题类似。 公司一直在构建工具(可观察平台),以帮助他们监控网页和网络服务,一些大公司一直在监控许多时间序列。 在2013年,我写了一篇报道是关于Twitter当年是使用何种工具来监控数以亿计的时间序列的。

图12. 来自Ben Lorica的幻灯片,由anodot.com拍摄,经许可使用
随着公司部署成百上千,甚至上百万个机器学习模型的时候,我们需要用工具辅助我们的数据科学家和机器学习工程师。 我们需要用机器学习来监控机器学习!在每一个工作日结束的时候,你的专家团队仍然需要检查那些正在发生的问题,不过他们至少需要一些自动化工具来帮助他们处理大量生产模型。

图13. 来自Ben Lorica的幻灯片,由anodot.com拍摄,经许可使用
在2018年,我们需要更严谨地对待模型的公平性,透明度和可解释性。 机器学习研究社区正致力于解决这些问题,他们开始针对如何检测问题、如何缓解出现的问题提供一些建议。由于大量公司开始在许多场景中推广机器学习,因此,我们需要构建机器学习工具,来辅助我们的数据科学家和机器学习工程师团队。我们仍然需要把人力留在第一线,但我们需要为他们提供工具,来应对即将来到生产环境中的海量模型。
相关内容:
• 应用数据科学的现状
• 什么是机器学习工程师?
This article originally appeared in English: “We need to build machine learning tools to augment machine learning engineers”.

Ben Lorica是O’Reilly Media的首席数据科学家和数据主题内容策略的主管。他已经在多个领域里(包括直销市场、消费者和市场研究、精准广告、文本挖掘和金融工程)进行了商业智能、数据挖掘、机器学习和统计分析的工作。他之前曾效力于投资管理公司、互联网创业企业和金融服务公司。

 友情链接
友情链接