








公众号/将门创投
arxiv 编译: T.R
【温馨提示】本文长度4967字,建议先收藏后认真阅读。
基于图像进行三维重建是一个十分重要的研究问题,来自于计算机视觉、图形学和机器学习领域的研究人员对这个领域进行了多年的探索。同时通过图像进行三维重建在机器人导航、视觉感知、物体识别、环境理解、三维建模等领域有着重要意义,也会为工业制造、智能控制和医疗健康等行业带来广泛的应用。

随着深度学习的飞速发展,基于图像的重建问题呈现出新的面貌、出现了很多令人惊叹的研究工作和新的探索方向。
为了充分了解基于深度学习方法利用图像进行三维重建的发展脉络、技术路线和主要方法、分析这一领域的关键问题和主要技术手段,来自天津大学、西澳大学和莫道克大学的研究人员们对这一领域进行了全面的梳理,对利用深度学习手段从图像估计三维形貌的诸多工作进行了总结。从114+论文中整理了详尽的资源,分别从三维表示、网络架构和训练策略等方面进行分析,并给出这一领域的开放问题和未来值得探索的方向。

从2D图像中恢复出缺失的维度曾是多视图立体视觉以及从多种线索恢复形状(shape from …)研究的天下。基于几何视角的研究主要理解并构建3D到2D的投影关系,并建立有效的数学模型来解决这一问题。这种方法通常需要进行相机标定和多视角拍摄的图像,并基于特征匹配和三角关系在3D坐标系中进行重建。同样基于其他线索的三维重建也需要大量的图像和相机标定,这会大大限制了多种环境下的应用。
但我们在日常生活中可以感受到万能的人眼可以结合大量的先验知识通过一眼就能推断出物体的三维形状,甚至是在其他视角下的模样。在人眼的启发下,研究人员开始利用深度学习和先验知识构架第二代3D重建方法,在大量数据的支撑下实现从单张或多张RGB图像直接重建出物体的三维形貌,而无需复杂的标定和数学过程。
这些方法在近年来取得了令人瞩目的效果,在通用物体重建和类似人脸的特殊物体重建上都取得了不错的结果。接下来我们将从重建问题的流程,三维表示,基于不同表示的重建方法、模型架构、数据集以及训练过程等方面回顾过去几年间深度学习在这一领域的发展。
三维重建问题可以归结为通过n张RGB图I(n>=1)预测出单个或多个目标X,学习的过程就是将图像I映射为形状X的函数f(theta),并尽可能地缩小预测形状与真实形状间的差异,这一差异在深度学习中就以损失函数的形式表现出来。
输入:基于图像的三维重建,其输入可以是单张图像也可以是多张图像、甚至可以是视频流,可以是内参已知的也可以是内参未知的。除了通常的图像外,还可以通过一系列额外信息辅助三维重建,包括轮廓、语义标签、分割掩膜等,作为先验信息引导算法进行重建;
输出:在三维空间中,物体通常有多种表示方法,包括体素、表面网格以及其他中间媒介。作为三维重建的输出,合适的表示方式对于算法的选择和重建的结果至关重要。
体素(volumetric,voxel)表示是基于深度学习的三维重建领域最早开始采用的方式,使得诸多参数化物体可以通过规则的空间体素网格来表示。这种方法可以将图像领域使用的架构拓展到三维领域,利用规则的三维卷积实现三维重建。这种方法虽然是二维卷积的自然延伸,但在三维空间中操作收到了内存的限制,会消耗巨大的算力资源。
在学界和工业界,基于体素的表示方法主要分为四种主要的类型,分别是基于二值占据的栅格、基于概率占据的栅格、符号距离函数(SDF)的表示以及截断符号距离函数(TSDF)的表示。这些表示创建了对于物体空间的规则采样,如果不进行有效处理,对于物体的重建将受到体素分辨率的限制。
早期基于体素的三维学习方式采用了均匀的空间体素网格,虽然这种方法易于使用3D卷积在GPU上实现,但由于三维体素和卷积对于计算资源的消耗,使得均匀体素的表示空间分辨率限制在了323232到646464之间,很多细节都会缺失。
为了解决这一问题,在给定计算资源下实现较好的高分辨率重建,研究人员提出了各种方法用于提高体素表示的分辨率,通过空间刨分、形状刨分子空间参数化和由粗到精的优化策略等实现了较好的细节重建。
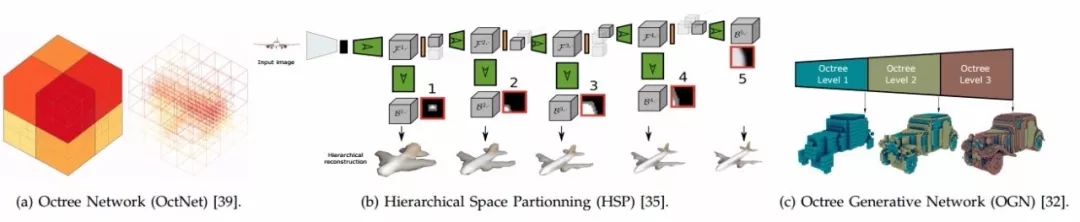
三种典型的形状刨分策略,基于八叉树和层级空间刨分策略实现了较好的细节恢复。
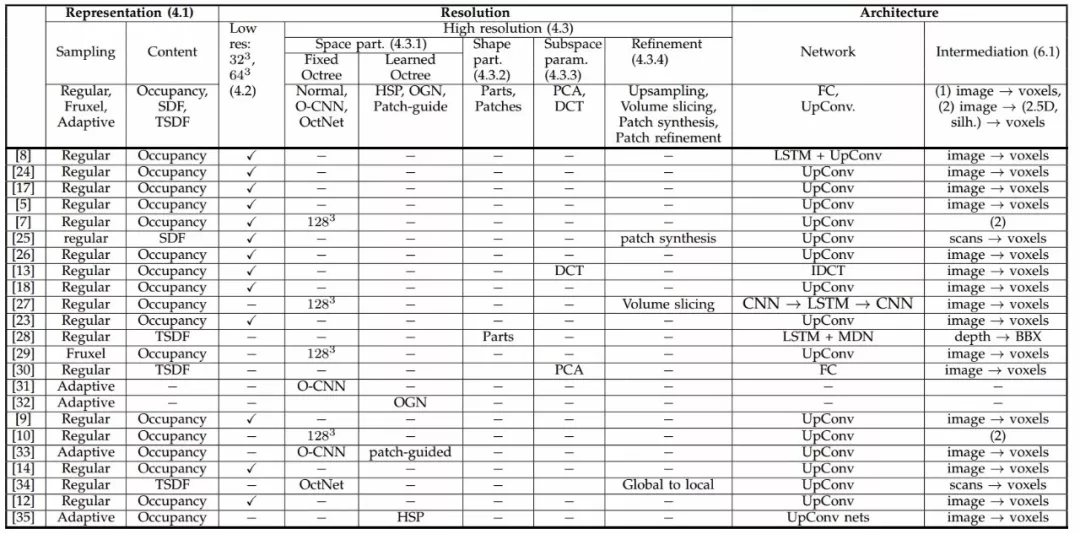
除此之外还有多种体素表示方式,研究人员们总结从表示、分辨率和架构等方面总结了二十多种文献中的方法,详细总结了基于体素的研究。
三维表面(surface based)是三维形状的另一种表示方法,这种方法可以克服体素带来的计算资源消耗问题。主要的方法包括基于表面网格和点云的方法,以及参数化三维重建和基于可变形模版的三维重建。但这种高效的方法所面临的最大问题在于表示的不规则性,使得典型的深度学习架构无法方便的处理这些表示。
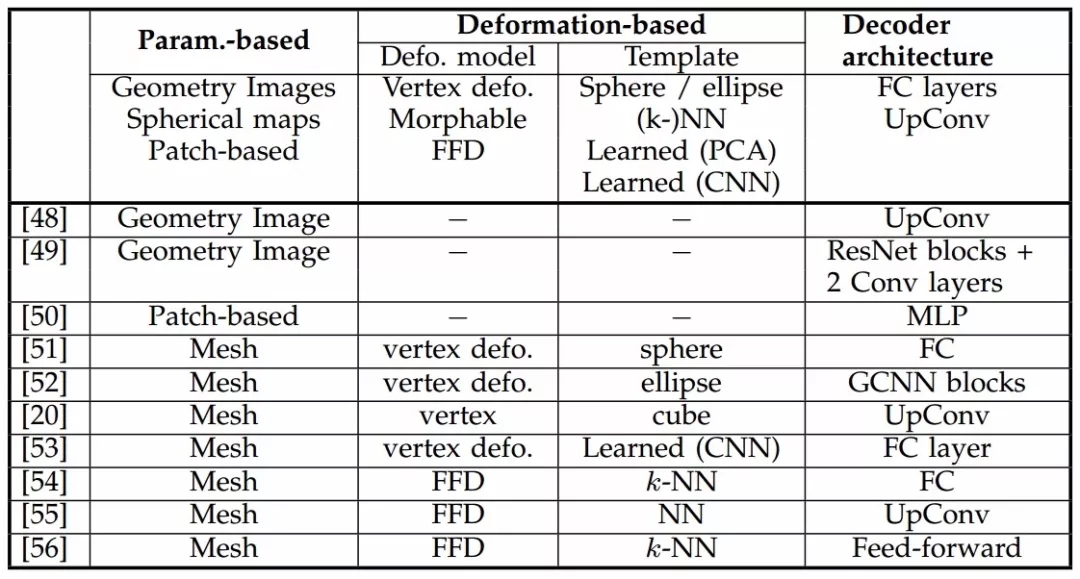
研究人员们提出了各种方法来解决这一问题,包括改进的二维卷积、球卷积、可变形模型和编码器解码器架构。下表总结可以各种基于mesh的表示的网络架构。
点云作为一种重要的三维表示形式也受到了研究人员的广泛关注。人们通常使用N*3的矩阵,或者是编码xyz三通道的栅格数据,以及深度图来对点云进行表示,并通过卷积、编码器和解码器等架构来从图像中对点云进行学习和重建。

此外,有的研究人员为了降低直接从图像学习点云的难度,在过程中加入了一些中介,并基于这些中间结果进行重建。下面是一个典型的中间方法,模型首先通过图像估计出目标的表面法向图、深度图和轮廓剪影,并基于这些信息再重建出目标的三维形貌,将一个问题分解成多个子问题是一种处理复杂问题的有效手段。
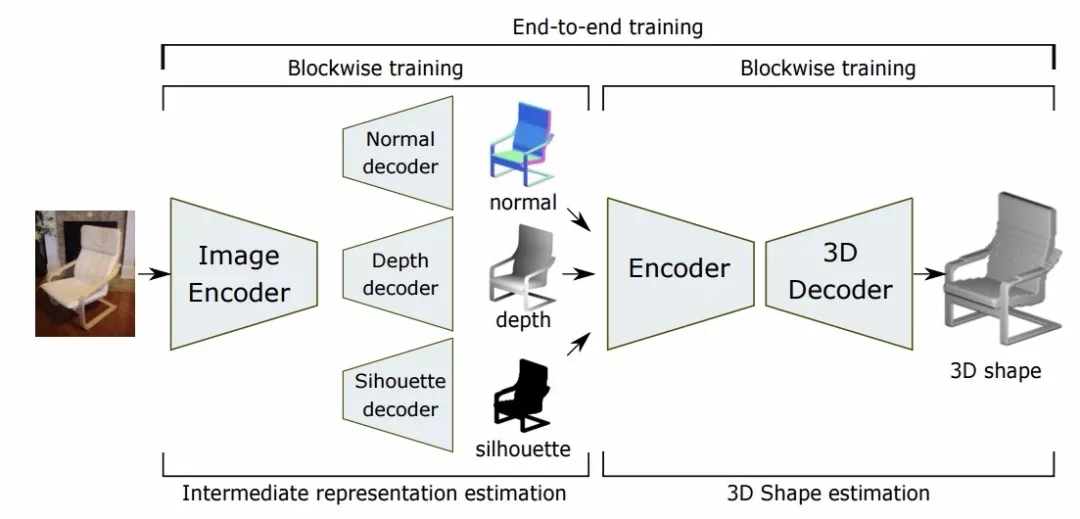
除了直接从图像重建出三维表示,研究人员还加入了一系列其他的线索:首先通过图像生成2.5D的中间信息,随后在利用深度学习或传统方法重建出完整的三维形貌。
除了上述提到的法向量、深度图和掩膜外,研究人员还探索了将深度图投影到球空间中进行图像补全,随后重新投影到三维空间中实现重建;也有研究人员重建出多张不同角度的深度图,同时解码出对应的mask实现三维重建。进一步的方法还有基于变形场的概念来结合深度图进行重建。
同样与空间关系相对,时间联系也可以用来通过图像对物体进行重建。研究人员们提出了基于循环神经网络的增量式重建方法,通过在编码器和解码器间插入LSTM来处理和基于图像序列的特征,并通过多帧输入重建出三维形状;还有研究为了克服序列输入带来的顺序依赖与效率问题,采用了多个并行的编码器解码器架构分别处理时序数据并在最后融合得到优化的三维重建结果。
通常来说基于图像进行三维重建一般分为三个部分,对图像特征的提取也即编码过程、对特征的分析、组合以及最后的三维重建,即解码过程;同时还需要考虑多种不同的损失函数和针对不同任务的训练方法。
针对图像进行三维重建需要从图像中抽取有效的特征并编码成隐空间中的嵌入表示。一个有效嵌入特征应该从二维图像中稳定的抽取,并能够重建出合理的三维形貌。有的研究从图像中直接抽取离散或连续的隐空间特征进行编码,也有的方法利用三维形状来监督二维编码实现隐空间中编码的相似性。有效编码的目的在于重建与图像对应的三维表示。
而重建过程则对应了解码器。针对不同的三维表示形式,解码器的结构也各不相同,包括体素、网格、点云等多种不同的形式。解码器的目的在于从图像中抽取的形状编码中重建出与对应三维目标尽可能接近的形状。为了提高解码器的效率和重建的精度,包括空间剖分、可变性模型等技术被纷纷引入到这一过程中。
为了实现有效的训练和重建,需要引入一系列损失函数作为监督信号。这些监督信号包含了原始的三维表示信号,包括体素表示下的体积损失和点云表示下的点集损失。同时也可以引入一系列2D或2.5D的监督信号,例如不同视角下的图像信号。
将重建出的三维结果投影到对应的二维视角下计算误差是一类常用的做法,包括基于轮廓剪影的误差、基于表面法向量的误差、基于深度的误差,同时也可以将这些误差与三维误差进行加权联合处理。
在训练方法方面,基于图像的三维重建除了通常使用的监督训练方法外,还包括基于对抗的训练方法和联合其他任务的多任务训练方法以获得较好的结果。

训练上述的种类多样的重建方法,数据庞大的数据是必不可少的。研究人员们提出了多种数据集,目前常见的三维数据集包括了ModelNet,ShapeNet这类基于CAD模型的三维数据集,还包括了IKEA,Pix3D等室内家具场景的数据集,还包括PASCAL 3D+和ObjectNet3D等。
但这些数据的设计初衷大都不是为单图像三维重建准备的,大型的CAD数据集缺乏对应的自然图像,而真实数据集则数量较少。研究人员们使用各种数据增强方法来解决这一问题,包括常见的尺度、旋转和裁剪变换以及新视角下的渲染等方法。也有的研究人员通过目标的掩膜来代替对自然图像的三维标记。
下表从各个方面总结了常见的3D数据集。

近年来基于图像的三维重建得到了巨大的发展,可以预见深度学习在二维领域的成功将全面向三维领域深入发展,作者从数据、算法和应用方面提出了一些值得探索的方向。
在数据方面,由于深度学习需要海量的训练数据,希望在大规模的2D-3D标记数据集方面有更多的工作,同时针对弱监督和无监督学习的三维重建也是未来的发展方向。基于域迁移的训练算法也可以解决数据缺乏的问题;
此外模型的泛化性和重建能力需要得到进一步的提升,针对未知类别物体的重建也许可以结合深度学习与传统方法的优势来处理。模型对于细节的重建能力也需要加强,未来对于目标精细形貌的重建探索也值得研究人员们进行努力;
针对特定领域的应用,包括人体、人体部位、人脸、车辆、动物、建筑等可以结合统计模型与深度学习的方法进行重建,这种方法在人脸上已经得到了较多的应用,未来会向各领域进一步发展;
针对多物体和复杂环境方面,需要将目前单物体三维重建拓展到多物体和复杂场景中,从多物体的数据问题训练监督上进行探索;最后针对三维场景的解析和理解,包括场景重建、各个物体的分离与相关性分析,最终实现3D场景的精细语义处理也是值得探索的研究方向!
2D到3D的发展正是我们拓展世界认知的方向,神经网络的能力从图像到空间的进步也将带来更大的技术进步。在深度学习时代,我们一同期待!
ref:
paper:https://arxiv.org/pdf/1906.06543.pdf
http://profiles.murdoch.edu.au/myprofile/hamid-laga/
https://research-repository.uwa.edu.au/en/persons/mohammed-bennamoun
logo image from:
https://dribbble.com/shots/5402244-16-Spheres
https://dribbble.com/shots/6588786-Awesome-Twisted-Shapes-4

 友情链接
友情链接