








公众号:将门创投

作者 Alison Gopnik
来源:TowardsDataScience
编译:Yulei Fu
人类对于学习具有无可比拟的优秀能力,我们可以从一个简单的样本中学习到整类事物的抽象特征,而算法却需要成千上万的样本来习得认知;我们可以利用已有的概念创造出新的事物。随着人工智能的发展,人们逐渐将研究的重点转移到算法的学习过程和学习的本质上来。
科学家认为机器学习的过程和儿童学习的过程十分相似,都是通过对外界的观察和理解来是实现学习的过程。人工智能专家们正在尝试了解借鉴儿童的思维方式,以便更深入地理解机器认识世界的过程。
通过对儿童行为的仔细观察和分析,科学家们似乎从中找到了一些可以指导未来研究的启发。
在与孩子们长期接触的过程中,我们一定会惊叹于人类快速高效的学习能力。从柏拉图开始,哲学家们就对此问题长期求索而郁郁不得。
你一定记得邻家五岁的小朋友已经对植物、动物、时间、甚至恐龙,宇宙等概念有了初步的了解。在与人的相处过程中,他也学会了揣测别人的心思,意图,和情感。他还会用自己看到和听到的知识来做出新的发现和判断。
通过接受透过视网膜的光子,振动耳膜的声音,小朋友便利用他迷人的大眼睛后的“中央神经处理器”判断出是食草的雷龙只是纸老虎。这个看似简单的问题却困扰着计算机科学家们:如何让电脑也能如人脑般自由流畅的工作?
孩子们只需要老师或家长稍稍指导便可收获储量巨大的知识。尽管近些年来机器学习突飞猛进,但是即使最强大的计算机也无法与一个五岁孩子的学习能力相媲美。
计算机科学家们近十年来努力求索的终极目标便是:解密大脑运转的奥秘,然后创造出一个同样可以有效运转的数字版本的“电脑”。与此同时,他们也在利用已有的知识,在现有的基础上来帮助人工智能更好的运转。
由此开始
在1950到1960之间,人工智能技术经历一轮短暂的爆发式发展后,一直停滞不前。过去几年中,人工智能领域产生了惊人的进步,尤其是把机器学习推向了研究的风口浪尖之中。
许多乌托邦式的预言开始涌现在人们的视野之中,它们设想着人工智能将对世界带来的不朽影响,彻底摧毁或者兼而有之的后果。人工智能的发展引起如此巨大恐慌的原因,也许来源于人类根深蒂固对于“类人”生物的恐惧。从中世纪的傀儡,到科幻小说中的科学怪人Frankenstein,再到2015年电影Ex Machina中的恋爱机器人Ava,无一不反映了对于人造生物会打破人与其他生物之间隔阂的深深恐惧。
但是机器真的可以像人一样学习吗?从人类的想象到彻底的变革之间的距离有多远?脚踏实地的回到解决技术问题中来,让机器准确识别一只猫,一段语言或者一些日本文字这些看似微不足道的任务却也有一定难度。
解决办法之一便是通过使机器能够像孩子一样通过接受透过视网膜的光子、振动耳膜的声音来识别图像和声音一样,来识别计算机所能分辨的数字输入:图像象素点或者声音信号。然后通过某种算法来提取周围环境中的有效信息。
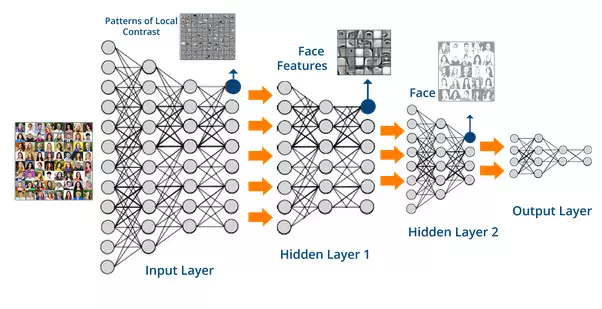
神经网络这种方法的再次复兴来源于深度学习这种新方法的蓬勃发展。现在像Google, Facebook 或者其他科技巨头公司都在产品中广泛应用响应的技术。
正如摩尔定律所述的一样:计算机的力量也随着计算能力的发展而呈指数型增长。快速增长的计算能力,巨大的数据集,对于深度学习的发展有着功不可没的作用。丰富的数据信息,更好的数据处理能力使得计算机系统以超乎我们想象的方式高速发展。
近些年来,人工智能领域在使用“由底向上”或是“由顶向下”两种架构而实现机器学习的矛盾中螺旋前进。“由顶向下”的方法利用系统已知的只是来推论新的知识。柏拉图,或者诸如René Descartes这样理性学派的哲学家们相信,而“由顶向下”的学习方法更加高效适用。在2000年左右,人工智能行业的概率论:贝叶斯模型也经历了重生。“由顶向下”的算法如同科学家们的思考方式一样:基于对客观世界的抽象和假设,来预测数据的正确性。并且根据返回的结论来修正假设的正确性。
如何区分垃圾邮件
自底向上的方法比较容易理解。试想你正试图使电脑自动区分收件箱中的垃圾邮件和正常邮件,你也许会注意到,垃圾邮件有以下特征:一长串收件人,发件地址来自尼日利亚或者保加利亚,提及到超过1百万金额的中奖信息,关键字还有各种广告。但是也许正常邮件中也会包含类似的信息,你可不想错过一次获得升值或者学术奖励的机会。
如果你比较足够多的垃圾邮件和正常邮件,也许你会发现只有垃圾邮件会有以下特点:来自尼日利亚并且提及百万金额的奖金。但是对于垃圾邮件的拦截,也许有更加高级的区分方式:比如错误的拼写加上压根不存在的IP地址。如果你能发现它们,那么你便可以准确的拦截这些垃圾邮件并且不错过你的伟哥订购邮件。

自底向上的方法可以找出有用信息并且解决诸如垃圾邮件拦截这类的任务。为了达到这样的目的,神经网络系统需要进行它的自学习过程。他对一个巨大的数据库进行评估,对其中的样本进行标记,区分垃圾邮件和正常邮件。最后,电脑提取出区分垃圾邮件和正常邮件的一系列特征。
通过相同的方式,神经网络可以区分标记为“猫”或“房子”“剑龙”之类的图片。通过提取相同类别图片的共同属性,来识别从未见到过的新的图片。
另外一种称之为非监督学习的算法也是自底向上方法中的一个分支。但是这种方法并不对数据进行标记,它通过寻找不同聚类中的属性来进行学习。通过对不同的网络节点分配不同的任务,来达到这种深度学习。比如眼睛和鼻子,总是在脸上彼此相邻,而不是以树或者山为背景。
一篇2015年发表于Nature上的文章显示了自底向上方法的优越性。Google持股的DeepMind公司的研究员使用了深度学习与强化学习两种自底向上的手段相结合,开发出了一款能熟练掌握Atari 2600游戏的电脑程序。
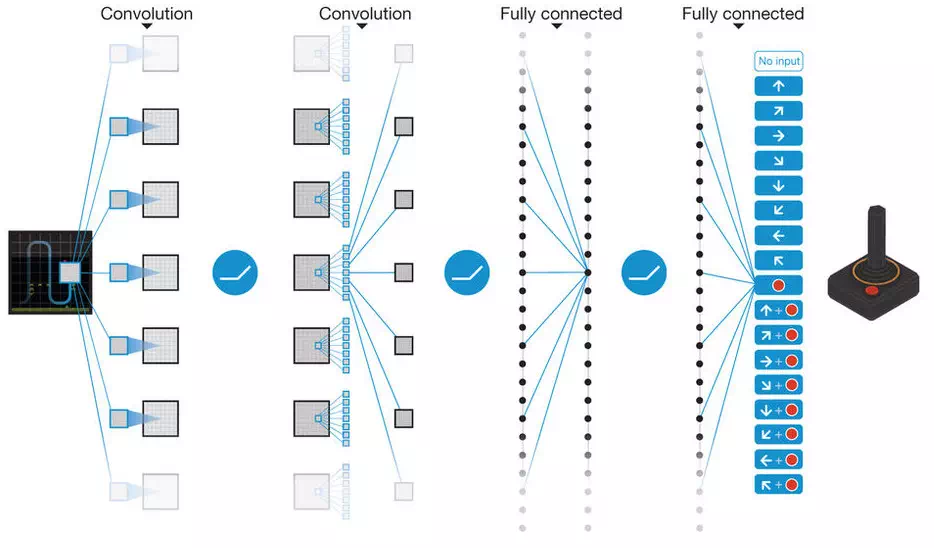
该程序一开始对这款游戏一无所知,它进行随机的尝试并根据反馈信息来决定最佳的移动策略。深度学习帮助该系统识别屏幕中的特征,当它获得高分时,强化学习给出正反馈。通过此种方法,电脑快速的掌握了几款游戏,甚至比专业的人类玩家表现更优秀。对于其他人类易于掌握的游戏来说,人工智能的表现也十分出众.
人工智能从数以百万计的例如ins照片,邮件,或是录音中获取信息,并进一步学习的能力,使得原本看似不可能由机器来完成的问题现在变得易于解决。即便如此,如果我们再回头看看邻居家的小朋友就会惊讶于人类更强大的能力,他可以从极有限的信息和训练中,轻而易举的获得识别动物或是对问题给出回答的能力。对于五岁的孩子来说的简单问题,有些时候对于机器来说依旧是难以解决的。甚至比让它们学会下国际象棋还难。
计算机需要通过大量的数据训练,才能识别出一张长了胡子的大毛脸,而完成此项任务对人类而言不费吹灰之力。虽然计算机可以通过大量的训练识别出一个它从未见过的猫咪图案,但是由于计算机与人类的思维方式不同,依旧有些本是猫咪的图片没有被标记,而另外一些图片被进行了误标记。而这种错误对人类而言基本不可能发生
飞流直下
近些年来,在人工智能领域,另一条解决方法是向着相反的路线而进行的,既:自顶而下。该种方法基于这样一个假设:我们可以从如我们的大脑的工作方式一样,从具体的信息中抽象提取出我们所要的信息,是一种从一般到特殊的过程。我们可以像科学家们一样,运用这些概念与假设来预测未知事物。
为了更好地理解这个概念,我们回到一开始提出的垃圾邮件判别问题中来。我收到了一封来自一个名称奇怪的杂志社编辑的邮件,邮件中提到了我写过的一篇文章并且希望我为该杂志再写一篇文章发表。没有提到:尼日利亚,广告或者百万美金这些概念。似乎与垃圾邮件的特征一点也不吻合。但是通过自顶而下的思考方式,我却很可能把该邮件定性为一封垃圾邮件。
垃圾邮件试图利用人们的贪婪来赚钱,学者们对于发表文章的贪婪和赢得壹佰万元或者获更好的体验的渴望是一样的。合法的开架杂志已经开始从作者方面收钱而不是从读者方面收钱,而且我的工作与这个期刊所覆盖的内容也并没有什么关联。综上所述,我得出了该邮件是为了骗取学者们自掏腰包发表一个山寨期刊的垃圾邮件,通过在搜索引擎中检查该编辑的通讯地址,可以进一步验证推断的正确性。
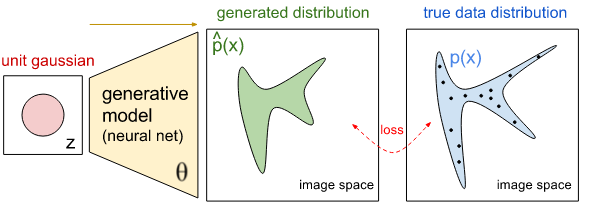
计算机科学家们会把我的思考过程称为“生成模型”。一种能够代表诸如贪婪,欺骗等抽象概念的模型。用此种模型,同样可以推断出一封邮件是否是垃圾邮件。通过该模型,我可以了解到垃圾邮件是如何工作的,也可以使我能够有能力区分其他种类的垃圾邮件。当我收到来自杂志社的邮件时,这个模型让我能一步步推断出某邮件之为垃圾邮件的原因。
在20世纪五六十年代兴起的第一波人工智能浪潮中,生成模型具有不可替代的作用,但是它们也有其限制。首先,大部分模式可以用不止一种假设来解释。比如拿前面我给出的邮件为例,可能那封关于在开架杂志上发表文章的邮件是合法的。所以,生成模型必须与“概率”相伴。概率理论也是最近该领域中的重要研究方法。其次,关于这些概念的来源是未知的,尽管诸如Descartes ,Noam Chomsky 这些思想家们认为这些是我们与生俱来的,但是我们真的生来就明白贪婪或者欺骗会倒置欺诈吗?
以十八世纪的统计学家和哲学家Thomas Bayes而命名的贝叶斯模型,是自顶而下方法中的一个重要分支。试图去弥补生成模型中提到的两个缺点。通过贝叶斯推理的手段结合了生成模型和概率论。概率生成模型可以告诉你在某假设前提成立的条件下,某件事情发生的可能性,举例来说,如果那封邮件是一封骗局那么它可能会吸引贪婪的读者,但是,一个能吸引贪婪读者的消息并不一定都是骗局。贝叶斯模型能够使你在现有假设的基础之上进行精确的计算。
自顶向下的方法更适合我们运用于了解孩子们的学习过程,在过去的十五年中,研究人员们致力于用贝叶斯理论来研究孩子们学习原因和结果关系的发展,预测孩子们在何时何种情况下会形成对于世界的新认知,又是在何种情况下打破这个认知的。
贝叶斯方法也是教会机器像人类一样思考的好方法。识别不熟悉手写字母这项任务对于人来说轻而易举,对于计算机来说却很困难。2015年MIT的Joshua B和纽约大学的Brenden M. Lake以及他们的同事们在Science上面发表了一篇研究,他们设计出了一种可以达到此目的的人工智能系统。
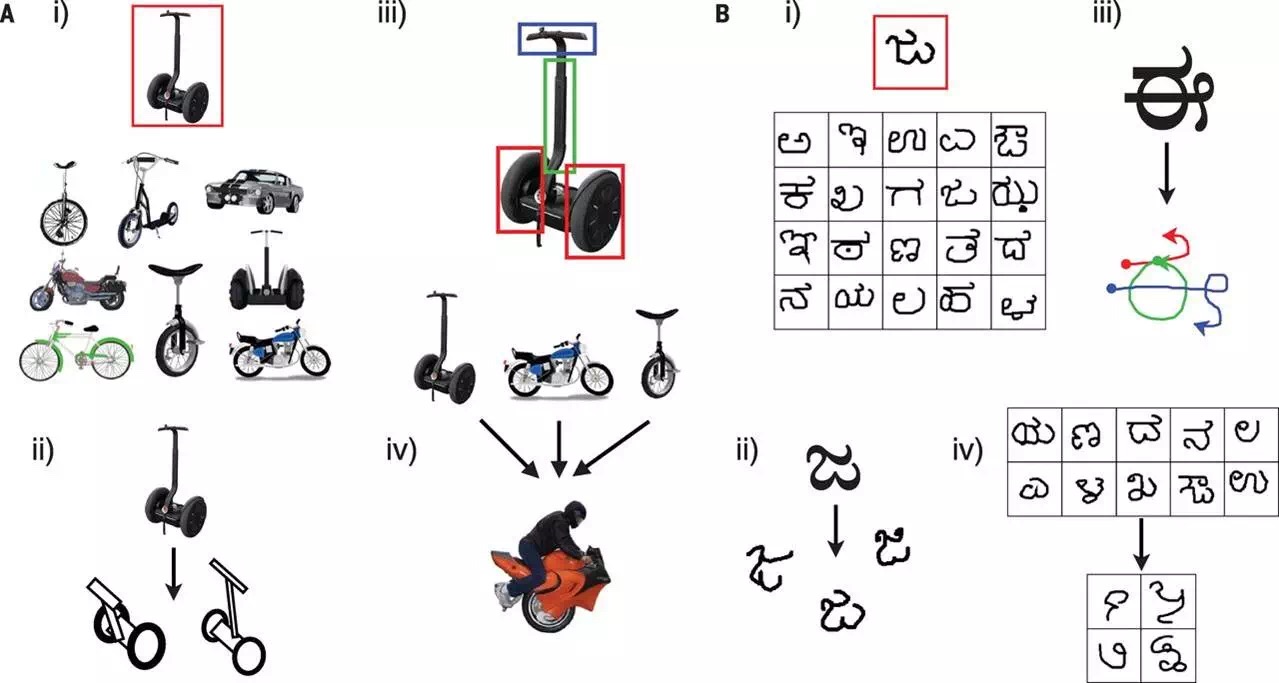
图:学习事物的抽象,并从已有的概念创造新的概念
当我们在日本卷轴画上看到一个从见过的文字时,我们也可以较轻松的分辨出它们与另外一个卷轴上的文字是否是一个体系。你也许能临摹几笔,甚至创造出一个假的日本字。也能非常明确地分辨出它们与韩国文字或俄罗斯文字的不同。Tenenbaum的团队可以利用软件来实现此功能。
对于自底而上的方法而言,计算机需要输入成千上万的历程来学习分辨一种新文字。而使用贝叶斯理论,我们给定机器一种该文字的基本模型;比如:笔画是向左还是向右,当软件识别完其中一个时,它会自动开始识别下一个。当特定的文字被程序识别时,程序推断书写该文字的笔画顺序,并且在内部建立一系列笔画。正如我推断一封邮件是否是诈骗邮件的过程相似。Tenenbaum的这种自顶向下的模型比机器学习模型工作的更好,并且与人类思考的行为契合度更高。
完美的结合
自底向上与自顶向下的两种机器学习的方法,有其各自的优势和劣势。对于自底向上的方法而言,计算机不需要理解什么是猫这个概念,但是却需要大量的信息输入。自顶向下的贝叶斯体系可以从几个例子中总结归纳出经验,但是却需要大量的前期工作,从而做出合理的抽象和假设。两种方法都只能工作在相对较窄的有限领域之内,例如前面提到的识别文字,图片(猫)或是Atari游戏。
孩子们却不会受制于这些约束。发展心理学家们发现,孩子们善于寻找每种方法的优点,并且把它们发扬光大。他们可以从一两个例子中学习提取,如同自顶向下的方法那样,同时他还可以从例子中总结归纳,如同自底下上的方法。
孩子们拥有的能力远不仅限于此,他可以创造出在他的背景知识和经历之外的东西。有的孩子甚至提出,如果一个成年人想返老还童,就应该拒绝食用任何健康的蔬菜,因为孩子们吃了这些而长大变成熟了。我们根本不知道这些新奇的想法是从哪里冒出来的!
当我们面对人工智能也许带来的挑战时,也应该想想人类大脑伟大而神秘的力量。人工智能和机器学习的概念听上去十分吓人,在某种程度上也许确实如此,军队里面甚至已经开始了研制于此相关的武器。无知的愚昧可能会引起比人工智能更加令人恐慌的灾难性后果,人类也需要拥有比过去更高的智慧来应对这些新科技的挑战。相比于对于人类思考方式的认识的颠覆性提高,摩尔法则在现阶段更加具有影响力。随着计算能力的飞速提高,我们不应当新技术视为洪水猛兽,而是要善加利用不断地造福人类。
看惯了神经网络,有兴趣的话可以看看概率论的方法:Josh Tenenbaum个人网站
http://web.mit.edu/cocosci/josh.html
这里还有Nature的论文,描述了DeepMind设计的深度强化学习方法:
https://www.nature.com/articles/nature14236#f1
还有sicence论文,关于实现人类认识水平的概率编程:
http://science.sciencemag.org/content/350/6266/1332/tab-pdf

 友情链接
友情链接