








公众号:机器之心
深度学习专项课程 Deeplearning.ai 中,也包含吴恩达和多位深度学习大牛的对话视频,之前 YouTube 上已经公开了他与 Geoffrey Hinton、Yoshua Bengio、Ian Goodfellow、Andrej Karpathy 等人的对话视频。昨日,Deeplearning.ai 放出吴恩达对话 Yann LeCun 的视频,机器之心对此视频内容进行整理介绍。
视频链接:https://www.youtube.com/watch?v=JS12eb1cTLE&feature=youtu.be
吴恩达:Hi Yann,你研究神经网络很长一段时间了,我想听你讲下自己的故事:你是怎么开始做人工智能的?又是怎么构建神经网络的?
Yann LeCun:我从小就对「智能」很感兴趣,例如人类智能的出现、人类的进化等等。
而且我也对科技、太空等主题感兴趣。我最喜欢的电影是《2001 太空漫游》,里面有智能机器、太空旅游、人类进化等让我痴迷的东西。其中关于智能机器的概念真的很吸引我。
后来我学习的专业是电子工程,大概在工程学院的第二年的时候,我偶然发现了一本哲学书,里面有 MIT 语言学家乔姆斯基(Noam Chomsky)和瑞士研究儿童发展的认知心理学家让·皮亚杰(Jean Piaget)的辩论。这个辩论主要围绕语言的先天机制与后天培养。我们知道,乔姆斯基主张人类拥有语言是因为大脑内有大量的单元结构,是一种先天习得的机制,而皮亚杰认为儿童的语言发展是通过后天学习到的。这两方都聚拢了一批支持者为其辩护。
MIT 关注于感知机的西蒙·派珀特(Seymour Papert)支持皮亚杰的观点,他表示感知机(Perceptron)是首个可以学习的机器,而我之前从未听过。我读了那篇文章,觉得「可以学习的机器」听起来真妙。
所以,我开始在几所大学的图书馆里面搜索任何我能找到的、讨论感知机的书。随后我意识到,50 年代这个领域的论文很多,然而到了 60 年代,这种讨论随着西蒙与他人合著的关于感知机一本书而终止。
吴恩达:那大概是什么年份?
Yann LeCun:大概是 20 世纪 80 年代。
所以,后来我和大学的几位数学教授做了一些神经网络方面的项目。但 80 年代没有人能够与我讨论,因为基本上这个领域像消失了一样,很少人研究感知机。我只能自己做实验,写了很多用于模拟的程序,读了很多神经科学方面的书。
在结束工程课程之后,我学习了芯片设计。进行了一些项目之后,我觉得自己需要做这方面的研究,以解决当时比较重要的一类问题:如何训练多层的神经网络。60 年代的文献中明确表示这是一类没有解决的重要问题。我当时也读了很多文章,你知道 Kunihiko Fukushima 的 Neo-cognitron 论文提出的层级架构,非常类似于卷积网络,但没有类似反向传播的学习算法。

 论文链接:http://www.rctn.org/bruno/public/papers/Fukushima1980.pdf
论文链接:http://www.rctn.org/bruno/public/papers/Fukushima1980.pdf
后来,我在法国又碰到一小批人,他们也对此感兴趣,但他们称之为自动机网络(Automata Networks)。他们让我看了一些研究 Hopfield 网络的论文。你知道,这个网络并不是特别流行,但却是第一个带有联合记忆的神经网络。在 80 年代早期,这些研究重新引起了一些研究团体对神经网络的兴趣,其中大部分是物理学家,比如凝聚态物理学家,也有少数心理学家。这时候,工程师和计算机科学家并不参与讨论神经网络。
他们也让我看了另外一篇论文,即刚刚发布的预印版论文《Optimal Perceptual Inference》,这是第一篇有关玻尔兹曼机的论文,作者是 Geoffrey E. Hinton 和 Terrence J. Sejnowski。这篇论文讨论了隐藏单元,提出了多层神经网络比单纯的分类器更强大。我当即就说,我觉得我需要见见这群人,因为我对这些问题也非常感兴趣。后来,我读博士时参与了一场同事们组织的 workshop,当时 Terrence 做了演讲,我也碰到了 Hinton。
那是 1985 年,这是非常吸引人的一个 workshop,有很多早期的理论神经科学等领域的研究者。当时,我也碰见了后来招我进贝尔实验室的人。
在 workshop 上,我告诉 Terrence 我正在研究的类似反向传播的算法,这时 David E. Rumelhart、Geoffrey E. Hinton、Ronald J. Williams 三人的论文还没发表(指论文《Learning representations by back-propagating errors》),而 Terrence 与 Hinton 是朋友,常常互通有无。所以当时 Terrence 已经在做反向传播相关的工作,但他当时没告诉我。
所以,他回到美国告诉 Hinton,法国有个小孩也在做和我们同样的工作。然后几个月后(6 月),法国有另外一个会议,Hinton 是 keynote 演讲者,他介绍了用反向传播的玻尔兹曼机。演讲结束后大概有 50 人围绕在他身边,而他对主办方说的第一句话是,「你知道有个小孩叫 Yann LeCun 吗?」——当时,他在 Proceedings 上读了我的法语版论文,他懂一点法语,再加上数学公式,他能看懂那大概是反向传播。所以我们一起吃了午饭,然后成为了朋友。
吴恩达:所以你们分别独立重造了反向传播?
Yann LeCun:是的,或者说,我们意识到链式法则的重要性,也就是那些研究最优控制的学者所说的伴随态方法(adjoint state method),是非常重要的。而那才是反向传播真正被「发明」的环境: 20 世纪 60 年代的最优控制研究领域。「在不同的层级利用梯度」就是反向传播的实质,而这个概念在不同时期的不同语境下反复出现。但是 Rumelhart,Hinton 和 Williams 的论文让这个概念变得流行了起来。
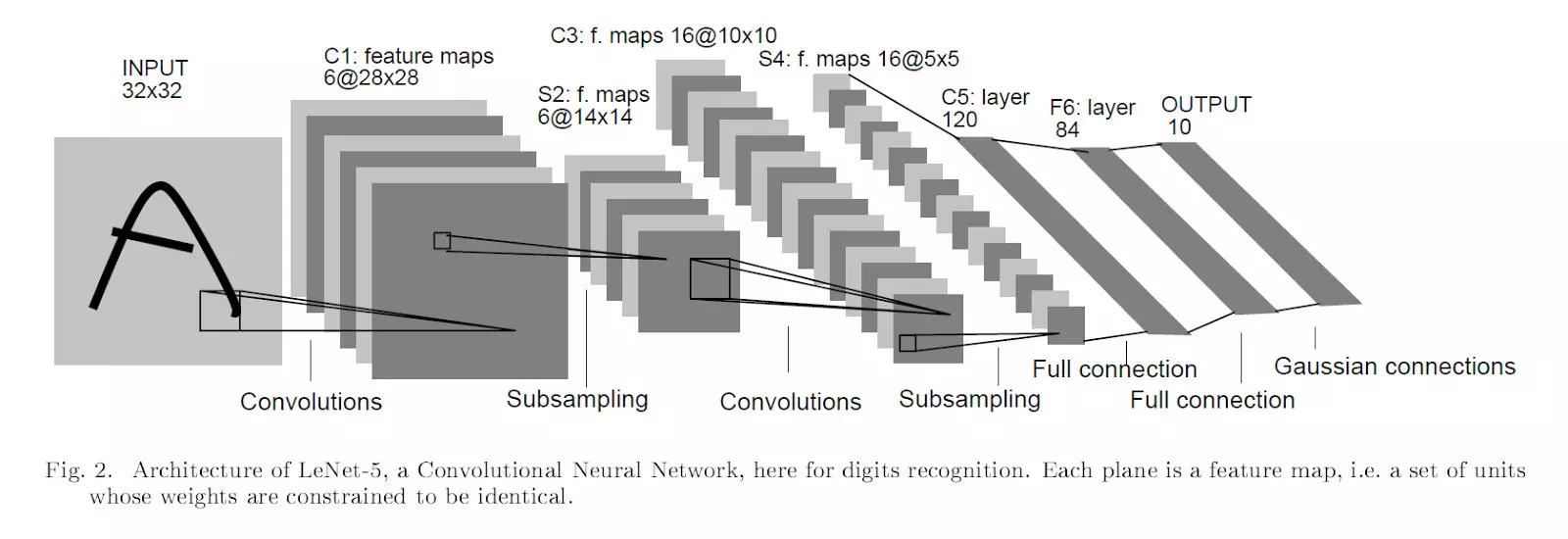
吴恩达:让我们快进几年,你在 AT&T 贝尔实验室工作过一段时间,期间,你的重要工作之一是发明了 LeNet。我在我的课程上提到了它,并且当我还是贝尔实验室的一名暑期实习生的时候,我就听说过你的工作。能否给我们讲述更多关于 AT&T 以及 LeNet 的故事呢?
Yann LeCun:我实际上是在博士后时期开始研究卷积神经网络的,当时我在多伦多大学 Jeff Hinton 组。我写了早期相关的代码,并做了第一批实验。
当时还没有 MNIST,我用鼠标画了一些字符,用数据扩增技术增加了数据量,然后用这个数据集测试模型的效果。
我比较了全连接神经网络、局部连接但是不共享参数的网络、以及局部连接且共享参数的网络,后者就是第一代卷积神经网络。
模型在小规模数据集上效果很好,有更好的表现,而且在卷积结构下没有过拟合。而当我在 1988 年 10 月进入贝尔实验室之后,我做的第一件事就是放大模型规模,因为那里有更快的电脑。就在我进入实验室几个月之前,我的老板 Larry Jekyll(后来他成为了贝尔实验室主任)问我:「我们应该在你来之前先订购电脑,你想要什么?」当时我们在多大,我们有一部 Sun-4,当时最好的电脑,所以我对他说,「如果(在实验室)也有一台的话会很赞。」于是他们订购了一台,所以我就自己拥有了一台电脑!
要知道,在多大,我们是整个系共享一台电脑,但是现在我自己就有一部电脑!当时 Larry 对我说,「在贝尔实验室,你不会因为省钱而闻名天下的」,这简直太棒了。而且,他们已经在字母识别任务上工作了一段时间,积累了一个「庞大」的数据集,叫做 USPS,有 5000 个训练样本。所以我立刻训练了一个卷积神经网络,你可以叫它 LeNet one,在 USPS 数据集上取得了相当不错的效果——比实验室或者外部人员试过的所有方法都要好。
那时我们就知道,我们做出了一些成果。此时距离我加入贝尔实验室仅仅三个月。
这是第一个版本的卷积神经网络,我们用了带有步幅(strides)移动的卷积运算,但没有单独的子采样(subsampling)也没有池化层(pooling),换言之每个卷积都在直接进行下采样。这样设计的原因是因为我们无法承担每个点都有一个卷积的计算量。
第二个版本有单独的卷积、池化和下采样层,这就是 LeNet one。我们在 Neural Computation 和 NIPS 上发表了一系列论文。
有趣的是,我在 NIPS 上做了一个关于这篇论文的演讲,Jeff Hinton 当时就在观众席。当我回到我的座位(我当时正好坐在他旁边),他说,「你的演讲传递一个信息:如果你做出所有合理的选择,模型会变得能用。(If you do all the sensible things, it actually works.)」
吴恩达:可以肯定的是这项工作在这之后继续创造着历史,这个思路开始被用于读取支票。
Yann LeCun:是,当时这项技术开始在 AT&T 内部应用,但是几乎没有在外部使用。
我很难解释其原因,但是我觉得有这样一些影响因素:
其一,当时是 80 年代末,没有互联网,我们有基于 FTP 的电子邮件,但那还并不是真正的互联网。
其二,没有任何两个实验室采用相同的软件或硬件平台。有些人用工作站,有些人用 PC,没有类似 Python 或者 MATLAB 这样的框架,人们都要自己写代码。
我和 Leon Powe 两个人花了大概一年半时间,基本上就写了个神经网络模拟器。而且因为没有 MATLAB 或者 Python,你得自己写解释器(interpreter)来控制你的模型,所以我们写了自己的 Lisp 解释器,LeNet 也就完全是用 Lisp 以及一个数值计算后端写的。结构和现在的框架很像,有不同的模块,你可以把它们相互连接起来,然后进行微分计算等所有那些现在为人熟悉的框架(Torch、PyTorch 或者 TensorFlow)都具有的功能。
然后我们和一群工程师一起开发了一系列应用。那是一群非常聪明的人,比如有的人原来是理论物理学家,后来来到贝尔实验室做了工程师。Chris Burgess 就是其中之一,他后来在微软研究院有着杰出的职业生涯。Craig Knoll 也是其中之一。我们和很多优秀的人合作,把这个特别的概念变成现实。
我们一起开发了很多应用,比如字母识别系统,那是一个结合了卷积神经网络和类似条件随机场(CRF)的模型,用来识别字母序列,而不是单独的字母。
吴恩达:是的,我读了那篇 LeNet 论文,先让数据通过一个神经网络,然后再让其通过一个自动机把识别出来的字母合并在一起。
Yann LeCun:是的,论文的前半在讲卷积神经网络,那是全文最激动人心的部分。而后半部分鲜少有人读过。后半部分讲的是序列层面的判别式学习(discriminantive learning)以及不带归一化(normalization)过程的结构预测,非常像 CRF。
这是个很成功的做法。当时 AT&T 的一个子公司 NCR 的一支产品团队是我们的「客户」,负责把我们的系统嵌入到能读取支票的 ATM 机等设备中。这个系统被部署到一家大型银行的那天,我们团队在一家高档餐厅吃饭庆祝,然而消息传来说,AT&T 决定拆分改组。当时是 1995 年,拆分后,AT&T 变为三家公司,分别是 AT&T,Lucent Technologies 和 NCR。工程团队被分到了 Lucent Technologies,产品团队被分到了 NCR。遗憾的是,AT&T 的律师团动用他们无尽的智慧之后决定把卷积神经网络的专利(是的,卷积神经网络是有专利的,但是谢天谢地它在 2007 年已经过期了)分给了 NCR,然而 NCR 完全没有人知道卷积神经网络到底是什么。所以 NCR 的人们手握卷积神经网络的专利却根本不知道自己掌握的是什么。而我们在另一家公司,无法再进行与卷积神经网络相关的研究。
吴恩达:除了那些神经网络很火的时期之外,你在「神经网络寒冬」里也坚持对神经网络的信念,那是什么感觉?
Yann LeCun:某种意义上来说我坚持了,另一个角度来看我也并没有。我始终相信这类技术会走回前沿,人们会找到在实际生活中应用它们的办法,我心底始终对此坚信不疑。但是在 1996 年,随着 AT&T 的拆分,我们所有的字母识别的工作基本上都停滞了,而我也升职成为了部门负责人,我必须为团队找到可以做的选题。当时还是互联网的萌芽期,我持有一个观点:随着互联网的兴起,我们必须找到把所有纸面上的知识转移到电子化世界的方法,所以我开始了一个叫 DjVu 的项目,旨在压缩扫描文件好让它们得以分布在互联网上。这个项目在一段时间内很有趣,取得了一定的成功,虽然 AT&T 也不知道该用它来做什么。
吴恩达:是的,我对那个项目有印象,旨在帮助线上传播研究工作。
Yann LeCun:是的,我们扫描了整本 NIPS 论文集,然后把它发布在了网上,来展示这项技术如何工作。我们可以把高清的扫描页压缩到几 kb。
吴恩达:你在非常早期的工作中展示出来的(对卷积神经网络的)信念现在已经席卷了计算机视觉领域,并且在持续影响其它领域,谈谈你是怎么看待这整个过程的。
Yann LeCun:我刚刚提到,我在很早就预见了这一切的发生。其一我一直相信这方法能行,虽然它需要很快的电脑和大量数据,但是我一直认为这是正确的做法。我在贝尔实验室的时候就见证了机器持续不断朝着越来越强大的方向进步,在贝尔实验室时期,我们就在设计芯片来运行卷积神经网络,我们用两块不同的芯片来高效地运行卷积神经网络,所以我们看到了芯片性能的改善,相信这会是一个持续不断的过程。
然而在 90 年代中期,对神经网络的兴趣逐渐走向衰微,所以这个过程没有立刻发生。在 1995 年到 2002 年这 6、7 年时间里,基本上没人进行相关研究。
微软在 21 世纪初,他们就用卷积神经网络做了中文字符识别,在法国以及其他地方也有一些小的有关人脸检测的工作,但规模都非常小。
我最近发现,有不少组提出的想法本质上与卷积神经网络非常相似,但是并没有发表,用于医疗图像分析。这些想法大部分是在卷积系统语境下,因此它并未应用到职业领域中。我的意思是在对卷积神经网络进行研究之后,研究者并未真正意识到它的力量,不过卷积神经网络依然得到了发展。
你知道很多人提出的想法是类似的,或者隔了几年提出的想法是类似的,但是在 2012 年 ImageNet 挑战赛出现后,研究者的兴趣改变得非常快。2012 年末在佛罗伦萨 ECCV 举办的 ILSVRC 2012 是一个非常有趣的赛事,ECCV 上有一个关于 ImageNet 的 workshop,每个人都知道 Geoffrey Hinton 团队的 Alex Krizhevsky 以极大的优势赢得了比赛,每个人都在等待 Alex Krizhevsky 的演讲,大会委员会的大部分人不知道 AlexNet 是什么。我的意思是他们听我讲过这个网络,在 CVPR 2000 会议上,但是大部分人并没有太注意它。一些资深的研究者知道 AlexNet 是什么,而社区中的大部分年轻人并不了解它。
然后 Alex Krizhevsky 进行了演讲,他并没有解释 AlexNet 是什么,因为他来自机器学习社区,认为所有人都已经知道了 AlexNet 的架构。很多人感到震惊,你可以看到在 Alex Krizhevsky 进行演讲的时候,人们的想法改变了,包括领域内非常资深的人。是的,计算机视觉领域的改变正是从那时开始。
吴恩达:那么今天你仍然保留 NYU 的教职,并且仍然在 FAIR 任职。我知道你对公司如何开展研究有着独到的见解,可以分享一下吗?
Yann LeCun:我认为过去四年在 Facebook 的经历最美好的体验就是我被赋予充分的自由来按照自己认为最合适的方式建设 FAIR,因为这是 Facebook 内部第一个研究组织。
Facebook 是一家以工程为中心的公司,目前又重新聚焦生存或一些短期问题。在创立快 10 年的时候,这家公司成功上市,那时候差不多就开始思考下一个 10 年的问题。他们告诉我扎克伯格关于未来 10 年的想法,哪些问题将变得重要。那时候,Facebook 的生存已经不是问题。对于大公司来说,或者对于当时只有 5000 名员工的 Facebook 来说,那是一个转折点,它可以开始思考下一个 10 年的问题,思考技术的发展重点。
马克及他的团队认为,AI 将会成为一项关键的社交网络技术,同时这也是 Facebook 的使命所在。因此,他们探索了几种 AI 的利用方式。他们组建了一个小型的内部团队,用卷积网络在人脸识别和其他几个方面取得了很好的效果,这激发了他们的兴趣。于是他们开始尝试聘用一批年轻的研究者,收购一家 AI 公司,还有其他一些类似的举措。最终,他们决定聘用该领域的资深专家并创建了一个研究组织。最初,这种做法遭遇了一点文化冲击,因为公司使用的研究方法与工程大相径庭。人们会问,为什么你的时间比别人长,范围比别人大?研究者们对于他们想要选择的研究领域非常保守。在很早的时候我就清楚,研究应该是开放的,我们不仅需要鼓励,还应该要求研究者去发表研究成果,同时以一种我们熟悉的衡量标准去衡量这些成果,从而让我们有机会了解这些研究。马克和 CTO 迈克表示 Facebook 是一个开放的公司,我们在开源方面也有很多贡献。我们的 CTO 就曾致力于开源,此外公司还有不少人也是如此。可以说开放是刻在 Facebook 骨子里的。因此,或许这让我们有信心建立开源研究组织,Facebook 不像其他有些公司一样对知识产权有着执着的追求,这种文化使得我们更容易与高校合作,在产业界和学界都能有所涉猎。
如果你看看我过去四年发表的论文,就会发现大部分论文是我 NYU 的学生一起写的,因为在 Facebook 我做了很多实验室组织工作,指导科研方向等,但是我没有涉及个人研究项目,让我的名字出现在论文上。我并不在意论文。你会想要呆在幕后,不想和实验室里的人竞争。
吴恩达:对想要进入 AI 领域的人,你有什么建议?
Yann LeCun:如今与我刚刚进入 AI 领域的时候已经大不相同了。我认为现在比较棒的是人们很容易就能达到一定水平,比如有方便使用的现成工具、TensorFlow、PyTorch 等,计算机会相对便宜,在家里就能训练卷积网络、循环网络。而且,你也可以在线学习。所以,你看现在高中生都在做 AI,我认为这非常棒。现在,从学生开始越来越多的人对机器学习、人工智能感兴趣。
我的建议是,如果你想做 AI,就要高度参与其中,例如为开源项目做贡献,或者实现一些标准算法。就像找到自己认为重要的论文,重现里面的算法,开源出来。如果你写的东西有用,你就会受到关注。这样,你可能就会收到中意公司的工作 offer,或者参与到喜欢的 PhD 项目中。

 友情链接
友情链接