








公众号/将门创投
编译:T.R

出处:http://bair.berkeley.edu/blog/2018/06/28/daml/
模仿能力是智能重要的组成部分,人和动物常常通过观察其他个体来学习新的技能。那么我们能不能将这种能力赋予机器人呢?是否可以像下图一样,让机器人通过观察人类的操作来学会操作新的物体呢?

机器人在观察人类行为后学会了将桃子放到了红色的碗里
如果拥有这样的能力,将极大地简化部署机器人完成新任务的过程。我们只需要展示给机器人需要进行的任务,而无须进行遥操作或设计复杂的奖励函数。很多工作探索了机器人可以从本身的专业经验中很好的学习,这样的学习方式称为模仿学习。
然而基于视觉技能的模仿学习需要大量专业的示范数据。例如利用原始像素输入来靠近单一固定物体的任务就需要200次表现良好的示范才能达到。如果只提供一个示范样本,要完成这样的模仿对于机器人来说十分困难。
除此之外,如果机器人需要模仿人类的示范的特定操作技能还需要面临额外的挑战。除了机械臂与人类手臂的构造差异外,在人类示范和机器人示范之间建立起正确的对应关系是一件十分困难的事情。这并不仅仅是对运动简单的跟踪和重映射,其中最主要的部分在于运动对环境中物体的影响,并且我们需要建立一个以这种相互作用为中心的对应关系。
为了使得机器人可以模仿视频中人类的技能,可以结合一系列先验经验而不是从零开始学习。通过结合先前的经验,机器人可以迅速学会对于新物体的操作而在域的移动中保持不变性,就像在观察了人类的示范后机器人可以在不同背景和视角下学会操纵物体。研究人员的目标是通过从示范数据中学会学习,来实现少样本的模仿和域不变性。这种被称为元学习的技术是赋予机器人通过观察模仿人类的关键。
One-Shot模仿学习
那么如何利用元学习来帮助机器人快速的适应不同的物体呢?研究人员们采用结合元学习和模仿学习的方式来实现一次模仿学习。关键的想法在于给机器人提供某一特定任务的当个示范,机器人就能迅速的识别任务,并在不同的情形下成功解决。早先的一个工作通过从成千上万个示范中学会学习来实现一次学习,并给出了优秀的结果。如果我们希望一个实际的机器人能够模仿人类并操纵各种各样的新物体,就需要开发一个能从视频数据集的示范中学会学习的系统,而这些数据可以在真实环境中收集。接下来的部分首先讨论了通过遥操作收集的单个示范来实现的视觉模仿,随后展示了这种方法是如何拓展到向人类视频中学习的范畴中去的。
为了让机器人可以从视频中学习,研究人员将模仿学习与一种高效的元学习算法(未知模型元学习,MAML)结合起来。通过标准的神经网络来作为策略表示,在每个时间步长将机器人输入的图像ot和状态信息xt(例如关节的角度和速度)映射到了机器人的行动上at(比如夹爪的线速度和角速度)。下图展示了算法三个主要的步骤。
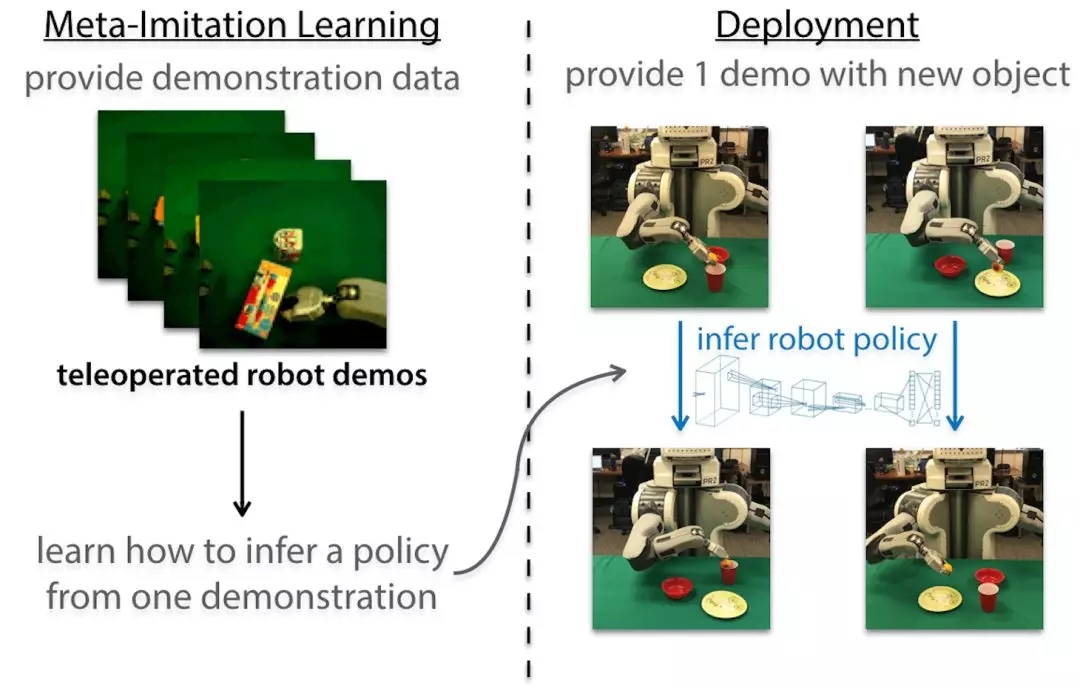
首先人们对于不同任务(操作不同物体)收集了大量操作示范构建了大型数据集;随后利用MAML学习了策略参数θ的初始状态。随后提供某一特定物体的示范时,我们可以基于这一示范来运行梯度下降法来寻找对于这一物体的一般化策略θ’。当使用遥操作示范时,策略可以通过比较预测行动πθ(ot)和专家行为a*t来更新策略:
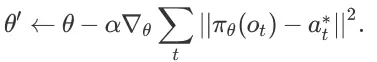
随后通过促使策略πθ’的值来匹配同一物体其他示例的行为,实现对于参数θ的更新。在元训练后,我们就可以利用这一任务的单一示范来计算梯度步骤,从而让机器人去操纵完全没有见过的物体了。这一步骤称为元测试。
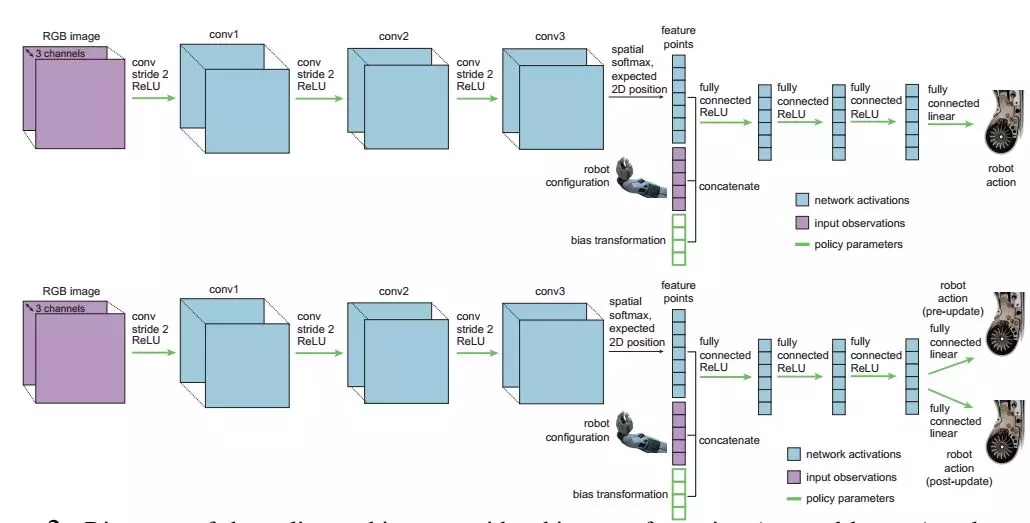
策略架构
由于这一方法没有为元学习和优化引入额外的参数,具有很好的数据效率。因此它可以通过观察遥操作机器人示例实现多样化的控制任务,例如推动和放置等任务。

将物体放到新的容器中去,左图是示范右图是学习后的策略。
上述方法依然是依赖于遥操作机器人的示范而不是人类的示范。为了达到从人类示范学习的目标,研究人员们在上述算法的基础上设计了一种域适应的一次模仿方法。收集了机器人和人执行不同任务的示范,随后通过人类示范来计算策略更新,并用同一任务的机器人示范来评价更新后的策略,算法架构图如下所示:
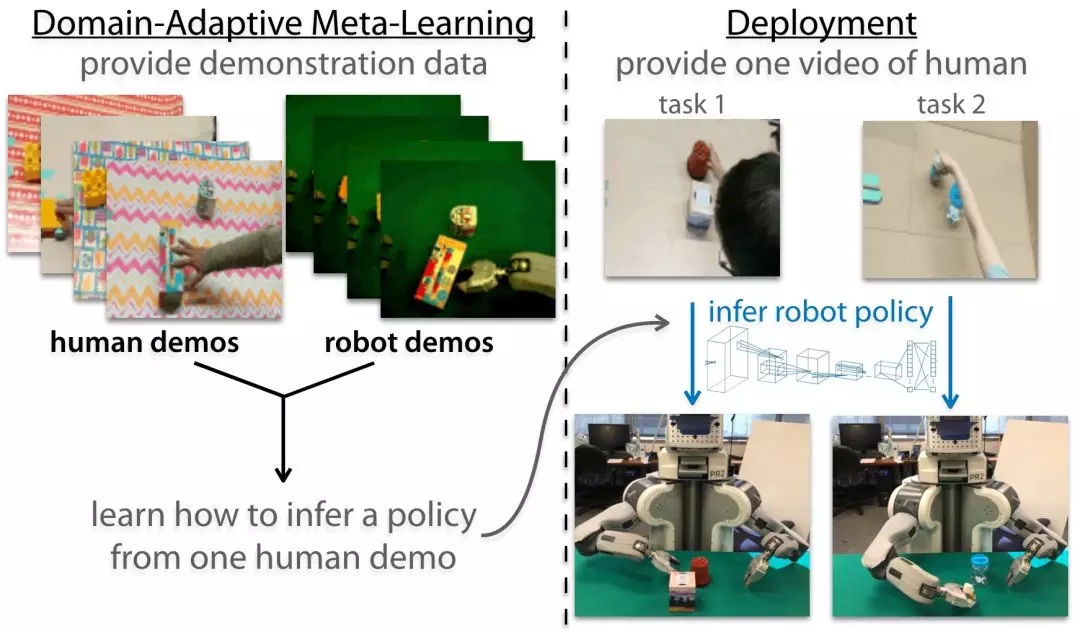
但人类示范只是在执行任务时的视频而已,并不包含对应的行为,无法通过前面的公式计算出损失并更新策略。在这里,研究人员另辟蹊径的提出了用深度学习的方法学习出一个帮助策略更新的损失函数,这个损失函数无需行动作为标记。直接学习损失函数背后的思想来自于,我们可以通过无标签的数据得到损失函数,同时给出正确的梯度用于策略更新,并最终的到一个成功的策略。
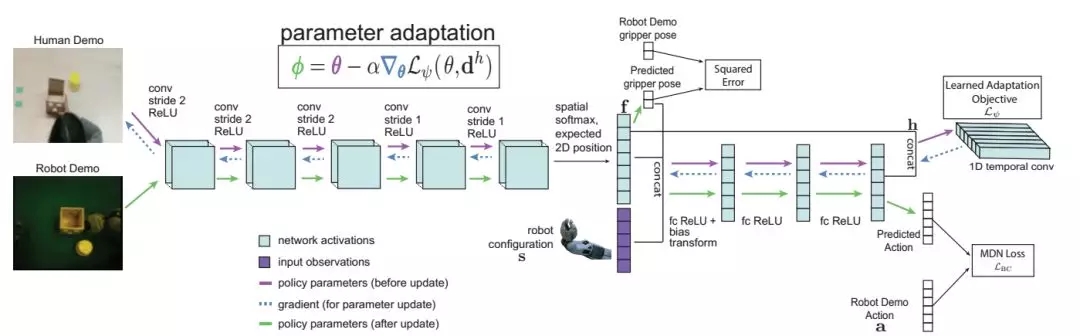
策略架构
这看起来像是不可能完成的任务,但要记住的是元训练过程依旧通过梯度步骤后机器人行为监督着策略的更新。学习损失函数可以被理解为通过抽取场景中适宜的视觉线索来更新参数从而修正策略。所以元训练的行为输出将会产生正确的行动。研究人员利用Temporal卷积来实现了损失函数的学习,可以抽取视频示范中的顺时信息。
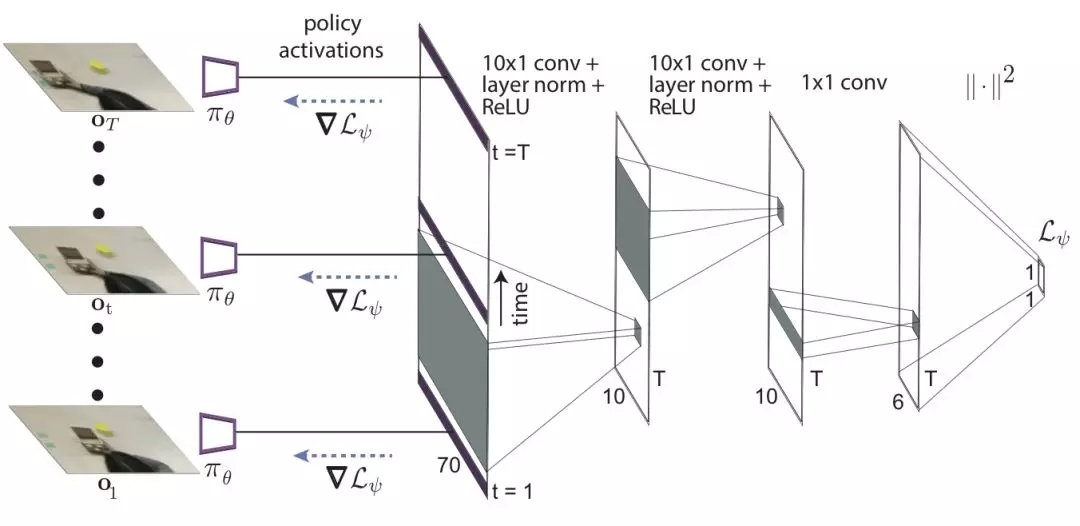
研究人员将这一方法归为具有域适应性的元学习算法,这是因为它可以通过其他域的数据实现学习,而不是机器人的策略操纵空间。这一方法使得PR2机器人高效的学会了如何推动很多不同的物体到目标位置,而这些物体在元训练的过程中是从来没有看到过的。

同时也能通过观察人类对于每个物体的操纵,实现物体的抓取并将其放置到新的目标容器中去:

同时利用不同背景环境和相机拍摄的人类示范来验证算法的有效性, 发现即使相机和背景的变化,算法依旧可以保持良好的表现。

目前已经实现了教会机器人通过观看单个视频就能学习操纵新物体,下一步自然是扩大这种方法的规模,不同的任务对应着完全不同的运动和目标,例如使用不同的工具来进行不同的运动。通过考虑潜在任务分布的多样性,研究人员希望这样的模型可以适用于更广泛的任务,帮助机器人在新环境中迅速的建立起策略。同时这里提到的技术并不仅仅限于机器人操纵或控制,模仿学习和元学习可以用于语言和其他序列化决策过程中。通过少数的示例学会模仿是一个未来一个十分有趣的研究方向。
如果想看论文请参考:
https://arxiv.org/abs/1709.04905
对应代码:https://github.com/tianheyu927/mil
https://arxiv.org/abs/1802.01557

 友情链接
友情链接