








公众号/将门创投
From:Berkeley 编译:T.R
在环境中保持稳定是所有生物共同的基本诉求,我们会不断努力追求确定性的环境和未来,并在与环境交互的过程中展现出一系列复杂的行为与能力。来自伯克利的研究人员就在这种机制的启发下提出了一种新型的无监督强化学习方法SMiRL,为主体的智能学习过程提供了新的视角。
几乎所有的生物都在环境中找到了自己的一片庇护所,以便在这复杂多变的世界中保持相对可控的生存条件。例如人类的进化历程就是一个保护自己不受意外侵袭的发展史,我们联合起来建造城市和大规模的住房、完善的水电煤气、建造了冬暖夏凉的舒适居住空间,避免了祖先曾经经历过的风吹雨打和风餐露宿。所有的生物发现并维持这种平衡,保持对现实的控制力需要发展出多样性的适应能力和复杂的技能。这种对于环境适应的自主学习也启发了研究人员,在充满混沌和熵增的环境中保持秩序是不是可以促使智能体自动习得有效的技能呢?
在没有外界监督的情况下,智能体如何才能在环境中学会复杂的行为和技能呢?学者们针对这一人工智能的核心问题提出了一系列可能的解决方案,其中大部分集中于寻求新颖的行为方向。在类似电子游戏一类的虚拟世界中,寻求新方法的内在动机的确可以得到很多有趣并且有用的行为,然而这样的环境去在根本上缺乏与真实世界的可比性。
真实世界中,自然环境和其他主体的相互作用提供了丰富的新途径,同时也带来了瞬息万变的挑战:智能体需要不断的发现和学会新的行为维持秩序的微妙平衡,例如保护自己、居所,避免捕食者和天敌等等。下面的例子中我们可以看到智能体在随机天气环境中学会了构建庇护所,大幅度减小了天气带来的可观测影响。

在前面的观察下,研究人员将内在稳态视为强化学习的目标函数,以便最小化环境中的变化,提出了一种新的强化学习方法SMiRL(reinforcement learning based on surprise minimization)。
在熵增和动力学环境中充斥着不希望发生的意外,最小化这些意料之外的情况将使得智能自然而然地去寻求可以维持稳态的平衡。
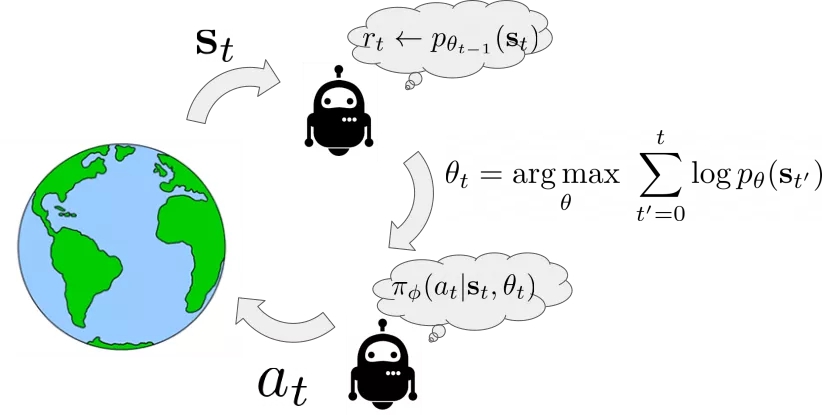
上图显示了SMiRL的基本循环过程。当主体观察到环境的状态s时,它会基于其置信函数rt ←pθ t−1(s).计算新状态的概率。这一置信模型描述了主体最为熟悉的状态,而这一状态与其经历过的状态分布相关,经历更熟悉的状态将带来更高的建立函数。在主体经历新状态后,它将更新置信函数 pθ t−1(s)。随后行为策略π(a|s,θt)的目标将是选择能使主体继续进入最熟悉状态的行为。
最关键的是,主体能意识到它的置信函数会在未来发生改变,这意味着它拥有两种最大化奖励的机制:一种是采取最为熟悉的行为(可以称为循规蹈矩的稳定),另一种是采取可以改变其置信模型的行为,使得未来的行为更为熟悉(可以视为跳出舒适区的创新)。正是后一种机制导致了更为复杂的行为产生。下图显示了训练俄罗斯方块游戏的可视化策略,左图的右半部分显示了置信pθ t(s)的变化情况.主体倾向于将块置于底部,这鼓励了主体倾向于清除方块,避免了不断的堆高。
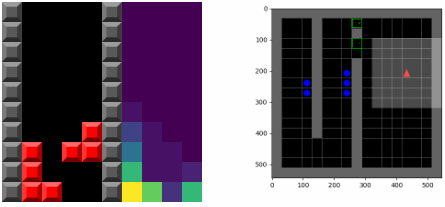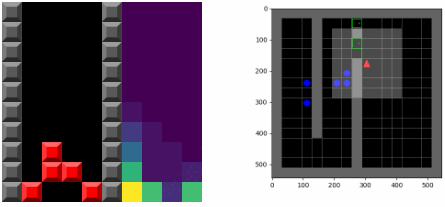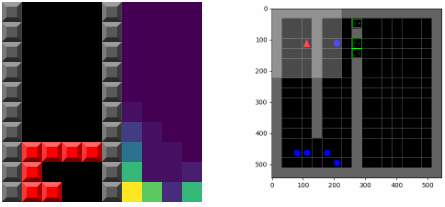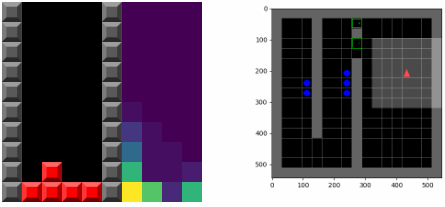
应急行为Emergent behavior
SMiRL主体在多个不同环境中都描述了应急行为将产生有意义的结果。在俄罗斯方块中,主体学会了消除一行行砖块并正确地进行游戏;在《毁灭战士》视觉游戏(VizDoom)中学会了如何躲避敌人发出的火圈。这些环境中随机和混沌事件都迫使SMiRL主体采取协调的行为来避免像方块堆满的空间或者火球爆炸这样不可预测的结果。

保卫战线的战士
双足机器人
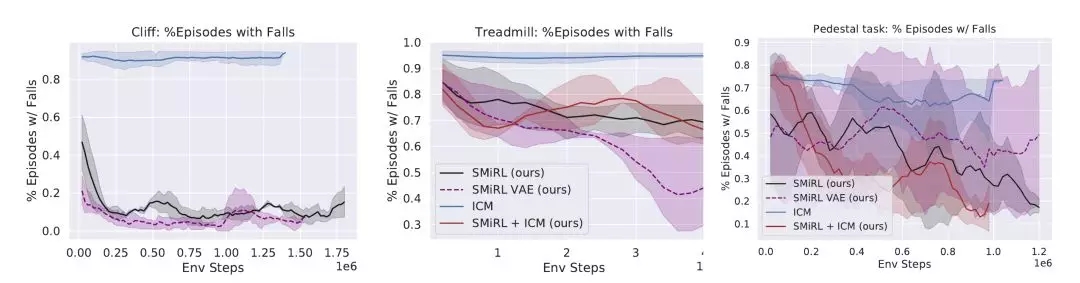
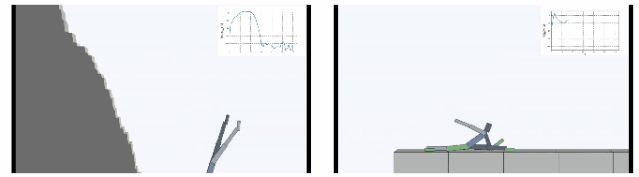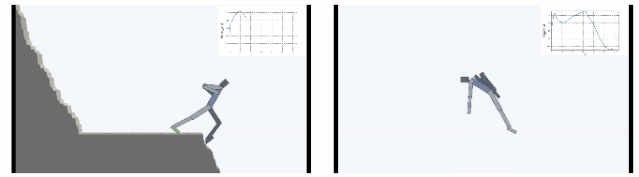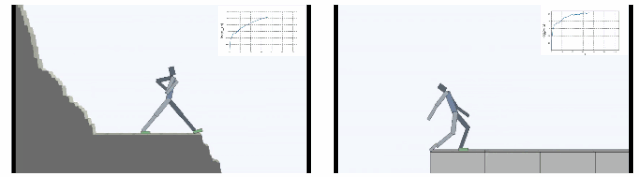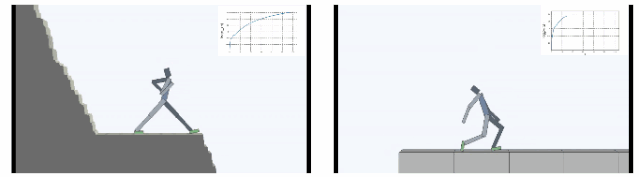
下图显示了在Cliff环境中主体学会了如何通过在边缘稳定支撑身体,大幅减小从悬崖摔下概率。在Treadmill环境中SMiRL学会了更为复杂的运动行为,例如向前跳来增加待在跑步机上的时间。
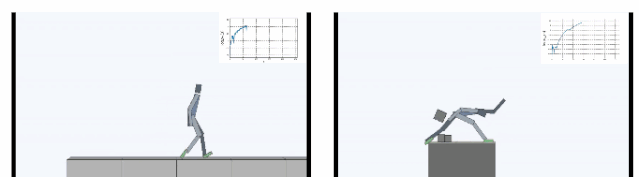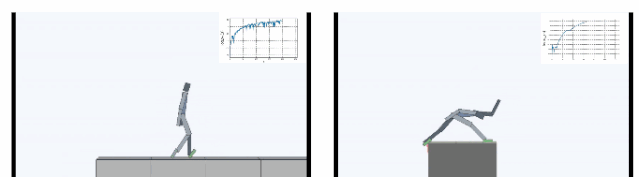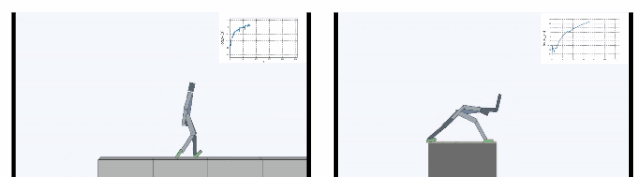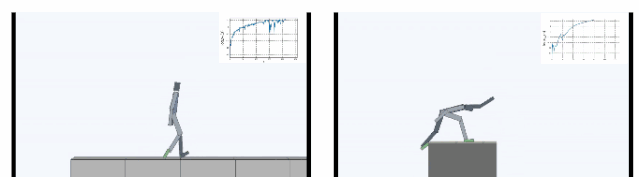
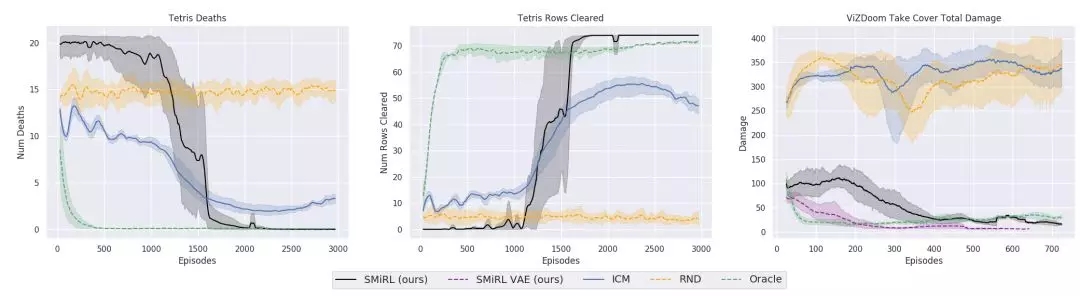
内在动机的比较
内在动机假设行为是受与任务无关的内在奖励信号驱动的。下图研究人员绘制了俄罗斯方块、毁灭战士和人型机器人仿真中与环境相关的奖励函数。为了与更为标准的内在动机方法比较SMiRL,研究人员还测评了ICM方法和RND方法。同时在环境中构建了一个直接优化任务奖励的主体oracle。可以看到,在俄罗斯方块中2000次迭代SMiRL就能达到较为完美的状态。ICM则为了寻求最大的变化创建了更多方块而不是清除它们。在VizDoom中,SMiRL通过对抗学会了躲避火球。
SMiRL在Cliff和Treadmil环境中也有相同的表现,ICM的新颖搜索使得它的行为不正常,造成了主体从悬崖摔下或者从跑步机滚下,与幸存的行为相反,它最大化了摔下的变化量。
SMiRL + Curiosity
虽然表面上SMiRL最小化不确定性,而Curiosity则最大化变化,它们是彼此矛盾的。ICM方法着眼于学习状态转移模型来最大化变化,而SMiRL则专注于学习状态分布来最小化变化。但实际上我们可以在实践中结合这两种方式达到更好的结果。
观点与启发
这一研究的关键在于主体会抵抗环境中的熵增,它需要学会有用的行动来平衡这一状态,逐渐学会越来越复杂的行为。与简单的内因驱动不同,SMiRL为非监督强化学习方法提供了可能的发展方向,在行为与对手、熵源和环境中其他突发因素紧密相关时,主体会尽力避免环境中出现突发事件或其他导致熵增的事件。
ref:
https://bair.berkeley.edu/blog/2019/12/18/smirl
author:https://people.eecs.berkeley.edu/~gberseth/
doom:https://baijiahao.baidu.com/s?id=1609585166308558051

 友情链接
友情链接