








公众号/AI前线
辑 | Vincent

AI 前线导读:全球计算机视觉顶级会议 IEEE CVPR 2019(Computer Vision and Pattern Recognition,即 IEEE 国际计算机视觉与模式识别会议) 即将于六月在美国长滩召开,CVPR 官网显示,今年有超过 5165 篇的大会论文投稿,录取的 1299 篇论文,比去年增长了 32%(2017 年论文录取 979 篇)。这些录取的最新科研成果,涵盖了计算机视觉领域各项前沿工作。
2019 年腾讯公司有超过 58 篇论文被本届 CVPR 大会接收 ,其中腾讯优图实验室 25 篇、腾讯 AI Lab 33 篇。腾讯此次被收录的论文涵盖深度学习优化原理、视觉对抗学习、人脸建模与识别、视频深度理解、行人重识别、人脸检测等领域。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
以下是腾讯优图实验室的部分论文解读。
1. Unsupervised Person Re-identification by Soft Multilabel Learning
软多标签学习的无监督行人重识别
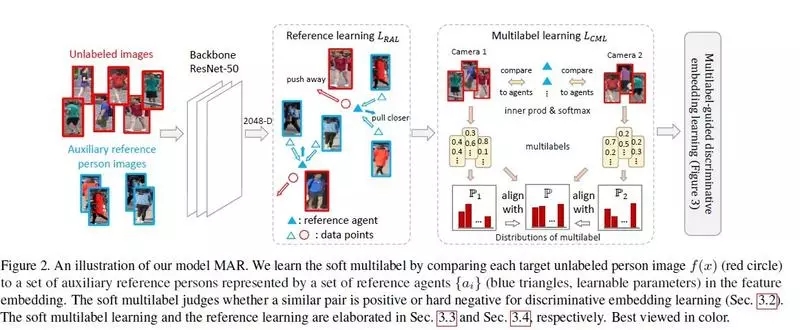
相对于有监督行人重识别(RE-ID)方法,无监督 RE-ID 因其更佳的可扩展性受到越来越多的研究关注,然而在非交叠的多相机视图下,标签对(pairwise label)的缺失导致学习鉴别性的信息仍然是非常具有挑战性的工作。为了克服这个问题,我们提出了一个用于无监督 RE-ID 的软多标签学习深度模型。该想法通过将未标注的人与辅助域里的一组已知参考者进行比较,为未标注者标记软标签(类似实值标签的似然向量)。基于视觉特征以及未标注目标对的软性标签的相似度一致性,我们提出了软多标签引导的 hard negative mining 方法去学习一种区分性嵌入表示(discriminative embedding)。由于大多数目标对来自交叉视角,我们提出了交叉视角下的软性多标签一致性学习方法,以保证不同视角下标签的一致性。为实现高效的软标签学习,引入了参考代理学习 (reference agent learning)。我们的方法在 Market-1501 和 DukeMTMC-reID 上进行了评估,显著优于当前最好的无监督 RE-ID 方法。
2. Visual Tracking via Adaptive Spatially-Regularized Correlation Filters
基于自适应空间加权相关滤波的视觉跟踪研究

本文提出自适应空间约束相关滤波算法来同时优化滤波器权重及空间约束矩阵。
首先,本文所提出的自适应空间约束机制可以高效地学习得到一个空间权重以适应目标外观变化,因此可以得到更加鲁棒的目标跟踪结果。其次,本文提出的算法可以通过交替迭代算法来高效进行求解,基于此,每个子问题都可以得到闭合的解形式。再次,本文所提出的跟踪器使用两种相关滤波模型来分别估计目标的位置及尺度,可以在得到较高定位精度的同时有效减少计算量。大量的在综合数据集上的实验结果证明了本文所提出的算法可以与现有的先进算法取得相当的跟踪结果,并且达到了实时的跟踪速度。
3. Adversarial Attacks Beyond the Image Space
超越图像空间的对抗攻击
生成对抗实例是理解深度神经网络工作机理的重要途径。大多数现有的方法都会在图像空间中产生扰动,即独立修改图像中的每个像素。在本文中,我们更为关注与三维物理性质(如旋转和平移、照明条件等)有意义的变化相对应的对抗性示例子集。可以说,这些对抗方法提出了一个更值得关注的问题,因为他们证明简单地干扰现实世界中的三维物体和场景也有可能导致神经网络错分实例。
在分类和视觉问答问题的任务中,我们在接收 2D 输入的神经网络前边增加一个渲染模块来拓展现有的神经网络。我们的方法的流程是:先将 3D 场景(物理空间)渲染成 2D 图片(图片空间),然后经过神经网络把他们映射到一个预测值(输出空间)。这种对抗性干扰方法可以超越图像空间。在三维物理世界中有明确的意义。虽然图像空间的对抗攻击可以根据像素反照率的变化来解释,但是我们证实它们不能在物理空间给出很好的解释,这样通常会具有非局部效应。但是在物理空间的攻击是有可能超过图像空间的攻击的,虽然这个比图像空间的攻击更难,体现在物理世界的攻击有更低的成功率和需要更大的干扰。
4. Learning Context Graph for Person Search
基于上下文图网络的行人检索模型
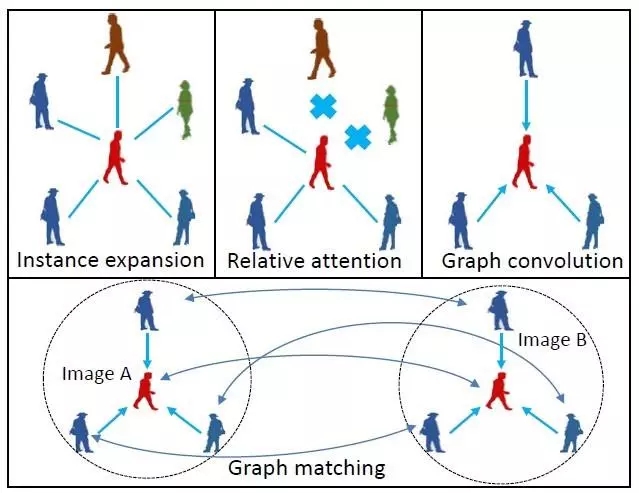
本文由腾讯优图实验室与上海交通大学主导完成。
近年来,深度神经网络在行人检索任务中取得了较大的成功。但是这些方法往往只基于单人的外观信息,其在处理跨摄像头下行人外观出现姿态变化、光照变化、遮挡等情况时仍然比较困难。本文提出了一种新的基于上下文信息的行人检索模型。所提出的模型将场景中同时出现的其他行人作为上下文信息,并使用卷积图模型建模这些上下文信息对目标行人的影响。我们在两个著名的行人检索数据集 CUHK-SYSU 和 PRW 的两个评测维度上刷新了当时的世界纪录,取得了 top1 的行人检索结果。
5. Underexposed Photo Enhancement using Deep Illumination Estimation
基于深度学习优化光照的暗光下的图像增强
本文介绍了一种新的端到端网络,用于增强曝光不足的照片。我们不是像以前的工作那样直接学习图像到图像的映射,而是在我们的网络中引入中间照明,将输入与预期的增强结果相关联,这增强了网络从专家修饰的输入 / 输出图像学习复杂的摄影调整的能力。基于该模型,我们制定了一个损失函数,该函数采用约束和先验在中间的照明上,我们准备了一个 3000 个曝光不足的图像对的新数据集,并训练网络有效地学习各种照明条件的丰富多样的调整。通过这些方式,我们的网络能够在增强结果中恢复清晰的细节,鲜明的对比度和自然色彩。我们对基准 MIT-Adobe FiveK 数据集和我们的新数据集进行了大量实验,并表明我们的网络可以有效地处理以前的困难图像。
6. Homomorphic Latent Space Interpolation for Unpaired Image-to-imageTranslation
基于同态隐空间插值的不成对图片到图片转换
生成对抗网络在不成对的图像到图像转换中取得了巨大成功。循环一致性允许对没有配对数据的两个不同域之间的关系建模。在本文中,我们提出了一个替代框架,作为潜在空间插值的扩展,在图像转换中考虑两个域之间的中间部分。该框架基于以下事实:在平坦且光滑的潜在空间中,存在连接两个采样点的多条路径。正确选择插值的路径允许更改某些图像属性,而这对于在两个域之间生成中间图像是非常有用的。我们还表明该框架可以应用于多域和多模态转换。广泛的实验表明该框架对各种任务具有普遍性和适用性。
7. X2CT-GAN: Reconstructing CT from Biplanar X-Rays with GenerativeAdversarial Networks
基于生成对抗网络的双平面 X 光至 CT 生成系统
当下 CT 成像可以提供三维全景视角帮助医生了解病人体内的组织器官的情况,来协助疾病的诊断。但是 CT 成像与 X 光成像相比,给病人带来的辐射剂量较大,并且费用成本较高。 传统 CT 影像的三维重建过程中围绕物体中心旋转采集并使用了大量的 X 光投影,这在传统的 X 光机中也是不能实现的。在这篇文章中,我们创新性的提出了一种基于对抗生成网络的方法,只使用两张正交的二维 X 光图片来重建逼真的三维 CT 影像。核心的创新点包括增维生成网络,多视角特征融合算法等。我们通过实验与量化分析,展示了该方法在二维 X 光到三维 CT 重建上大大优于其他对比方法。通过可视化 CT 重建结果,我们也可以直观的看到该方法提供的细节更加逼真。在实际应用中, 我们的方法在不改变现有 X 光成像流程的前提下,可以给医生提供额外的类 CT 的三维影像,来协助他们更好的诊断。

 友情链接
友情链接