








公众号/将门创投
From:BAIR 编译: T.R
在过去几年我们见证了基于学习的方法为从感知到推理的一系列任务提供了革命性的解决方案,从图像目标识别到人类语音识别与翻译等等任务都取得了巨大的成功。此外深度学习与强化学习的结合让人们看到深度强化学习可应用于决策领域的巨大潜力。这种方法将有望基于学习的方法解决主动控制任务,包括机器人和自动驾驶的方向的问题,取得与被动感知领域同样的成功。
虽然深度强化学习可以学会令人惊叹的操作技能,但在面对并非来自目标环境的大量广泛数据时训练模型还面临着巨大的挑战。而视觉领域的成功表明,像ImageNet一样的大规模数据集为模型提供了良好的数据基础。那么对于数据驱动的机器人方法也不仅仅需要发展优秀的强化学习算法,同时也需要建立大规模的机器人学数据。
大规模的数据不仅可以有效提升模型的泛化性,同时也可用于预训练模型的训练、随后通过少量数据微调应用于特定的机器人任务。视觉领域ImageNet的预训练模型几乎已经成为了各种视觉问题的标配,那么在主动控制领域特别是机器人领域是否可以建立类似通用的预训练模型和迁移方式呢?
然而,先前的研究表明在机器人学和强化学习领域构建大规模数据集充满了挑战。由于每个机器人的软硬件和实验条件各不相同,人们对于如何构建类似于ImageNet规模的通用数据还不是十分清晰。
基于上述的考虑,研究人员提出了一种通过改变多种不同机器人设置来采集数据的思路。在数据采集过程中会改变相机的视点、环境,甚至机器人平台本身。来自UC Berkeley、Standford、UPenn和CMU的研究人员联合推出了一个可拓展的大规模机器人交互数据集RoboNet。
不同实验室的条件为数据提供了多样性的数据,包括不同的机器人设置、本体和目标对象,还包括不同的相机、视点和采集参数等等。在这一数据集的基础上,研究人员探索了机器人操控领域的预训练方法,在新环境中可以实现比从头训练更为优异的表现。

通过足够丰富的数据来实现预训练强化学习模型,并将知识迁移到不同的环境中去
RoboNet包含了一千五百万个视频帧,由不同机器人和不同目标在桌面环境下收集而成。每一帧都包含了机器人相机采集的图像、机械臂位姿、力传感器读取和夹抓状态。在收集过程中,相机的视角、机器人所面对的物体都不同。

同时研究人员利用自动化的数据收集方式,让大规模的数据采集变得十分便捷和容易,并让多个机构的协作成为可能。下图中可以看到数据集的统计信息:

数据集中的样本和整体统计信息。
在收集多样性的数据集后,研究人员开始探索如何从中学习出可以迁移到新环境中特定任务的通用能力。首先,利用数据集中的一个子集训练了视觉动力学模型,并在未见过的新环境中利用少量新数据进行微调。
下图展示了构建的实验环境,包括不同的实验室环境、新的相机视点和机器人以及在数据收集后新加入的目标物体。

新实验室中构建的测试环境,包括未标定的相机、新的Baxter机器人。虽然在采集数据的时候用过Baxter机器人,但测试时所面对的数据却没有在预训练中使用。
在调优后,研究人员将学习到的动力学模型部署到测试环境中运行包括摆放和抓取等控制任务,使用基于强化学习算法的视觉预估模型。下面的例子显示了机器人在不同环境中执行任务的例子。

通过精调后的视觉预测模型在三个不同环境中进行基本的控制任务。实验中目标机器人和环境利用RoboNet的预训练进行了抽象,而用于适应特定任务的少量调优数据仅仅使用了一个中午就收集完成。
此时就可以通过定量的评测来观察预训练控制器是否比随机初始化更好地获得了通用的能力。在每一个环境中,使用了标准的测评任务来比较基于预训练模型调优的方法和仅仅使用新环境数据进行训练的方法。
结果表明基于预训练模型的调优结果比没有使用预训练方法对于任务的完成率高四倍。更令人惊叹的是,预训练模型调优后比用大量数据(5-20倍的数据量)从头训练的方法还要好,这意味着机器人成功地从RoboNet的预训练模型中实现了知识迁移,并在新环境中得到了较大的增益。
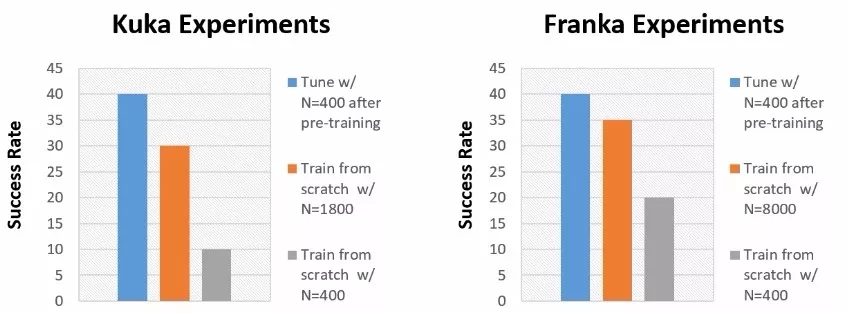
两个不同环境下,调优模型与从头开始训练的性能比较,其中蓝色是预训练调优模型的结果。
的确,基于预训练的调优比从头开始要好,那么预训练模型是不是需要在所有的RoboNet数据上进行训练呢?为了回答这一问题,研究人员们比较了利用不同RoboNet的子数据来进行预训练的模型,与不同的从头开始训练的模型进行比较。
研究人员发现,对于Baxter的实验中,基于Sawyer数据的预训练模型要表现更好。
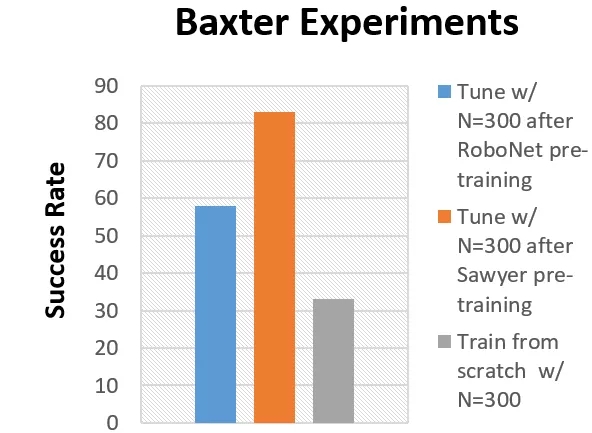
Baxter和Sawyer之间的相似性部分地解释了这一结果,毕竟是同一家公司生产的机器人。但另一个问题却引起了研究人员的疑惑,为何简单的在训练集上叠加数据会让调优的性能下降呢?通过理论上的分析,发现这一问题主要是由于模型欠拟合的缘故。换句话说,RoboNet对于视觉动力学模型来说是一个十分具有挑战的数据,模型预测的不完美造成了控制上的不良影响。
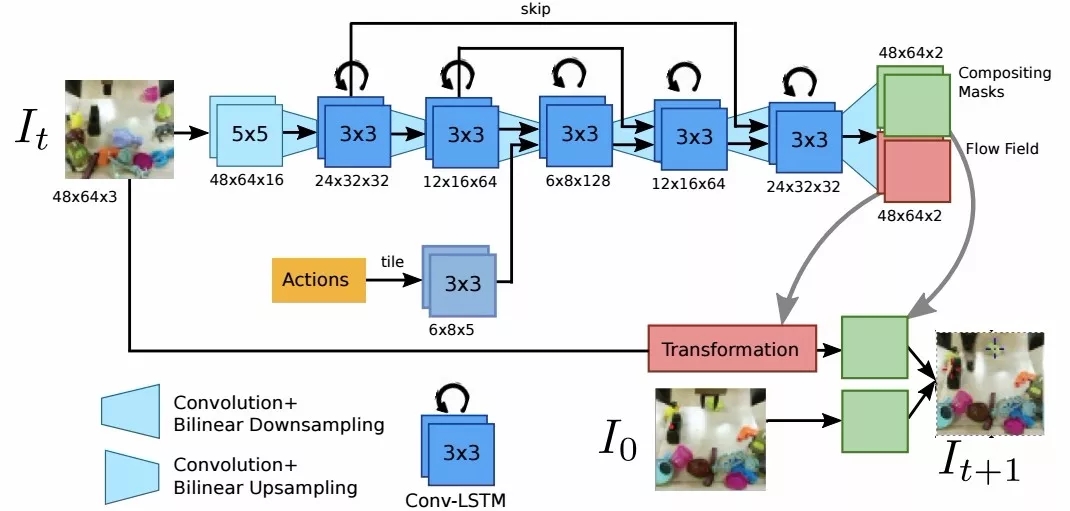
然而参数更多的大模型会更强大,预测结果更好。下图显示了随着模型参数量的增加,预测结果也在变好。但即使增加到500M的参数,中间列的预测结果却依旧模糊。这说明这一实验还有很大的提升空间,未来新的模型将会发展出更为强大的迁移能力和控制表现。

不同大小模型下的视觉预测模型性能比较。右侧是75M参数,中间是500M参数,预测效果更好。
https://github.com/SudeepDasari/RoboNet/wiki/Getting-Started

 友情链接
友情链接