








公众号/
编辑 | 萝卜皮

自然科学中的生成模型已经取得了巨大进步,但它们的可控性仍然具有挑战性。分子、蛋白质生成模型的一个巨大缺陷是缺少连续属性的归纳偏差。
IBM 欧洲研究院和苏黎世联邦理工学院的研究人员提出了 Regression Transformer(RT),这是一种将回归抽象为条件序列建模问题的方法。这为多任务语言模型引入了一个新方向——无缝桥接序列回归和条件序列生成。
尽管该团队使用了限定规模的训练目标,但是 RT 在小分子、蛋白质和化学反应的特性预测方面的性能,可与传统回归模型的性能相匹配,甚至超越。重要的是,启动具有连续属性的同一模型,会产生一个有竞争力的条件生成模型;该模型在子结构约束、属性驱动的分子生成基准测试中优于已有方法。
该研究以「Regression Transformer enables concurrent sequence regression and generation for molecular language modelling」为题,于 2023 年 4 月 6 日发布在《Nature Machine Intelligence》。

现在,Transformers 在自然语言处理(NLP)中无处不在,并且在蛋白质语言建模方面也取得了巨大成功。Transformers 的发明与机器学习中归纳偏差的稳步下降保持一致,这一趋势始于深度学习的兴起:卷积神经网络在对象识别方面优于传统的特征描述符,自我注意广义密集层学习样本相关而不是静态仿射变换,Transformer 利用自我注意取代递归神经网络作为 NLP 中的事实标准。
视觉 Transformers 的成功,动摇了图像处理中平移等变性的必要性;现在,即使是在文本上预训练的冻结 Transformers 也能在对象检测和蛋白质分类方面取得优异的结果。鉴于 Transformer 是当下最通用的模型(即,具有多头注意力的图神经网络作为完整图的邻域聚合),因此尝试将强化学习等整个领域抽象为序列建模,从而利用 Transformers 的方式也就不足为奇了。
减少归纳偏差的下一步可能是避免将「目标变量」显式建模为「输入变量函数」。在调整 Transformers 中特定于任务的语言头时,并不遵循这种判别式建模方法,而是学习输入和目标变量的联合分布,这样可以有效地进一步模糊预测和条件生成模型之间的界限。这种方法的可行性,可以通过置换语言建模 (PLM) 进行评估;PLM 是屏蔽语言建模对自回归模型的扩展。
这种二分模型(同时擅长回归和条件序列生成)超出了对化学和材料设计相关的 NLP 中的应用。分子通常标有连续属性(例如,药物功效或蛋白质溶解度),并且设计任务与生物、物理、化学属性交织在一起。但是,尽管深度生成模型在分子和蛋白质设计中兴起,但目前的方法中「开发属性预测器」和「生成模型」仍然是独立分开的。
基于 Transformer 的架构已广泛用于化学任务,但侧重于属性预测或条件分子设计。通常,科学家采用大规模的自我监督预训练,然后对不同的任务进行微调,但只有 Irwin R 团队的 ChemFormer 解决了回归和目标分子生成问题。然而,ChemFormer 调整了任务特定的头,因此没有构成一个真正的多任务模型,可以无缝地纠缠两个任务。
这种语义差距在各种架构风格(例如,生成对抗网络 (GAN)、强化学习、变分自动编码器 (VAE)、图神经网络 (GNN)、流和扩散模型)中持续存在。然而,有些模型通过概率重新参数化执行属性驱动生成,直接优化属性预测模型的输入。尽管如此,现有的 Transformer 要么调整特定于任务的头部,要么将两个模块之间的通信限制为奖励/损失,因此无法将约束结构生成与属性预测「纠缠」在一起。
IBM 欧洲研究院和苏黎世联邦理工学院的研究人员,通过将回归重新表述为序列建模任务的方式来缩小这一差距。他们提出了 Regression Transformer (RT),一种新颖的多任务模型,可以在数字和文本标记的组合上进行训练。
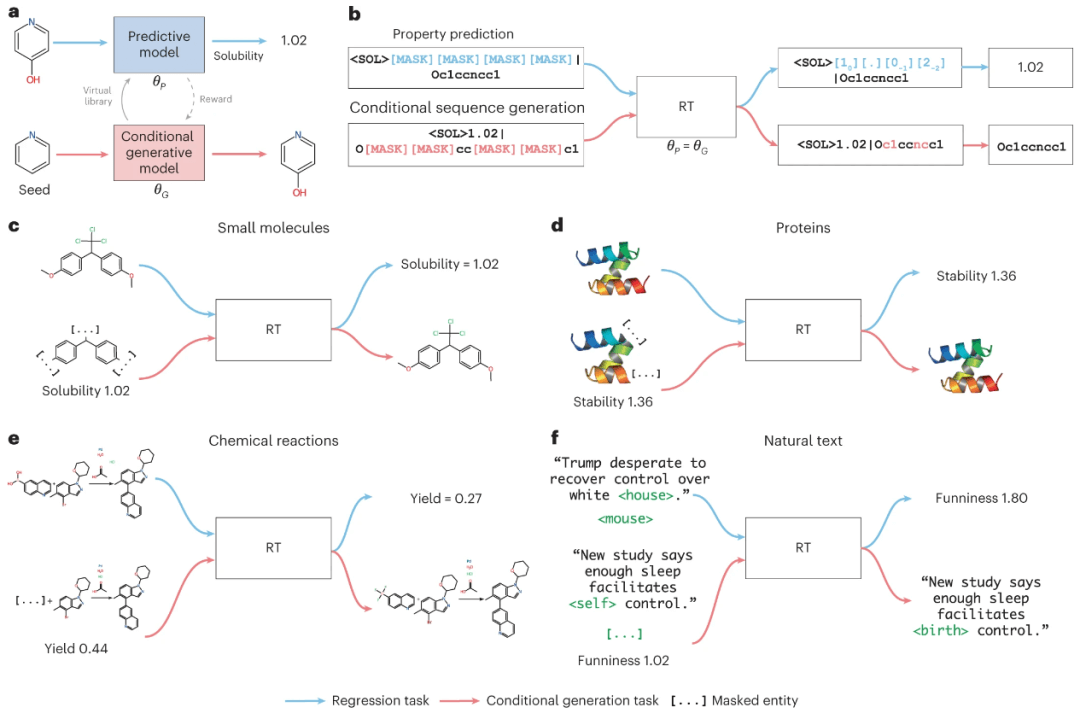
图示:Regression Transformer 概述。(来源:论文)
这绕过了 Transformers 中处理回归的规范方法,即调整指定的回归头。仅依靠数字标记化和交叉熵损失,RT 便成功解决回归任务。值得注意的是,同一模型可以在给定连续属性的情况下有条件地生成文本序列。这只需移动 [MASK] 位置即可实现,不需要微调特定头部,从而构成真正的多任务模型。
为了使 RT 具有处理浮点属性的归纳偏差,首先将数字标记化为一系列保留十进制顺序的标记。然后,研究人员设计数字编码 (NE) 来告诉模型这些标记的语义接近度。为了允许同时优化回归和条件生成,研究人员推导出一种受 PLM 启发的交替训练方案,其中包括一种新颖的自洽 (SC) 损失,用于改进基于连续引物的文本生成。
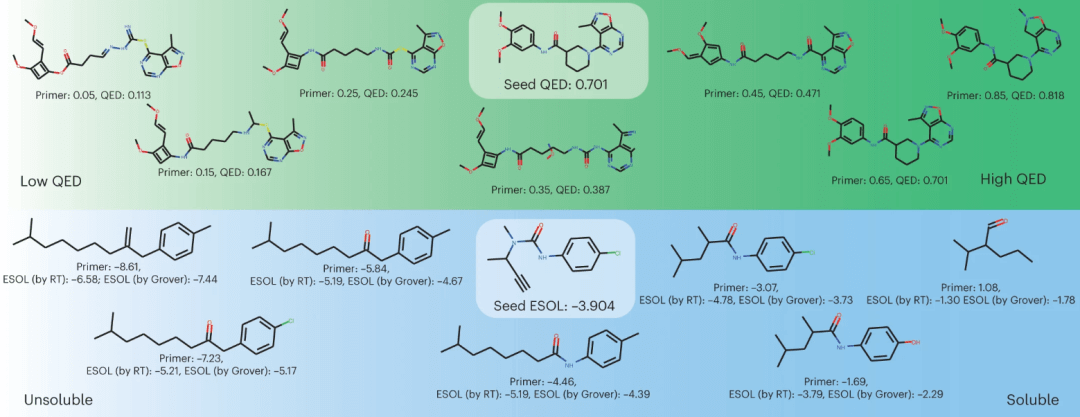
图示:使用 RT 对分子设计进行属性驱动的局部优化。(来源:论文)
研究人员测试了 RT 在化学和蛋白质语言建模中的各种预测和生成任务的能力。从小分子建模开始,在药物相似性的合成数据集上验证 RT,然后在来自 MoleculeNet 基准测试的三个属性预测数据集上对其进行测试。将属性预测结果与以前依赖回归损失的方法进行比较,并证明回归可以作为条件序列生成任务进行转换而不会损失准确性。
这些实验依赖于 SELFIES,一种为生成任务设计的化学语言。RT 具有与 SMILES 相当的预测能力。
另外,研究人员改进并设计了一个在优化属性预测和文本生成之间交替的训练方案。进而推导出一种新的 SC 损失,它通过使用生成的候选序列查询自身来利用 RT 的二分法。为了评估条件序列生成的性能,研究人员系统性地改变了所期望的连续属性,并研究了模型根据初始属性值调整种子序列的能力。
研究人员通过装饰具有连续属性的支架,来展示属性驱动的局部化学空间探索的应用,并使用 RT 本身以及独立的属性预测器评估新分子。
关于分子特性预测,RT 即使从小数据集也能学习连续特性,在几个基准测试中超过了传统的回归模型,有时甚至可以与在回归损失上训练的 Transformers 竞争。值得注意的是,这是在不提供有关属性的比率尺度信息的情况下实现的,甚至可能挑战使用回归而不是分类目标的必要性。
关于条件文本生成的实验强调了 RT 的多功能性。在广泛的任务中,该团队有条件地生成了新的序列(分子、蛋白质和反应),这些序列似乎具有启动的、连续的特性。约束分子生成基准上的实验进一步证明了 RT 可以超越专门的条件生成模型。
研究人员认为这将影响属性驱动和子结构约束的分子或蛋白质设计任务。在近期文献中,RT 已经应用于聚合物化学中,用于生成新型开环聚合催化剂以及嵌段和统计共聚物。这些成功的实验验证,证实了 RT 具有加速发现工作流程的能力。
在 XLNet 上构建 RT 时,任何结合了屏蔽语言建模 (MLM) 和因果、自回归语言建模优势的解码器都可以作为主干(例如,带有标记标记的 T5、MPNet、InCoder 或 FIM)。未来的工作可以评估此类主干上的 RT,加强反应建模工作(RT 有效地推广正向反应和逆向合成模型),提高 RT 执行细粒度回归的能力。另一个前景是探究属性受限但 unseeded 的分子生成。该研究可以成为加速科学发现应用程序基础模型开发的一种手段。
论文链接:https://www.nature.com/articles/s42256-023-00639-z

 友情链接
友情链接