








公众号/AI前线
策划编辑 | Natalie
作者 | 伯克利 RiseLab
译者 | 无明
编辑 | Vincent
AI 前线导读:如何优化 SQL 连接是数据库社区数十年来一直在研究的一个大问题。近日,伯克利 RiseLab 公布了一项研究表明,深度强化学习可以被成功地应用在优化 SQL 连接上。对于大型的连接,这项技术的运行速度比传统动态规划快上 10 倍,比穷举快上 10000 倍。这篇文章将介绍 SQL 连接问题以及这项强大的优化技术,更多详细内容可以参看论文”Learning to Optimize Join Queries With Deep Reinforcement Learning“(链接在文末)。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
数据库社区已经针对 SQL 查询优化问题进行了近 40 年的研究,可以追溯到 System R 的动态规划方法。查询优化的核心是连接排序问题。尽管这个问题由来已久,但仍然有很多研究项目尝试更好地理解多连接查询中的连接优化器的性能,或者解决在企业级“数据湖”中无处不在的大型连接查询问题。
在我们的论文中,我们表明了如何通过深度强化学习技术来攻克这个已经存在了数十年的挑战。我们将连接排序问题表示为马尔可夫决策过程(MDP),然后构建了一个使用深度 Q 网络(DQN)的优化器,用来有效地对连接进行排序。我们基于 Join Order Benchmark(最近提出的工作负载,专门用于压力测试连接优化)对我们的方法进行了评估。我们只使用了适量的训练数据,基于强化学习的深度优化器的执行计划成本比所有我们能想到的成本模型最优解决方案改进了 2 倍,比下一个最好的启发式改进最多可达 3 倍——所有这些都在计划的延迟范围,比动态规划快 10 倍,比穷举快 10000 倍。
为什么强化学习是解决连接排序问题的好方法?要回答这个问题,先让我们回顾一下传统的动态规划(DP)方法。
假设一个数据库包含三张表:Employees、Salaries 和 Taxes。下面这个查询用于找出“所有 Manager 1 员工的总税额”:

这个查询包含了三个关系连接。在下面的示例中,我们使用 J(R) 表示访问基本关系 R 的成本,使用 J(T1,T2) 表示连接 T1 和 T2 的成本。为简单起见,我们假设了一个访问方法,一个连接方法和一个对称连接成本(即 J(T1,T2)=J(T2,T1))。
经典的“left-deep”DP 方法首先计算访问三个基本关系的最佳成本,我们把结果放在一张表中:
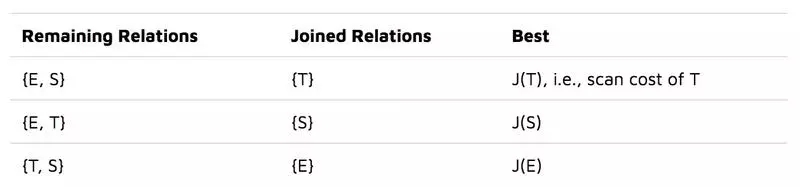
然后,它基于这些信息枚举所有二元关系。例如,在计算{E,S}连接的最佳成本时,它会查找先前相关的计算结果:
Best({E, S}) = Best({E}) + Best({S}) + J({E}, S)
这样就得到了新的一行:

这个算法遍历其他二元关系集,最终找到连接所有三张表的最佳成本。这需要在二元关系和基本关系的所有可能“left-deep”组合中取最小值:

这就是动态规划方法。请注意,J 的第二个操作数(关系的右边部分)始终是基本关系,而左边可以是中间连接结果(因此叫作“left-deep”)。这个算法的空间复杂度和时间复杂度将随着关系的数量增加呈指数级增长,这就是为什么它通常只被用于 10-15 个关系的连接查询。
我们的主要想法如下:不使用如上所示的动态规划来解决连接排序问题,而是将问题表示为马尔可夫决策过程(MDP),并使用强化学习(RL)来解决它,这是一种用于解决 MDP 的一般性随机优化器。
首先,我们将连接排序表示为 MDP:
可以简单地表示成 (G, c, G’, J) 。
我们使用 Q-learning(一种流行的 RL 技术)来解决连接排序 MDP。我们定义了 Q 函数 Q(G,c),它直观地描述了每个连接的长期成本:我们在当前连接决策之后对所有后续连接采取最佳操作的累积成本。
Q(G, c) = J(c) + \min_{c’} Q(G’, c’)
请注意,如果我们可以访问真正的 Q 函数,就可以进行贪婪的连接排序:
根据贝尔曼的最优性原则,我们的这个算法可证明是最优的。这个算法令人着迷的地方在于它的计算复杂度为 O(n^3),虽然仍然很高,但却远低于动态规划的指数级运行时复杂度。
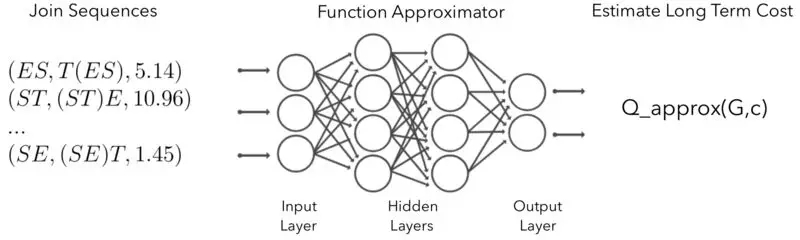
当然,实际上我们无法访问真正的 Q 函数,需要对其进行近似。为此,我们使用神经网络(NN)来学习 Q 函数,并称其为深度 Q 网络(DQN)。这项技术与用于学习 Atari 游戏专家级玩家能力的技术如出一辙。总而言之,我们的目标是训练一个神经网络,它接收 (G,c) 作为输入,并输出估算的 Q(G,c),见图 1。
现在介绍我们的深度强化学习优化器 DQ。
数据采集。要学习 Q 函数,我们首先需要观察过去的执行数据。DQ 可以接受来自任何底层优化器的一系列 (G,c,G’,J)。例如,我们可以运行经典的 left-deep 动态规划(如背景部分所示),并从 DP 表中计算出一系列“连接轨迹”。完整轨迹中的元组看起来像是 (G,c,G’,J)=({E,S,T}, join(S,T), {E,ST},110),它代表从初始查询图(状态)开始并将 S 和 T 连接在一起(动作)的步骤。
我们已经使用 J 表示连接的估算成本,但如果数据时从真实的数据库执行收集而来,我们也可以使用实际的运行时。
状态和动作的特征化。由于使用神经网络来表示 Q(G,c),我们需要将状态 G 和动作 c 作为固定长度的特征向量馈送到网络中。DQ 的特征化方案非常简单:我们使用 1-hot 向量来编码(1)查询图中存在的所有属性的集合,包括模式中的所有属性,(2)连接左侧的参与属性, (3)连接右侧的属性。如图 2 所示。

虽然这个方案非常简单,但我们发现它具有足够的表现力。需要注意的是,我们的方案(和学习的网络)假设的是一个固定的数据库,因为它需要知道确切的属性集和表集。
神经网络训练和规划。默认情况下,DQ 使用简单的两层全连接网络,并使用标准随机梯度下降进行训练。在完成训练后,DQ 可以接受纯文本的 SQL 查询语句,将其解析为抽象语法树,对树进行特征化,并在每次候选连接获得评分时调用神经网络(也就是在算法 1 的步骤 2 中调用神经网络 )。最后,可以使用来自实际执行的反馈定期重新调整 DQ。
为了评估 DQ,我们使用了最近发布的 Join Order Benchmark(JOB)。这个数据库由来自 IMDB 的 21 个表组成,并提供了 33 个查询模板和 113 个查询。查询中的连接关系大小范围为 5 到 15 个。当连接关系的数量不超过 10 个时,DQ 从穷举中收集训练数据。
比较。我们与几个启发式优化器(QuickPick 和 KBZ)以及经典动态规划(left-deep、right-deep、zig-zag)进行比较。我们对每个优化器生成的计划进行评分,并与最优计划(我们通过穷举获得)进行比较。
成本模型。随着新硬件的创新(例如 NVRAM)和向无服务器 RDBMS 架构(例如 Amazon Aurora Serverless)的转变,我们期望看到大量新的查询成本模型可以捕获不同的硬件特征。为了显示基于学习的优化器可以适应不同的环境,我们设计了 3 个成本模型:
从 CM1 到 CM3,成本表现出更多的非线性,向静态策略提出了挑战。
我们进行了 4 轮交叉验证,确保仅对未出现在训练工作负载中的查询进行 DQ 评估(对于每种情况,我们在 80 个查询上训练并测试其中的 33 个)。我们计算查询的平均次优性,即“成本(算法计划)/ 成本(最佳计划)”,这个数字越低越好。例如,对 Const Model 1,DQ 平均距离最佳计划 1.32 倍。结果如图 3 所示。
在所有成本模型中,DQ 在没有指数结构的先验知识的前提下可以与最优解决方案一比高下。对于固定的动态规划,情况并非如此:例如,left-deep 在 CM1 中产生了良好的计划(鼓励使用索引连接),但在 CM2 和 CM3 中效果没有那么好。同样,right-deep 计划在 CM1 中没有竞争力,但如果使用 CM2 或 CM3,right-deep 计划突然变得不那么糟糕。需要注意的是,基于学习的优化器比手动设计的算法更强大,可以适应工作负载、数据或成本模型的变化。
此外,DQ 以比传统动态规划快得多的速度产生了良好的计划(图 4)。
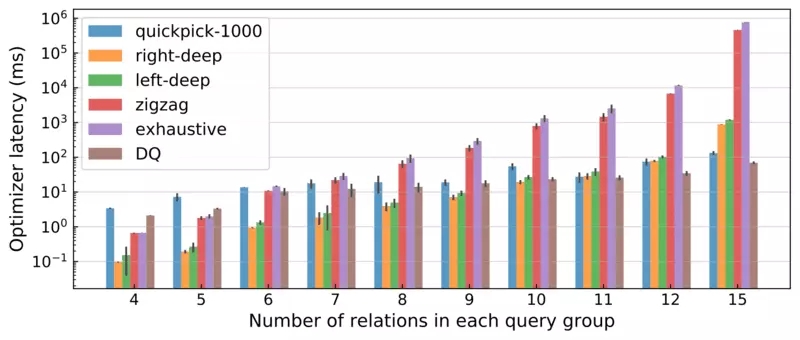
在大型连接机制中,DQ 实现了极大的加速:对于最大的连接,DQ 的速度是穷举的 10000 倍,比 zig-zag 快 1000 倍,比 left-deep 和 right-deep 枚举快 10 倍。性能增益主要来自神经网络提供的丰富的批处理机会——对于单个迭代中所有的候选连接,DQ 针对整个批处理调用一次 NN。我们相信,对于这样一个学习优化器来说,这是一个意义深远的性能改进:对于更大的查询或运行在专用加速器(例如 GPU、TPU)上时,它将表现出更大的优势。
我们认为深度强化学习非常适合用来解决连接排序问题。深度强化学习使用数据驱动方法来调整针对特定数据集和工作负载的查询计划,并观察连接成本,而不是使用固定的启发式。为了选择查询计划,DQ 使用了能够在训练时编对态规划表的压缩版本进行编码的神经网络。
DQ 只是冰山一角,在数据库社区存在激烈的争论,围绕着如何将更多的学习(或者说是数据适应性)纳入到现有系统中。我们希望我们的工作是实现更智能的查询优化器的第一步。有关详细信息,请参阅我们的 Arxiv 论文。
Arxiv 论文链接:
https://arxiv.org/abs/1808.03196
英文原文:
https://rise.cs.berkeley.edu/blog/sql-query-optimization-meets-deep-reinforcement-learning/

 友情链接
友情链接