








文/光谱
9 月初,百度首席科学家吴恩达宣布将开源该公司的人工智能综合平台“百度大脑”底层的深度学习平台Paddle 。
该平台全称为 Parallel Distributed Deep Learning(并行分布深度学习),已经在百度内部投入到生产环境,驱动了该公司旗下超过 30 个商业或非商业产品:小到优化百度网盘的性能,大到提供更准确和健康的搜索结果,甚至还驱动无人车的一部分功能。就连百度外卖也在使用 Paddle 来预估餐馆出餐速度,优化骑士的取餐送餐路径,让用户更快吃上饭。
Paddle 的主要研发负责人、杰出科学家徐伟在硅谷接受了PingWest品玩的采访,和我们聊了聊这一系统开源的意义。
徐伟 2013 年从 Facebook 离职加入百度深度学习研究院(IDL)。彼时 IDL 发现单 GPU 不再满足对深度神经网络的训练要求,同时百度搜索、广告、网盘以及新业务对深度学习也有了新的需求,而单 GPU 训练平台的性能和效率都稍显不足。于是,在徐伟的带领下,百度启动了 Paddle 这个并行 GPU 训练平台。
业界已经有不少开源的深度学习框架,比如 Google 的 TensorFlow、Facebook 的 Torch、伯克利视觉和学习中心的 Caffe 等等。开源 Paddle 让百度加入了这一新潮流,也成为了中国第一家开源深度学习系统的大型科技公司。
应该说,百度开源 Paddle 是有树立其在开源,特别是深度学习开源领域地位企图的。徐伟表示,除了这个出发点以外,更重要的是通过开源 Paddle 建立起一个社区,让这个深度学习平台能够为经验不多的工程师和深度学习爱好者所使用,让其开放和易用的优势表现出来,进而投入到更多的产业和学术研究当中,对开源的软件本身带来溢价。
“这两年很多初创公司成长都很快,这应该是开源的功劳。”徐伟说。他希望 Paddle 能够帮到更多中小企业。
具体来说,Paddle 包含多种在业界比较常用的深度学习模型,包括深度神经网络(DNN)、卷积神经网络(CNN)、递归神经网络(RNN)、复杂记忆模型、NTM 等,并支持多种优化算法。在模型训练方面,Paddle 顾名思义可以支持多机多显卡训练,能够充分利用使用者的硬件性能,并支持 Python/C++ 预测接口。
徐伟指出,Paddle 的最大优势之一就是易用,可以一键式安装,配备了丰富的 Demo 和完善的中英文双语文档。9 月初刚刚发布时支持的系统有限,经过一个月的优化调试,到本月底 Paddle 正式版开源时,应该会支持包括 Linux、macOS 在内的多种主流操作系统下的开发环境。
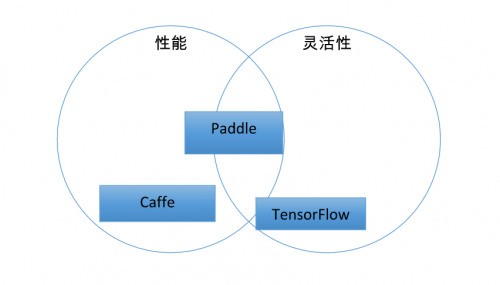
面对 Caffe、Torch、TensorFlow 和 Paddle,这么多开源深度学习框架,开发者该怎么选?实际上,这些框架对于不同使用者都会显示出有各自的优缺点,比如 Caffe 在图像上的优势很明显,而 TensorFlow 的底层支持非常完善,但使用 TensorFlow 来开发需要编写的代码量也显著更多,而且 TensorFlow 目前开源的版本只能够运行在单机上。
相对 TensorFlow 和其他“竞品”而言,Paddle 灵活和可扩展的优势就显现出来了。使用 Paddle 开发时书写简单的配置文件即可实现复杂模型,减少了多达 75% 的代码行数,而且他还可以支持多核、多 GPU 和多机环境,并又花了多设备之间的通信。
“开发者首先考虑自己想做的东西在你的平台上能不能做,能做才会考虑你。能做,接下来难度有多大,肯定是选择难度低的。能做、难度低,还要看性能好不好。”徐伟认为,Paddle 功能完善,性能优先并兼顾灵活,相对于其他优先灵活但提高了使用难度的系统而言,更值得考虑使用。
Paddle 和大部分深度学习系统一样,听上去复杂,但解决的都是那些实际、简单、重复,以往大多通过人工实现,很难通过机器跑程序完成处理的工作。
比如百度外卖。站在单一消费者的出发点上,消费者肯定希望自己的餐能尽快送到。对于骑士来说,每一趟都不止送一份餐,一趟送的越多效率越高,但消费者不都在同一家餐厅订餐,每个餐厅的出餐速度都不一样——这样下来,路线安排的好坏,直接影响到了消费者的体验。相信不少人都曾有过,在百度外卖上订餐但已经饿过劲了才收到餐的经历。
现在,百度将 Paddle 运营到了“预测商家出餐速度”这一项目上。这个系统将不同时段商家的客流量、菜品的制作时间、订单量等等影响出餐时间的数据整合并通过训练好的模型处理,预估出骑士这一趟需要取的每个菜品的出餐时间。骑士按照这个预估结果来规划路线,把餐更快地送到消费者手中,更少时间赚到更多佣金,两全其美。
再以百度网盘举例。用户使用的网盘背后,其实是一块一块连接到网络的硬盘。硬盘是一种耗材,当损坏时系统需要从多地寻找该硬盘的数据备份,消耗 9 倍的带宽去复原数据。现在百度使用 Paddle 预估硬盘损坏的时间,在损坏之前使用常规的带宽去备份,节省了大量的带宽资源。
诸多大型互联网公司的核心产品,在近年来都开始更加依赖深度学习系统。Google 的搜索,Facebook 的时间线都不例外。但在以往,也只有这些大公司才有足够的实力去研发、搭建和使用这样的系统。
Google 去年开源了 TensorFlow,被誉为业界良心。其实百度也想做这样的事情,也想让自家的深度学习能力被外界所了解。Caffe 的主要贡献者贾扬清评价 Paddle “代码质量高,设计很干净,是一个很 solid 的框架。”
百度已经为 Paddle 设立了官方网站。正式版将于 9 月 30 日放出,包含完整的文档和安装指导,现在 GitHub 上已经有了预发布版本。“我希望对深度学习感兴趣的朋友都来看看,尝试使用 Paddle,将它投入到更多的行业里去,去解决人工智能的更多问题。”徐伟说。
PingWest中文网


 友情链接
友情链接