








公众号/机器之心
选自 KDnuggets
作者:Jesus Rodriguez
机器之心编译
参与:李诗萌、路
最近,谷歌大脑团队发表了一篇论文,文中提出了一种叫做概念激活向量(Concept Activation vectors,CAV)的新方法,这种方法为深度学习模型的可解释性提供了一个全新的视角。
可解释性仍然是现代深度学习应用的最大挑战之一。计算模型和深度学习研究领域近期取得了很大进展,创建了非常复杂的模型,这些模型可以包括数千个隐藏层、数千万神经元。虽然创建高级深度神经网络相对简单,但理解如何创建这些模型以及它们如何使用知识仍然是一个挑战。最近,谷歌大脑(Google Brain)团队发表了一篇论文《Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV)》,提出一种叫作「概念激活向量」(Concept Activation Vectors,CAV)的新方法,为深度学习模型的可解释性提供了全新视角。
论文地址:https://arxiv.org/pdf/1711.11279.pdf
GitHub 地址:https://github.com/tensorflow/tcav
可解释性与准确率
理解 CAV 技术,需要首先理解深度学习模型可解释性难题的本质。在这一代深度学习技术中,模型准确率与可解释性之间存在永久的冲突。可解释性与准确性之间的冲突也是实现复杂知识任务与如何实现这些任务之间的冲突。知识与控制、性能与可解释性、效率与简洁……这些问题都可以通过权衡准确率与可解释性来解释。
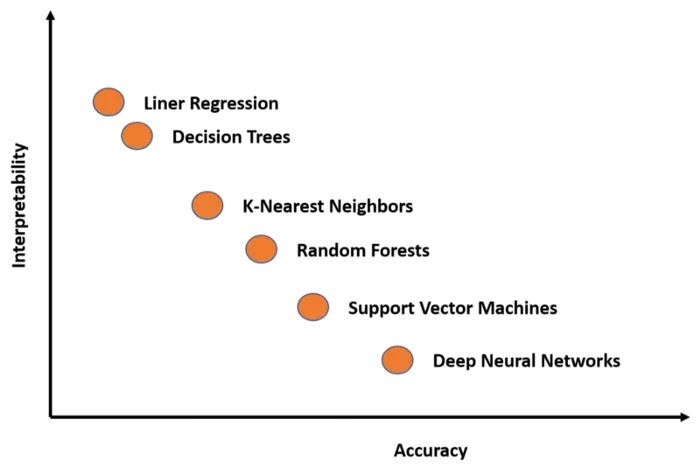
你想要最佳结果还是想理解这些结果是如何产生的?这是数据科学家在每个深度学习场景中都要回答的问题。很多深度学习技术本质上是复杂的,尽管在很多情况下它们产生的结果是准确的,但是它们难以解释。如果我们绘制一些著名深度学习模型的可解释性和准确率,可以得到:
深度学习模型的可解释性不是一个单一的概念,可以跨多个层次来理解:
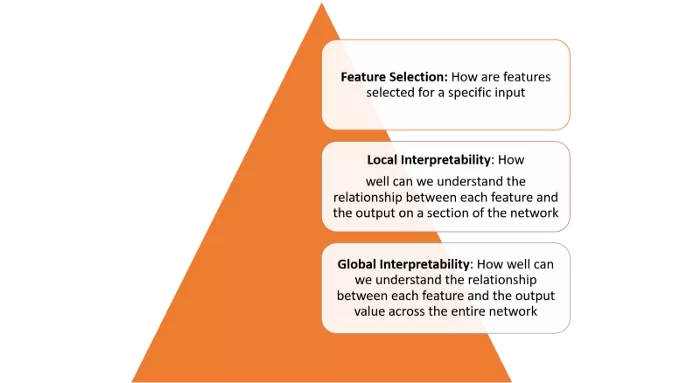
要跨越上图定义的层次来解释模型,需要一些基础的构建块。在近期的一篇文章中,谷歌的研究人员概述了他们认为解释模型所需的基础构建块。
谷歌将可解释性原则总结如下:
理解隐藏层做了什么:深度学习模型中的大部分知识是在隐藏层中形成的。要解释深度学习模型,必须要从宏观角度理解不同隐藏层的功能。
理解节点是如何激活的:可解释性的关键不是理解网络中单一神经元的功能,而是要理解在同一空间位置一起激活的互相连接的神经元组。通过互相连接的神经元组分割网络可以从更简单的抽象层次来理解其功能。
理解概念是如何形成的:深度神经网络如何形成可组装成最终输出的单个概念,理解这一问题是另一个关键的可解释性构建块。
而这些原则是谷歌新方法 CAV 的理论基础。
概念激活向量(CAV)
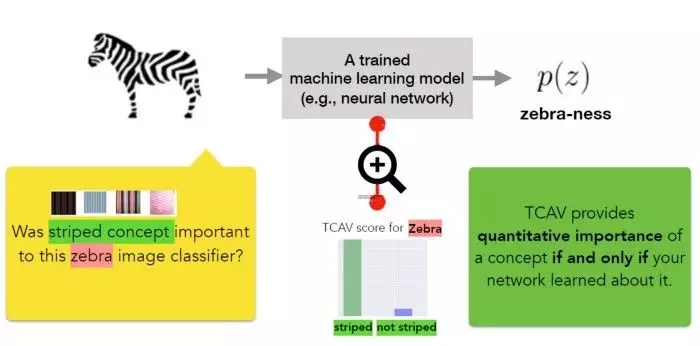
如前所述,可解释性的一般方法应该是根据深度模型所考虑的输入特征来描述其预测结果。一个经典例子就是 logistic 回归分类器,一般会把分类器中的系数权重解释为每个特征的重要性。但大部分深度学习模型在特征层面(如像素值)的运算,无法和人类能轻易理解的高级概念对应。此外,模型的内部值(例如神经激活)似乎是无法理解的。尽管像显著性图(saliency map)这样的技术可以有效测量特定像素区域的重要性,但它们无法和更高级的概念相对应。
CAV 的核心思想是度量模型输出中概念的相关性。对概念来说,CAV 是概念示例集的值方向上的一个向量。在他们的论文中,谷歌研究团队还提到了一种名为 TCAV(Testing with CAV)的新型线性可解释性方法,这种方法用方向导数(directional derivatives)来量化模型预测对 CAV 学习到的底层高级概念的敏感度。从概念上讲,定义 TCAV 有以下四个目标:
易于访问:用户几乎不需要 ML 专业知识。
可定制化:适应任何概念(比如性别),而且不受限于训练过程中所考虑的概念。
插件准备:不需要重新训练或修改 ML 模型就可以直接工作。
全局量化:用单个量化方法就可以解释整个类或整组示例,而且不只是解释数据输入。
为了实现上述目标,TCAV 方法分为三个基本步骤:
给模型定义相关概念;
理解预测结果对这些概念的敏感度;
全局定量解释每个概念对每个模型预测类的相对重要性。
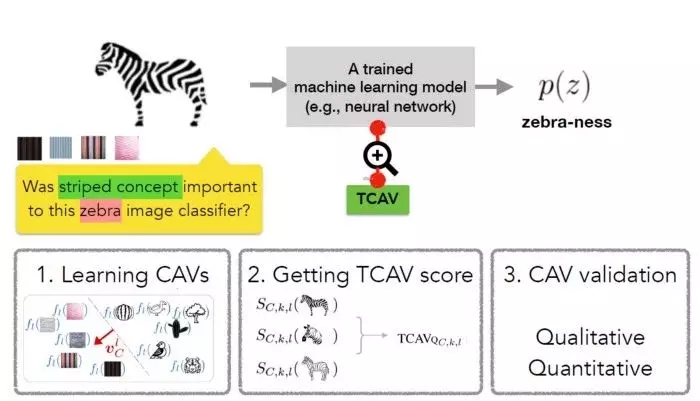
TCAV 方法中的第一步是定义感兴趣的概念(CAV)。TCAV 使用的方法是,选择一组可以表示这个概念的示例集,或者可以找到具备该概念的独立数据集的示例集。通过训练能够分辨概念示例产生的激活和任意层产生的激活的线性分类器,学得 CAV。
第二步是生成 TCAV 分数,该分数表示预测结果对特定概念的敏感度。TCAV 用方向导数实现了这一点,方向导数可以在神经激活层衡量 ML 预测值对沿着概念方向变化的输入的敏感度。
最后一步是评估学到的 CAV 的全局相关性,来避免依赖不相关的 CAV。TCAV 技术的一大缺陷是可能学到无意义的 CAV。毕竟,就算用随机选择的一组图片也会得到 CAV。基于这种随机概念的测试不太可能有意义。为了解决这一问题,TCAV 引入了统计显著性检验,根据随机的训练次数(一般是 500 次)评估 CAV。这一步的思路是,有意义的概念会让训练过程中的 TCAV 分数保持一致。
TCAV 的效果
谷歌大脑团队进行了多项实验来对比 TCAV 和其他可解释性方法的效率。在最引人瞩目的一项实验中,该团队用显著性图来理解出租车的概念。该显著性图的输出如下图所示:
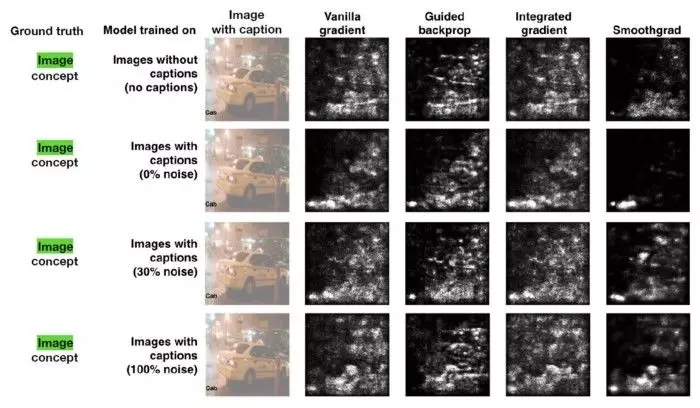
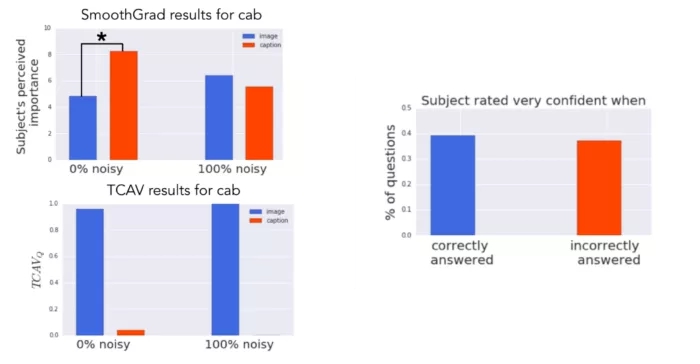
谷歌大脑团队用这些图像作为测试数据集,在 Amazon Mechanical Turk 上用 50 人进行了实验。每个人做 6 项任务(3 object classes x 2s aliency map types),所有这些任务都针对单个模型。任务顺序是随机的。在每项任务中,工作人员首先会看到四张图像及其对应的显著性掩码(saliency mask)。然后他们对图像对模型的重要性(10 分制)、标题对模型的重要性(10 分制)以及他们对自己答案的确信程度(5 分制)等问题进行打分。这些工作人员一共评估了 60 张不同的图像(120 个不同的显著性图)。
实验的基本事实是图像概念与标题概念更相关。但当看到显著性图时,人们认为标题概念更重要(0% 噪声模型)或没有差别(100% 噪声模型)。相比之下,TCAV 的结果正确地表明了图像概念更重要。
TCAV 是近几年间研究神经网络可解释性领域中最具创新性的方法之一。GitHub 上有 TCAV 的初始技术代码,我们期待看到一些主流深度学习框架会采用这一想法。

 友情链接
友情链接