








公众号/
编辑/绿萝
数据集为 AI 模型提供燃料,例如汽油(或电力)为汽车提供燃料。无论他们的任务是生成文本、识别对象还是预测公司的股价,人工智能系统都通过筛选无数示例来识别数据中的模式来「学习」。例如,可以训练计算机视觉系统通过查看特定类型的服装(如外套和围巾)来识别该服装的不同图像。
除了开发模型之外,数据集还用于测试训练有素的 AI 系统,以确保它们保持稳定,并衡量该领域的整体进展。在某些开源基准测试中名列前茅的模型被认为是该特定任务的最新技术 (SOTA)。事实上,这是研究人员确定模型预测强度的主要方式之一。
但是这些人工智能和机器学习数据集——就像设计它们的人类一样——并非没有缺陷。研究表明,许多用于训练、基准测试和测试模型的库都存在偏见和错误,这凸显了过分信任未经彻底审查的数据的危险——即使数据来自自吹自擂的机构。
1. 训练困境
在 AI 中,基准测试需要比较为同一任务设计的多个模型的性能,例如在语言之间翻译单词。这种做法起源于学术界探索人工智能的早期应用,具有围绕共同问题组织科学家的优势,同时有助于揭示已经取得了多少进展。理论上是这样。
但是在数据集选择中变得目光短浅是有风险的。例如,如果将相同的训练数据集用于多种任务,则数据集不太可能准确反映模型在现实世界中看到的数据。未对齐的数据集会扭曲科学进步的衡量标准,导致研究人员相信他们的工作比实际情况要好——并对现实世界中的人们造成伤害。
加州大学洛杉矶分校和谷歌的研究人员在最近发表的一项名为「减少、重用和回收:机器学习研究中数据集的生命」的研究中调查了这个问题。他们发现机器学习中存在「大量借用」数据集——例如,从事一项任务的社区可能会借用为另一项任务创建的数据集——引发了对错位的担忧。他们还表明,只有十多所大学和企业负责创建数据集,这些数据集在机器学习中使用的时间超过50%,这表明这些机构正在有效地塑造该领域的研究议程。

论文链接:https://openreview.net/pdf?id=zNQBIBKJRkd
「追逐 SOTA 一种糟糕的做法,因为有太多混杂的变量,SOTA 通常没有任何意义,科学的目标应该是积累知识,而不是特定玩具基准的结果,」谷歌 Brain 团队的前成员 Denny Britz 在之前的一次采访中告诉 VentureBeat(https://venturebeat.com/2020/06/01/ai-machine-learning-openai-gpt-3-size-isnt-everything/)。「已经有一些改进措施,但寻找 SOTA 是一种快速简便的审查和评估论文的方法。像这样的事情根植于文化中,需要时间来改变。」
就他们而言,ImageNet 和 Open Images——来自斯坦福和谷歌的两个公开可用的图像数据集——在很大程度上以美国和欧洲为中心。在这些数据集上训练的计算机视觉模型在来自南半球国家的图像上表现更差。
即使北半球和南半球之间的太阳路径差异和背景风景的变化也会影响模型的准确性,相机模型的不同规格(如分辨率和纵横比)也会影响模型的准确性。天气条件是另一个因素——专门针对阳光明媚的热带环境数据集训练的无人驾驶汽车系统,如果遇到雨雪天气,其性能会很差。
麻省理工学院最近的一项研究表明,包括 ImageNet 在内的计算机视觉数据集包含有问题的「无意义」信号。对它们进行训练的模型遭受「过度解释」的困扰,这种现象是他们对缺乏细节的高置信度图像进行分类,以至于它们对人类毫无意义。这些信号可能会导致现实世界中的模型脆弱,但它们在数据集中是有效的——这意味着使用典型方法无法识别过度解释。
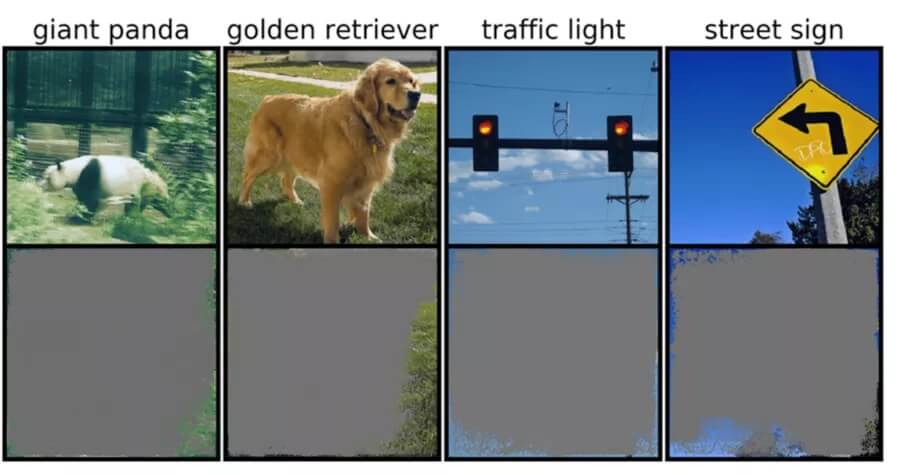
「问题是,我们如何修改数据集,使模型更接近于模拟人类对图像的分类,从而有望在这些真实世界的场景中更好地泛化,比如自动驾驶和医疗诊断, 这样模型就不会有这种荒谬的行为。」麻省理工学院博士生、该研究的主要作者 Brandon Carter 在一份声明中说。
历史上有很多例子表明,使用有缺陷的数据集训练的模型,比如虚拟背景和不利于肤色较深的人的照片裁剪工具,会产生什么样的后果。2015年,一名软件工程师指出,谷歌 Photos 中的图像识别算法给他的黑人朋友贴上了「大猩猩」的标签。非营利组织 AlgorithmWatch 显示,谷歌的 Cloud Vision API 一度将黑人手持的体温计标记为「枪」,而将浅肤色的人手持的体温计标记为「电子设备」。
不可靠的数据集还导致模型使性别歧视招聘和招聘、年龄歧视广告定位、错误评分以及种族主义累犯和贷款批准长期存在。这一问题延伸到医疗保健,其中包含医疗记录和图像的训练数据集主要来自北美、欧洲和中国的患者——这意味着模型不太可能适用于代表性不足的群体。这种不平衡在商店扒手和武器识别计算机视觉模型、工作场所安全监控软件、枪声检测系统和「美化」过滤器中很明显,这些都放大了他们所训练的数据存在的偏差。
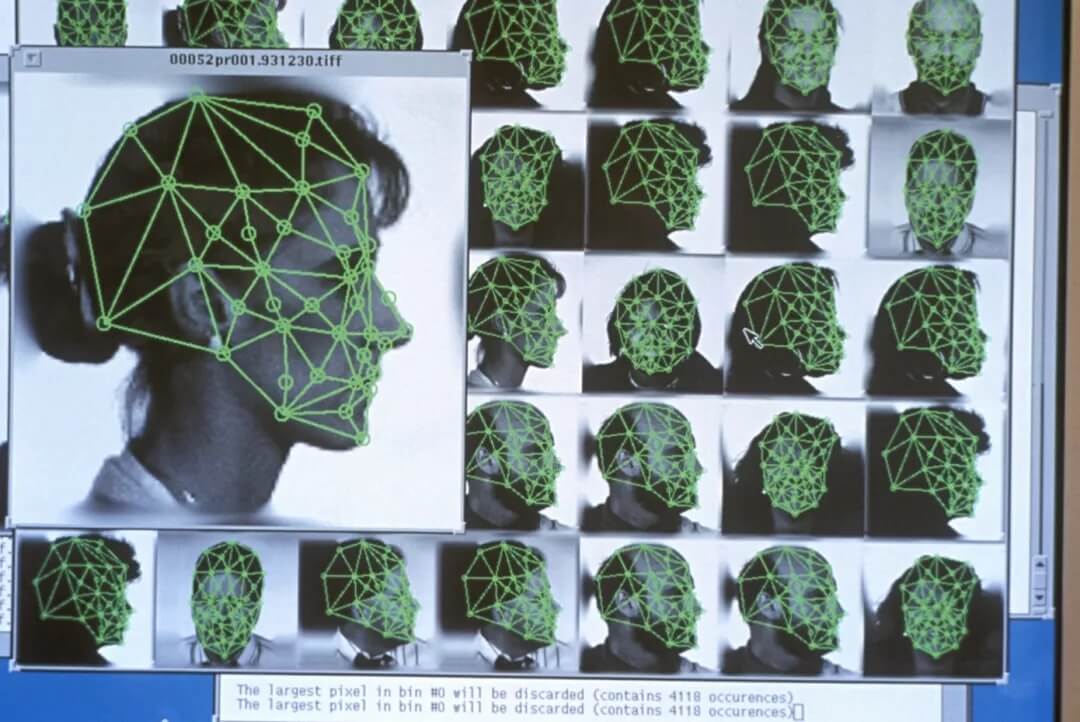
专家们也将面部识别、语言和语音识别系统中的许多错误归因于用于训练模型的数据集的缺陷。例如,马里兰大学的研究人员进行的一项研究发现,亚马逊、微软和谷歌的面部检测服务在年龄较大、肤色较深的人和不太「女性化」的人身上更容易失败。根据算法正义联盟的语音消除项目,来自苹果、亚马逊、谷歌、IBM 和微软的语音识别系统共同实现了黑人语音 35% 和白人语音 19% 的单词错误率。语言模型已被证明会表现出种族、民族、宗教和性别方面的偏见,将黑人与更多的负面情绪联系起来,并与「黑人对齐的英语」作斗争。
「数据从网络上的许多不同地方 [在某些情况下] 被抓取,并且网络数据反映了与霸权意识形态(例如,白人和男性主导地位)相同的社会层面的偏见和偏见,」加州大学洛杉矶分校 Bernard Koch 和雅各布 Jacob G. Foster 以及谷歌的 Emily Denton 和 Alex Hanna,他们是「减少、再利用和回收利用」一书的合著者,他们通过电子邮件告诉 VentureBeat。「更大的……模型需要更多的训练数据,而清理这些数据和防止模型放大这些有问题的想法一直是一个难题。」
2. 标签问题
标签(许多模型从中学习数据关系的注释)也带有数据不平衡的特征。人类在训练和基准数据集中对示例进行注释,为狗的图片添加「狗」等标签或描述风景图像中的特征。但是注释者带来了他们自己的偏见和缺点,这可能会转化为不完美的注释。
例如,研究表明,普通注释者更有可能将非裔美国人白话英语(AAVE)中的短语标记为有毒,这些短语是一些美国黑人使用的非正式语法、词汇和口音。在另一个例子中,麻省理工学院和纽约大学的 8000 万个微型图像数据集的一些标签器(该数据集于 2020 年离线)提供了种族主义、性别歧视和其他攻击性注释,包括近 2,000 张用 N 字标记的图像和诸如「强奸嫌疑犯」之类的标签 和「儿童骚扰者」。
2019 年,《连线》杂志报道了 Amazon Mechanical Turk 等平台对自动化机器人的敏感性——许多研究人员在该平台上招募了注释者。即使员工是可验证的人,他们的动机也是薪酬而不是利息,这可能会导致数据质量低下——尤其是当他们受到不良待遇且薪酬低于市场水平时。包括 Niloufar Salehi 在内的研究人员已经尝试通过像 Dynamo 这样一个开放访问工人集体的努力来解决 Amazon Mechanical Turk 的缺陷,但他们能做的只有这么多。
作为人类,注释者也会犯错误——有时是重大错误。在麻省理工学院对包括 ImageNet 在内的流行基准的分析中,研究人员发现错误标记的图像(例如一种狗被混淆为另一种)、文本情绪(例如亚马逊产品评论实际上是正面的却被描述为负面)和 YouTube 视频的音频(就像 Ariana Grande 高音被归类为哨子一样)。
一种解决方案是推动创建更具包容性的数据集,例如 MLCommons 的人民语音数据集和多语言口语语料库。但策划这些既费时又昂贵,通常价格高达数百万美元。自 2017 年推出以来,Mozilla 致力于构建开源转录语音数据集 Common Voice 仅审查了数十种语言——这说明了它面临的挑战。
创建数据集如此昂贵的原因之一是高质量注释所需的领域专业知识。正如机器之心(Synced)在一篇文章中指出的那样,大多数低成本的标签器只能注释相对「低语境」的数据,而无法处理「高语境」数据,例如法律合同分类、医学图像或科学文献。事实证明,司机往往比没有驾照的人更有效地标记自动驾驶数据集,而且医生、病理学家和放射科医生在准确标记医学图像方面表现更好。

参考地址:https://medium.com/syncedreview/data-annotation-the-billion-dollar-business-behind-ai-breakthroughs-d929b0a50d23
机器辅助工具可以在一定程度上通过消除标签过程中的一些重复性工作而有所帮助。其他方法,如半监督学习,有望通过使研究人员能够在为特定任务设计的小型定制数据集上「微调」模型来减少训练模型所需的数据量。例如,在一篇博文中,OpenAI 表示,它通过复制人类如何在线研究问题的答案(例如,提交搜索查询、点击链接、和上下滚动页面)并引用其来源,允许用户提供反馈以进一步提高准确性。
还有其他方法旨在用部分或完全合成数据替换现实世界的数据——尽管陪审团对合成数据训练的模型是否可以匹配其现实世界数据对应物的准确性尚无定论。麻省理工学院和其他地方的研究人员已经尝试在视觉数据集中单独使用随机噪声来训练对象识别模型。
理论上,无监督学习可以一劳永逸地解决训练数据的困境。在无监督学习中,算法受制于不存在先前定义的类别或标签的「未知」数据。但是,尽管无监督学习在缺乏标记数据的领域表现出色,但这并不是弱点。例如,无监督的计算机视觉系统可以识别未标记训练数据中存在的种族和性别刻板印象。
3. 一个基准问题
AI 数据集的问题不仅限于训练。在维也纳人工智能和决策支持研究所的一项研究中,研究人员发现 3,800 多篇 AI 研究论文中的基准不一致——在许多情况下,可归因于没有强调信息指标的基准。Facebook 和伦敦大学学院的另一篇论文表明,在「开放域」基准测试中,自然语言模型给出的 60% 到 70% 的答案隐藏在训练集中的某个地方,这意味着模型只是记住了答案。
在由纽约大学 AI Now 研究所的技术研究员 Deborah Raji 共同撰写的两项研究中,研究人员发现,像 ImageNet 这样的基准经常被「错误地提升」,以证明超出其最初设计任务范围的声明是合理的。根据 Raji 和其他合著者的说法,这不考虑「数据集文化」会扭曲机器学习研究的科学这一事实——并且缺乏对数据主体的关怀文化,导致恶劣的劳动条件(例如注释者的低薪)未能充分保护数据被有意或无意地清除到数据集中的人。
针对特定领域提出了几种基准测试问题的解决方案,包括艾伦研究所的 GENIE。独特的是,GENIE 结合了自动和手动测试,根据预定义的、特定于数据集的流畅性、正确性和简洁性指南,为人类评估员分配探测语言模型的任务。虽然 GENIE 价格昂贵——提交一个用于基准的模型大约需要 100 美元——但艾伦研究所计划探索其他支付模式,例如要求科技公司付款,同时补贴小型组织的成本。
AI 研究界也越来越一致认为,基准测试,尤其是语言领域的基准测试,如果要发挥作用,就必须考虑更广泛的伦理、技术和社会挑战。一些语言模型具有较大的碳足迹,但尽管人们普遍认识到这个问题,但尝试估算或报告其系统的环境成本的研究人员相对较少。
「[F] 只关注最先进的表现,而不是强调其他重要的标准,这些标准可以做出重大贡献,」Koch, Foster, Denton 和 Hanna说。「例如,SOTA 基准测试鼓励创建对环境不友好的算法。构建更大的模型是提高机器学习性能的关键,但从长远来看,它在环境上也是不可持续的……SOTA 基准测试 [也] 不鼓励科学家对他们在现实世界中的任务所带来的具体挑战进行细致入微的理解,反而可以鼓励提高分数的狭隘视野。实现 SOTA 的要求限制了可以解决现实世界问题的新算法或算法的创建。」
可能的 AI 数据集解决方案
考虑到 AI 数据集的广泛挑战,从不平衡的训练数据到不充分的基准,要做出有意义的改变并不容易。但专家认为,这种情况并非毫无希望。
普林斯顿计算机科学家 Arvind Narayanan 撰写了多部研究 AI 数据集来源的著作,他表示,研究人员必须采用负责任的方法,不仅要收集和注释数据,还要记录他们的数据集、维护它们并制定需要解决的问题。他们的数据集是设计好的。在他最近与他人合著的一项研究中,Narayanan 发现许多数据集容易管理不善,创建者未能在许可语言上准确说明如何使用他们的数据集或禁止可能存在问题的用途。

「研究人员应该考虑使用他们的数据集的不同方式……我们称之为负责任的数据集[管理],需要解决更广泛的风险,」他通过电子邮件告诉 VentureBeat。「一个风险是,即使数据集是为一个看似良性的目的而创建的,它也可能会被无意中以可能造成伤害的方式使用。该数据集可以重新用于道德上可疑的研究应用。或者,当数据集不是为这些高风险设置而设计时,它可以用于训练或基准测试商业模型。数据集通常需要大量工作才能从头开始创建,因此研究人员和从业人员通常希望利用已经存在的数据。负责任的数据集管理的目标是确保以合乎道德的方式进行。」
Koch 和合著者认为,人们和组织需要得到奖励和支持,以创建新的、多样化的数据集,以适应手头的任务。他们说,需要鼓励研究人员在像 NeurIPS 这样的学术会议上使用「更合适」的数据集,并鼓励他们进行更多的定性分析——比如他们模型的可解释性——以及报告指标,比如公平性(尽可能)和电源效率。
NeurIPS——世界上最大的机器学习会议之一——要求提交论文的合著者必须说明「他们的工作对社会的潜在更广泛影响」,从去年的 NeurIPS 2020 开始。这一进展喜忧参半,但 Koch 和合著者认为这是朝着正确方向迈出的一小步。
「[M] 机器学习研究人员正在创建大量数据集,但没有得到使用。这里的问题之一是,许多研究人员可能觉得他们需要包含广泛使用的基准来提高论文的可信度,而不是一个更小众但技术上合适的基准,」他们说。「此外,专业激励措施需要与创建这些数据集保持一致……我们认为仍有一部分研究界对伦理改革持怀疑态度,解决科学问题可能是让这些人支持改革的另一种方式机器学习中的评估。」
数据集注释问题没有简单的解决方案——假设标签最终不会被替代品所取代。但谷歌最近的一篇论文表明,研究人员最好与注释器(如聊天应用程序)建立「扩展通信框架」,以提供更有意义的反馈和更清晰的说明。共同作者写道,与此同时,他们必须努力承认(并实际考虑)工人的社会文化背景——从数据质量和社会影响的角度来看。

论文链接:https://arxiv.org/pdf/2112.04554.pdf
该论文更进一步,为数据集任务制定和选择注释器、平台和标记基础设施提供了建议。合著者说,除了审查数据集的预期用例外,研究人员还应考虑可以通过注释纳入的专业知识形式。他们还表示,他们应该比较和对比不同平台的最低工资要求,并分析不同群体注释者之间的分歧,让他们更好地理解不同的观点是如何表达或不表达的。
「如果我们真的想让使用的基准多样化,政府和企业参与者需要为数据集创建提供资助,并将这些资助分发给资源不足的机构和来自代表性不足的背景的研究人员,」Koch 和合著者说。「我们会说,现在有大量研究表明,机器学习中数据滥用可能会导致道德问题和社会危害……科学家喜欢数据,所以我们认为,如果我们能向他们展示过度使用对科学有何不利之处,可能会促使进一步的改革,从而减轻社会危害。」
参考内容:https://venturebeat.com/2021/12/17/3-big-problems-with-datasets-in-ai-and-machine-learning/

 友情链接
友情链接