








编辑 | 萝卜皮
深度神经网络(DNN)因其高预测精度已成功用于许多科学问题,但由于其可解释性差,它们在遗传研究中的应用仍然具有挑战性。
在这里,斯坦福大学的研究团队考虑了 DNN 中可扩展、稳健的变量选择问题,用于识别基因组测序研究中推定的因果遗传变异。研究人员发现 DNN 中的特征选择具有明显的随机性,因为它具有随机性,这可能会阻碍可解释性并导致误导性结果。
于是,他们提出了一种可解释的神经网络模型,该模型使用集成进行稳定,并具有用于遗传研究的受控变量选择。
该方法的优点包括:灵活建模遗传变异的非线性效应以提高统计能力;输入层中的多个仿制品,以严格控制错误发现率;分层层以大幅减少权重参数和激活的数量,并提高计算效率;以及稳定的特征选择,以减少识别信号的随机性。
该研究以「Deep neural networks with controlled variable selection for the identification of putative causal genetic variants」为题,于 2022 年 9 月 15 日发布在《Nature Machine Intelligence》。

全基因组测序(WGS)技术的最新进展,引领了探索编码和非编码区域中常见和罕见变异对复杂性状风险的贡献的方式。WGS 研究的一个主要主题是了解疾病表型的遗传结构,并且至关重要的是,为基因组驱动医学的发展提供一组可靠的、定义明确的新靶点。
然而,由于遗传变异的数量庞大、信噪比低以及遗传变异之间的强相关性,在这些数据集中识别因果变异仍然具有挑战性。迄今为止发表的大多数结果都来自边缘关联模型,该模型将感兴趣的结果回归到基因中单个或多个遗传变异的线性效应。
边际关联测试以其简单性和有效性而闻名,但它们通常识别仅与真正的因果变体相关并且可能无法捕捉非线性效应的代理变体,包括但不限于非加性和相互作用(上位)效应,它们被认为代表了与当前全基因组关联研究(GWAS)相关的缺失遗传力的重要组成部分。
最近对阿尔茨海默病(AD)遗传学的研究已经确定了其影响受 APOE 基因型(相互作用效应)调节的基因,例如 GPAA1、ISYNA1、OR8G5、IGHV3-7 和 SLC24A3。此外,Costanzo 团队和 Kuzmin 团队采用系统的方法来绘制基因对之间的遗传学相互作用和高阶相互作用。
结果突出了复杂遗传相互作用影响遗传生物学的潜力;然而,非线性效应的系统分析在过去受到限制,这主要是由于在显式测试全基因组非线性模式中所固有的能力不足和大量的多重测试负担。
为了弥合差距,斯坦福大学的研究人员着重于开发一种新方法来识别给定表型的假定因果变体,同时允许非线性效应以提高功率。
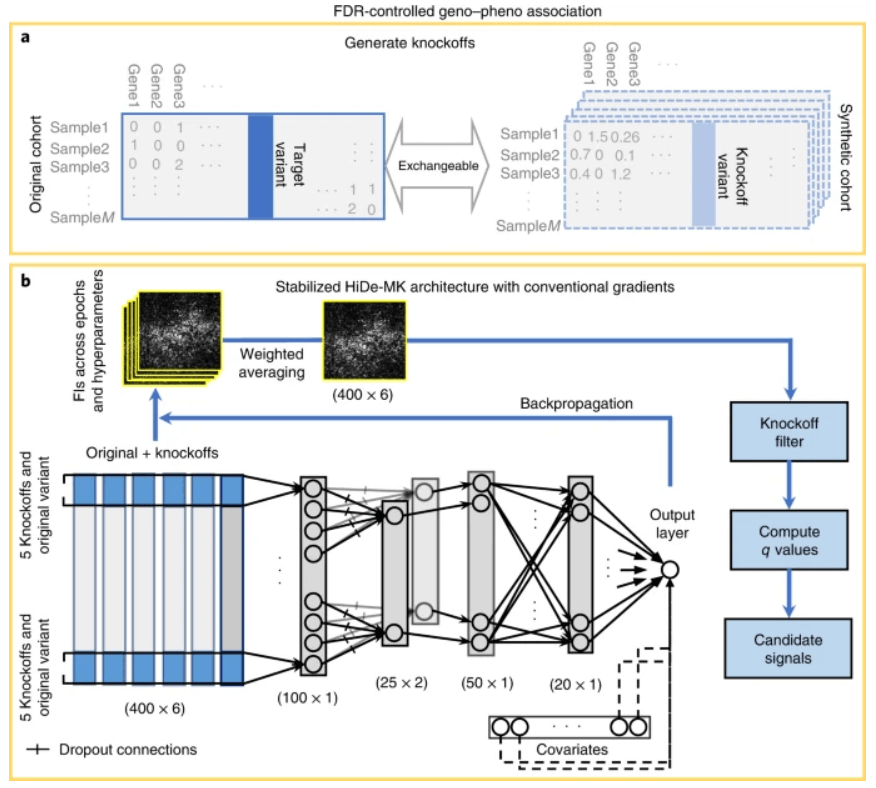
图示:工作流程概述。(来源:论文)
深度神经网络(DNN)可以通过在其框架中使用隐藏层,来有效地学习数据对感兴趣结果的线性和非线性影响,而无需明确指定它们。深度神经网络因其在许多科学问题中的卓越性能而广受欢迎,在许多领域显示出卓越的预测准确性,包括图像研究中的对象检测、识别和分割。尽管现在有大规模的遗传数据可用于潜在地着手进行遗传数据分析的深度学习方法,但 DNN 方法在 WGS 研究中的应用受到限制。将 DNN 广泛应用于遗传数据的一个障碍是它们的可解释性。
与线性回归或逻辑回归不同,由于其多层非线性结构,通常难以确定遗传变异的变化如何影响 DNN 中的疾病结果。尽管已经开发了几种方法来提高神经网络的可解释性并量化输入特征的相对重要性,但大多数方法缺乏对所选特征的错误发现率(FDR)的严格控制。此外,现有方法易受噪声影响且缺乏稳健性。Ghorbani 团队已经证明,小的扰动可以改变特征的重要性,这可能导致对同一数据集的显著不同解释。在最新的研究中,斯坦福大学的研究团队考虑了 DNN 中可扩展的、稳健的变量选择问题,用于识别 WGS 研究中推定的因果遗传变异。
仿冒框架是统计领域的最新突破,专为具有严格 FDR 控制的特征选择而设计。基于仿制品的推理的想法是生成原始特征的合成、嘈杂的副本(仿制品)。在具有原始特征及其仿制品的学习模型中,仿制品用作特征选择的负控制。Model-X 仿制品不需要任何将基因型与表型联系起来的关系,并且对与样本大小相关的特征数量没有限制。因此,它们可以自然地为任何学习方法带来可解释性,包括但不限于边缘关联测试、Lasso 等联合线性模型和非线性 DNN。
值得注意的是,Sesia 团队为基于线性 Lasso 回归的遗传研究提出了 KnockoffZoom。对于非线性 DNN 中的特征选择,Lu 团队提出了基于仿冒的 DeepPINK,而 Song 和 Li 提出了使用概念上相似的代理变量的 SurvNet,但都没有针对当前的基因研究进行优化。
此外,仿冒副本/代理变量是随机生成的,为已经脆弱的 DNN 的解释增加了额外的随机性。He 团队提出了 KnockoffScreen 利用多个仿冒品来提高特征选择的稳定性,但它是建立在遗传研究中传统的边际关联测试之上,没有考虑到遗传变异的非线性和交互作用。
在最新的研究中,斯坦福大学的研究人员将分层 DNN 与多个仿制品(HiDe-MK)相结合,以开发一种可解释的 DNN,用于在具有严格 FDR 控制的基因组测序研究中识别推定的因果变异。除了对增强功率的非线性效应建模和使用多个仿制品来提高稳定性之外,还有三个额外的贡献。
首先,他们提出了一种分层 DNN 架构,该架构适用于分析测序研究中常见和罕见的变体,它还允许调整潜在的混杂因素。与完全连接的神经网络(FCNN)模型相比,新架构所需的参数和激活次数要少几个数量级。
其次,该团队确定了由于测序研究中存在低频和稀有变异而导致的梯度消失问题,并提出了使用指数整流线性单元(ELU)激活函数的实用解决方案。与流行的整流线性单元(ReLU)激活函数相比,这种修改导致功率大幅增加。
第三,研究人员发现 DNN 中的特征选择具有明显的随机性,因为它们具有随机性,这可能会阻碍可解释性并导致误导性结果。
研究人员观察到,具有相同超参数的 DNN 的不同运行会产生不一致的特征重要性得分(FI),尽管预测准确度的差异可以忽略不计。
研究人员通过在 HiDe-MK 的所有 epoch 和超参数中聚合 FI,提出了一种稳定的特征选择。FI 的这种聚合使得对 HiDe-MK 的强大解释成为可能并稳定了特征选择。该团队使用来自 10,797 名临床诊断的 AD 病例和 10,308 名健康对照的数据将所提出的方法应用于 AD 遗传学分析。
通过对模拟数据集进行彻底的实验,验证了回归和分类,在常见和罕见的变体上,研究人员凭经验表明,所提出的方法通过受控的 FDR 提高了功率,并显著提高了 FI 的稳定性。
对于真实数据分析,研究人员将稳定的 HiDe-MK 应用于两个任务;GWAS 的确认阶段,以及 pQTL 的功能知情分析。Stabilized HiDe-MK 确定了线性模型遗漏的几个遗传变异(Lasso with multiple knockoffs,Lasso-MK)。这可能有助于在未来的基因研究中使用复杂的 DNN 发现其他风险变体。

图示:与单次 HiDe-MK 运行相比,Stabilized HiDe-MK 提高了 FI 的稳定性。(来源:论文)
目前,该团队的分析基于假设同质种群的 SCIT 仿制品生成器。扩展到其他血统,特别是少数民族人口或混合人口,尤其具有挑战性。先前的实证研究表明,对于混合种群,可以通过以下方式实现有效的 FDR:(1)根据相应的混合种群数据生成仿制品和(2)将祖先主成分调整为协变量。然而,已经表明,需要考虑人口结构的新仿制生成器才能更好地解决人口分层问题。未来结合这种直接考虑种群结构的新仿冒生成器可以进一步提高所提出方法的性能。
如果目标是特征选择,研究人员观察到预测精度本身不足以作为模型训练的单一标准。具有相似预测精度但 FI 不同的模型在特征选择方面可能具有不同的能力。例如,Lasso 和 Ridge 回归都是线性模型,可以产生相似的预测精度,但 FI 可能有很大不同,因此功率可能会非常不同。目前,研究人员将神经网络中的梯度定义为 FI。未来对神经网络中 FI 的最佳选择的研究将非常有趣。
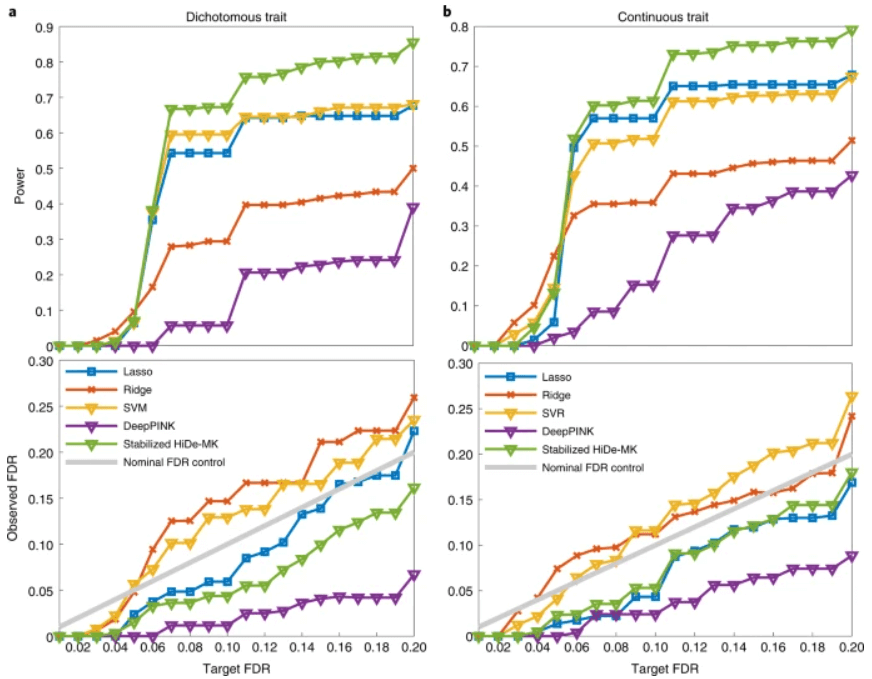
图示:功率和 FDR 比较。(来源:论文)
最后,研究人员发现将 DNN 拟合到包含基因组中的所有遗传变体仍然具有挑战性,尽管与通常的神经网络相比,提出的架构已经取得了实质性的改进,以提高计算效率。因此,当前的分析侧重于使用复制数据集的方法比较。

图示:分层层提高了计算效率。(来源:论文)
开发分布式学习,在未来进一步优化内存使用和计算时间将是有意义的;这样 DNN 可以有效地应用于大规模全基因组分析,以发现全基因组的因果变异。
论文链接:https://www.nature.com/articles/s42256-022-00525-0

 友情链接
友情链接