








公众号/
编辑/绿萝
在现有的机器学习框架中,储层计算(Reservoir Computing)展示了快速、低成本的训练,并适用于各种物理系统。该评论报告了如何将储层计算的各个方面应用于经典预测方法,以加速学习过程,并强调了一种新方法,该方法使传统机器学习算法的硬件实现在电子和光子系统中切实可行。
预测先验未知和复杂系统的未来发展,是一项可以通过基于非常规(或模拟)计算的算法来解决的任务。已经开发或应用于具有不同复杂程度的时间序列预测任务的大量经典回归模型。从统计预测领域来看,有经典的线性方法,如:自回归积分移动平均方法(ARIMA)或向量自回归(VAR)以及这些方法的扩展,例如非线性向量自回归(NVAR)。从机器学习领域来看,复杂度谱的下端有储层计算(RC),上端有深度神经网络(DNN),以及介于两者之间的各种其他学习算法。除了时间序列预测之外,机器学习算法还适用于解决一系列其他任务,例如图像或语音识别。
来自德国柏林工业大学 Lina Jaurigue 和伊尔梅瑙技术大学的 Kathy Lüdge 发表评论文章,主要集中在最近发表在《Nature Communications》上的研究(https://www.nature.com/articles/s41467-021-25801-2;https://www.nature.com/articles/s41467-021-25427-4),这些研究将这一方法层次结构的元素连接起来,并促进了研究领域之间的知识转移。
该评论以「Connecting reservoir computing with statistical forecasting and deep neural networks」为题,于 2022 年 1 月 11 日发表在《Nature Communications》上。
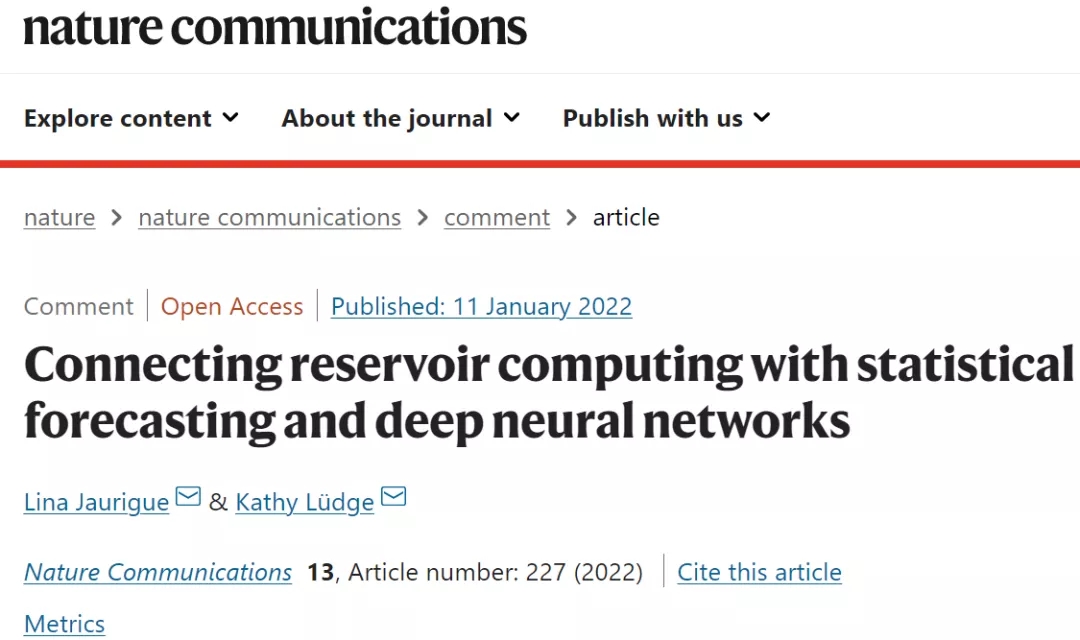
这里讨论的不同方法之间的联系是 RC。首先解释它的概念,并将其与 DNN 和 NVAR 进行简要比较。
RC 最初是由 H. Jaeger 以「echo-state」机器的名义引入的。它由一个循环网络(「水库」)组成,该网络由输入数据驱动,输出是通过线性组合读出节点的状态产生的,如图 1b 所示。对于传统的神经网络算法,所有权重都经过训练,如图 1a 所示,用于深度神经网络。与此相反,只有输出权重在 RC 中通过线性回归进行训练(图 1b 中的黄线)。这种训练复杂性的降低必须通过增加「水库」的尺寸来补偿,但这意味着任何物理动力系统都可以用作“水库”(例如生物组织、水桶或半导体网络)。RC 背后的思想是,「水库」对输入执行非线性变换,如果网络选择得当并且读数正确采样,则可以逼近所需的输出。在 NVAR 等方法中,直接选择输入的非线性变换并构成所谓的特征向量,其元素被线性组合以产生输出(见图 1c)。RC 和 NVAR 之间的某种相似性是显而易见的,最近表明这些方法在某些条件下是等效的。
图 1:不同机器学习架构的可视化。
受到 Bollt 研究结果的启发,Gauthier 等人将 RC 的各个方面应用于 NVAR,从而引入了他们所谓的下一代储层计算 (NG-RC)。具体来说,使用了 Tikhonov 正则化,并且还考虑了相关性在特征向量中的作用。通过他们的方法,作者在典型的时间序列预测任务中取得了良好的结果,同时与传统的 RC 相比具有几个优势。首先,没有存储库意味着要调整的超参数更少。其次,作者表明,至少对于他们选择的任务,需要更短的训练数据集,并且输出向量的维度小于可比较的储层计算机的节点数。这两个因素也导致计算时间更短。如果所需训练数据集的类似减少对于训练数据通常有限的实际问题也是可行的,那么 NG-RC 确实可能是有利的。然而,使用这种方法本质上是在优化储层超参数来优化特征向量的元素,而后者仍然是一个非常悬而未决的问题。特征向量的选择是否通常比储层计算机的超参数优化更容易,还有待观察。
虽然 Gauthier 等人将他们的方法称为 RC,他们还表示它最接近 NARX,并且可以说它实际上也是一种统计学习方法。但是,一般机器学习和统计方法之间的一个重要区别是预期目的。对于 NARX 方法,选择算法的设计使得只选择几个术语,并且生成的模型足够紧凑和透明,可以深入了解底层系统元素之间的关系。而在机器学习中,目标完全是优化给定任务的性能。后一种方法也适用于 NG-RC 方法,其特征向量的项比典型的 NARX 方法多得多。正是特征向量项的选择和 Tikhonov 正则化的使用,使 NG-RC 有别于成熟的统计方法。然而,作者确实指出,可以减少特征向量中的组件数量而不会显着影响误差,因为一些组件非常小。在这方面,统计预测界可能会对 NG-RC 感兴趣,如果可以将生成的 NG-RC 简化为可管理的模型,可以从中推断出底层系统。
近年来,人们对 RC 的兴趣很大程度上源于硬件实现的可能性,因为与传统计算机上的实现相比,在速度和功耗方面有很大的提高。特别适合这一点的是参考文献中引入的基于延迟的 RC 的概念。(见图 2a)。在这种情况下,储层只需包含一个具有延时自反馈的非线性元件。对于小输入,RC 性能可以从物理节点的线性响应中推导出来。向任何系统添加延迟使其在技术上具有无限维度。实际上,系统没有无限维,但是,如果参数选择正确,这样的系统可以表现出复杂的高维瞬态动态,因此可以在各种机器学习基准测试任务中表现良好,例如,仅使用具有延迟的单个节点而不是随机耦合节点的网络是一种极大的简化,这使得该方案特别适用于光学设备的硬件实现。
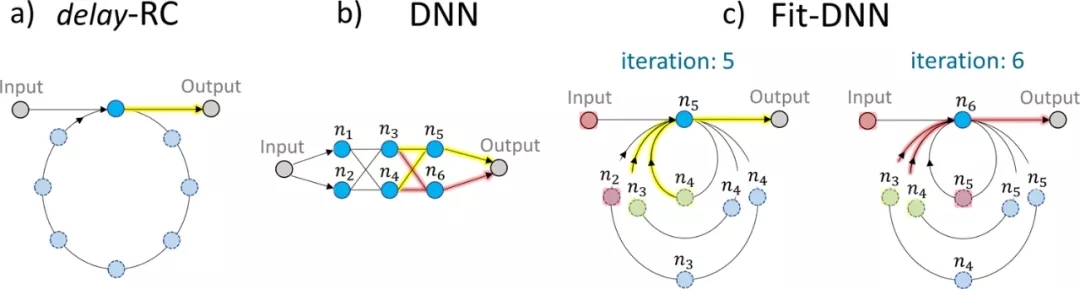
图 2:通过时间延迟和顺序采样的深度神经网络。
在 Stelzer 等人的研究中,作者采用了仅使用具有延迟的单个物理节点的想法并将其扩展为模拟深度神经网络,他们创造了一种时间折叠深度神经网络(Fit-DNN)。这是通过具有可调节反馈强度的多个延迟环来实现的,而物理节点提供非线性(参见图 2c,Fit-DNN 与图 2b 中的相应 DNN)。Fit-DNN 的一个网络节点现在被定义为某个时间的系统状态,并且所有节点都被顺序采样。层之间的耦合是通过耦合回适当的延时信号来实现的。作者表明,如果节点之间的时间间隔,即系统采样的时间间隔,与物理节点的特征时间尺度相比足够大,那么 Fit-DNN 就相当于一个深度神经网络。当节点间隔较小时,由于时间上相邻的节点不是完全独立的,因此存在额外的层间和层内连接,需要使用改进的反向传播方法来训练系统。对于小节点分离和稀疏 DNN 的情况,即延迟循环数量减少的 Fit-DNN,作者测试了各种基准任务的性能。对于稀疏 Fit-DNN,他们发现了良好的性能,但强调删除/添加延迟循环会改变耦合权重矩阵的整个对角线,为此,仍然需要一种新的训练方法。在小节点分离的情况下,性能会降低,但是,这需要通过减少节点采样之间的时间来减少计算时间来权衡。对于具有大节点分离的全连接 Fit-DNN,传统的 DNN 以不变的性能完全再现。
总的来说,我们发现 Stelzer 等人介绍的新方法非常有趣,希望在不久的将来看到这种方法的硬件实现。然而,在这一点上,我们还必须提到作者也讨论的一个重大缺点。尽管这种方法非常适合在硬件中实现,例如在光子或光电装置中,但仍必须使用传统计算机进行训练。此外,由于需要求解延迟微分方程,因此可以显着增加训练时间。因此,最终训练系统的速度和效率需要与训练过程进行权衡。
总而言之,两种新引入的非常规计算方案,即 NG-RC 和 Fit-DNN,提出了实现有效且高性能且生态足迹较小的机器学习应用程序的方法。此外,汇集来自不同社区的知识,这里是统计学习、非线性动力学和机器学习社区,导致了具有高度创新潜力的交叉施肥。
论文链接:https://www.nature.com/articles/s41467-021-27715-5

 友情链接
友情链接