








选自arXiv
参与:Pedro、王淑婷
自编码器因其优越的降维和无监督表征学习能力而知名,而过去的研究表明自编码器具备一定程度的插值能力。来自谷歌大脑的 Ian Goodfellow 等研究者从这一角度提出了一种新方法,显著改善了自编码器的平滑插值能力,这不仅能提高自编码器的泛化能力,对于后续任务的表征学习也会大有帮助。
1 引言
无监督学习的目标之一是不依靠显式的标注得到数据集的内在结构。自编码器是一种用于达成该目标的常见结构,它学习如何将数据点映射到隐编码中——利用它以最小的信息损失来恢复数据。通常情况下,隐编码的维度小于数据的维度,这表明自编码器可以实施某种降维。对于某些特定的结构,隐编码可以揭示数据集产生差异的关键因素,这使得这些模型能够用于表征学习 [7,15]。过去,它们还被用于预训练其它网络:先在无标注的数据上训练它们,之后将它们叠加起来初始化深层网络 [1,41]。最近的研究表明,通过对隐藏空间施加先验能使自编码器用于概率建模或生成模型建模 [18,25,31]。
某些情况下,自编码器显示了插值的能力。具体来说,通过在隐藏空间中混合编码以及对结果进行解码,自编码器可以生成对应数据点的语义上有意义的组合。这种行为本身就很有用,例如用于创造性应用 [6]。尽管如此,我们还认为它展示了一种广义上的「泛化」能力——这意味着自编码器并不只是简单地记忆如何重建一小部分数据点。从另一个角度来看,它还表明自编码器发现了一些数据的内在结构并在其隐藏空间中捕获了它。这些特点使得插值经常出现在关于自编码器 [5,11,14,26,27,32] 及隐变量生成模型研究的实验结果中 [10,30,38]。基于无监督表征学习 [3] 和正则化 [40] 的插值与「平面」数据流形之间的联系已经被探索过。
尽管插值应用广泛,其定义仍然有些不够明确,因为它的定义依赖于「语义上有意义的组合」的概念。此外,人们也很难直观的理解为什么自编码器应该具有插值能力——用于自编码器的目标或结构都没有明确地对其提出过这种要求。本文主要在自编码器的规范化以及插值改进方面做出了以下贡献:
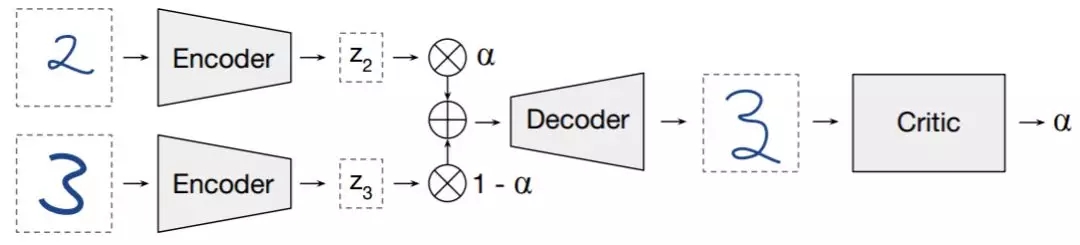
图 1:对抗约束自编码器插值(ACAI)。评估网络试图预测对应于插值数据点的插值系数 α。训练自编码器来欺骗评估网络使输出 α = 0。
论文:Understanding and Improving Interpolation in Autoencoders via an Adversarial Regularizer

论文链接:https://arxiv.org/pdf/1807.07543v2.pdf
通过对隐编码中重建数据点所需的所有信息进行编码,自编码器为学习压缩表征提供了强大的框架。某些情况下,自编码器可以「插值」:通过解码两个数据点的隐编码的凸组合,自编码器可以产生一个语义上混合各数据点特征的输出。本论文提出了一种正则化过程,它鼓励插值输出通过欺骗评估网络(critic network)的方式显得更真实,其中评估网络被训练用于恢复插值数据的混合系数。论文还提出了一个简单的基准测试,可以定量测量各种自编码器可以插值的程度,并表明本文提出的正则化项可以显著改善此设置中的插值。此外,论文还认为正则化项产生的隐编码对后续任务更有效,这表明插值能力和学习有用表征之间可能存在联系。
3 自编码器,以及如何插值
如何衡量自编码器插值是否有效以及正则化策略是否达到其既定目标?如第 2 节所述,定义插值依赖于「语义相似性」的概念,这是一个模糊且依赖于问题的概念。例如,按照「αz_1 + (1 − α)z_2 应该映射到 αx_1 + (1 − α)x_2」定义插值显得过于简单,因为数据空间中的插值通常不会产生真实的数据点——用图像来表现的话,这种情况对应于两个图像像素值之间的简单淡化。然而,我们想要的是自编码器在特征不同的 x1 和 x2 之间平滑地变化;换句话说,是希望沿着插值的解码点平滑地遍历数据的底层流形而不是简单地在数据空间中插值。但是,我们很少能够访问基础数据流。为了使这个问题更加具体,本文引入了一个简单的基准测试,其中数据流形简单且先验已知,这使得量化插值质量成为可能。然后,我们评估各种常见自编码器在基准测试中进行插值的能力。最后,我们在基准测试中测试 ACAI,发现它展示出了显著改善的性能和定性优越的插值。

图 2:合成线数据集中的数据和插值示例。(a) 来自数据集的 16 个随机样本。(b) 从 Λ=11π/ 14 到 0 的完美插值。(c) 在数据空间而不是「语义」或隐藏空间中插值。显然,以这种方式插值会产生不在数据流形上的点。(d) 从一幅图像突然转换成另一幅图像、而不是平滑改变的插值。(e) 平滑插值,从开始到结束点的路径比最短路径更长。(f) 采用正确路径但中间点虚化了的插值。

图 3:以下自编码器在合成线基准上插值的效果:(a) 标准自编码器,(b) 对隐藏空间施加 dropout 的标准编码器,(c) 去噪自编码器,(d) 变分自编码器,(e) 对抗自编码器,(f) 矢量量化变分自编码器,(g) 对抗约束自编码器插值(我们的模型)。

表 1:不同自编码器在合成基准测试中获得的分数(越低越好)。
4 优化表征学习
到目前为止,本文只专注于测试不同自编码器的插值能力。现在,我们想知道改进插值是否与后续任务的性能改进有关。具体来说,我们将评估使用本文提出的正则化项是否会产生隐藏空间表征,从而改善在监督学习和聚类中的表现。换句话说,我们试图测试改进插值是否会影响隐藏表征:它可以揭示数据集产生差异的关键因素。为了回答这个问题,我们在 MNIST [21],SVHN [28] 和 CIFAR-10 [20] 数据集上用不同自编码器训练过的隐藏空间来进行分类聚类测试。
4.1 单层分类器

表 2:不同自编码器达到的单层分类器准确率
4.2 聚类


表 3:在不同自编码器(左)和先前报告的方法(右)的隐藏空间上使用 K-Means 的聚类准确率。右边的「Data」是指直接对数据执行 K-Means。标 * 的结果来自 [16],标 ** 的结果来自 [42]。

图 6:MNIST 上的插值示例,隐维数为 256:(a) 标准编码器,(b)Dropout 编码器,(c) 去噪编码器,(d)VAE,(e)AAE,(f)VQ-VAE,(g)ACAI 自编码器。

图 10:CelebA 上的插值示例,隐维数为 256:(a) 标准编码器,(b)Dropout 编码器,(c) 去噪编码器,(d)VAE,(e)AAE,(f)VQ-VAE,(g)ACAI 自编码器。

 友情链接
友情链接