








机器之心编译
参与:Pedro、张倩、刘晓坤
运行深度神经网络对计算能力、能耗及磁盘空间要求甚高,智能手机的计算资源十分有限,需要多种优化才能高效运行深度学习应用。本文介绍了如何在移动设备的各种指标之间取得平衡,在避免大幅度降低准确性的前提下构造更加轻便的神经网络,使得在移动设备上快速、准确地运行神经网络成为可能。
电脑拥有大容量硬盘和强大的 CPU 与 GPU,但智能手机没有。为了弥补这些硬件上的不足,智能手机需要一些特殊手段才能高效地运行深度学习应用。

智能手机有办法与这些强大的服务器集群竞争吗?还是完全没有希望?
引言
深度学习是一种功能十分多样和强大的技术,但是运行神经网络对计算能力、能耗及磁盘空间要求甚高。这对于在具有大型硬盘和多个 GPU 的服务器上运行的云应用来说一般不是问题。
不幸的是,在移动设备上运行神经网络并非易事。事实上,尽管智能手机的功能越来越强大,它们的计算能力、电池寿命及可用的磁盘空间依然十分有限,特别是那些非常依赖轻便性的应用。把应用做得轻便可以加快下载速度,减少更新,并且延长电池寿命,而这些都是用户迫切需要的。
为了执行图像分类、人像模式摄影、文本预测以及其他几十项任务,智能手机需要使用特殊方法来快速、准确地运行神经网络,且不占用过多内存空间。
在这篇文章中,我们将会了解一些最有效的、能让神经网络在手机上实时运行的技术。
能使神经网络更小更快的技术
基本上来讲,我们只对三个指标感兴趣:模型的准确率、速度、在手机中占用的内存。天下没有免费的午餐,因此我们不得不在这些指标之间作出一些权衡。
对于大部分技术来说,我们一边要关注指标,一边还要寻找一个叫做「饱和点」(saturation point)的东西。达到这个点之后,利用其他指标的损失实现某个指标的增益将不再可行。在到达饱和点前保持优化值,可以在两个指标上取得最佳结果。
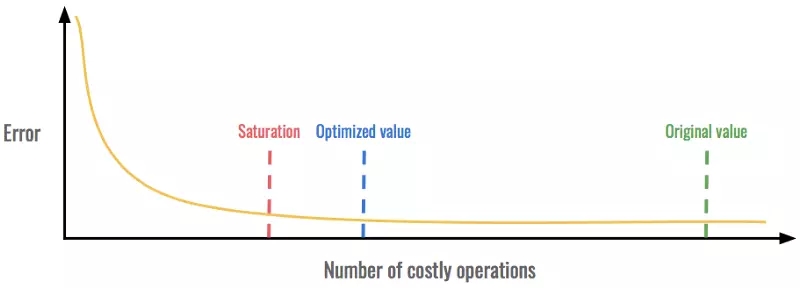
在这个例子中,我们可以在不增加误差的情况下显著减少代价昂贵的运算。但是,在超过饱和点之后,误差的严重程度高到不可接受。
记住这个方法,让我们开始吧!
1. 避免全连接层
全连接层是神经网络中最常见的部分,它们通常能发挥很大作用。然而,由于每一个神经元都和前一层的所有神经元相连接,因此它们需要存储和更新大量参数,这对速度和磁盘空间都很不利。
卷积层是利用输入(通常是图像)中局部一致性的层。每一个神经元不再与前一层的所有神经元相连。这有助于网络在保持高度准确性的同时减少连接/权重的数量。
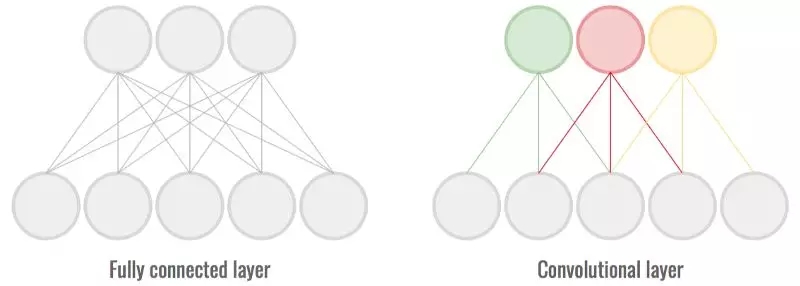
全连接层的连接/权重数量要远远多于卷积层。
使用少连接或非全连接的层能缩小模型的体积,同时保持其高准确性。这种方法可以提高速度,同时减少磁盘使用量。
在上面提到的构造中,一个拥有 1024 个输入、 512 个输出的全连接层大约有 500k 个参数。而一个拥有相同特征以及 32 个特征图的卷积层只需要大约 50k 个参数。这是一个 10 倍的提升。
2. 减少通道数量与卷积核大小
这一步展现了在模型复杂度与速度之间作出的一个非常直接的权衡。拥有大量通道的卷积层能使网络提取相关信息,但也要付出相应的代价。剔除一些特征图是一个节约空间、加速模型的简单方法。
我们可以运用卷积运算的感受野来做同样的事情。通过缩小卷积核大小,卷积对局部模式的感知减少,但涉及的参数也减少了。
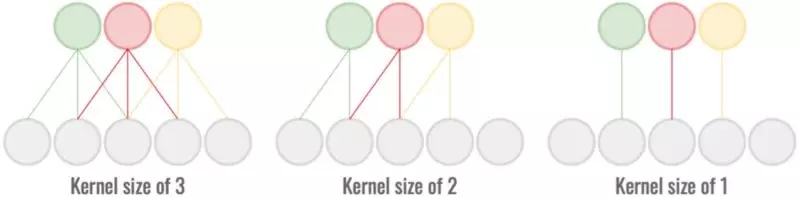
缩小感受野/卷积核大小可以降低计算成本,但是传递的信息会变少。
在这两种情况下,我们通过找到饱和点来选择特征图的数量/卷积核大小,以保证准确性不会下降太多。
3. 优化降采样
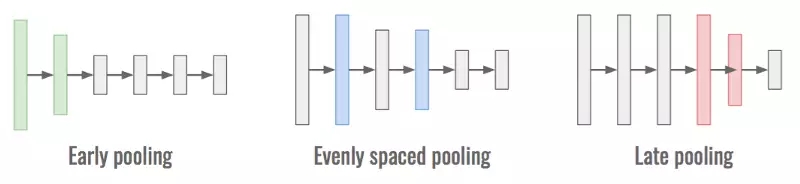
对于固定数量的层和固定数量的池化操作,神经网络可能会表现得天差地别。这是由于数据的表征以及计算量大小取决于这些池化操作于何处完成。
较早的池化速度快,延后的池化精确性高,均匀布置池化能兼具二者的一些优点。
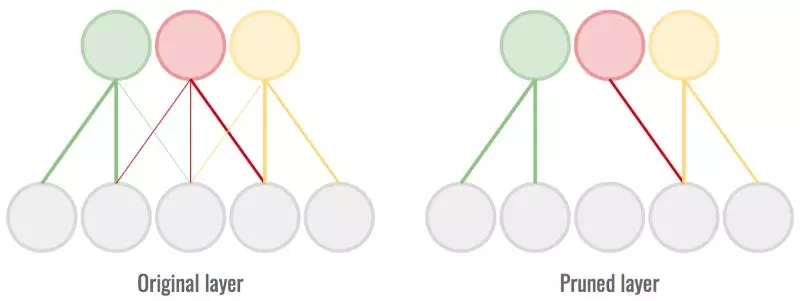
4. 权重修剪
在一个经过训练的神经网络中,有些权重对于某个神经元单元的激活值至关重要,而其他的权重基本不影响结果。尽管如此,我们仍要对这些不那么重要的权重做一些计算。
修剪(pruning)是一个完全删除最小强度连接的过程,这样我们就可以跳过这些计算。这会降低准确性但是能让网络更快更精简。我们需要找出饱和点,然后在尽量不影响准确性的情况下删去尽可能多的连接。
删去最弱的连接来节省计算时间与空间。
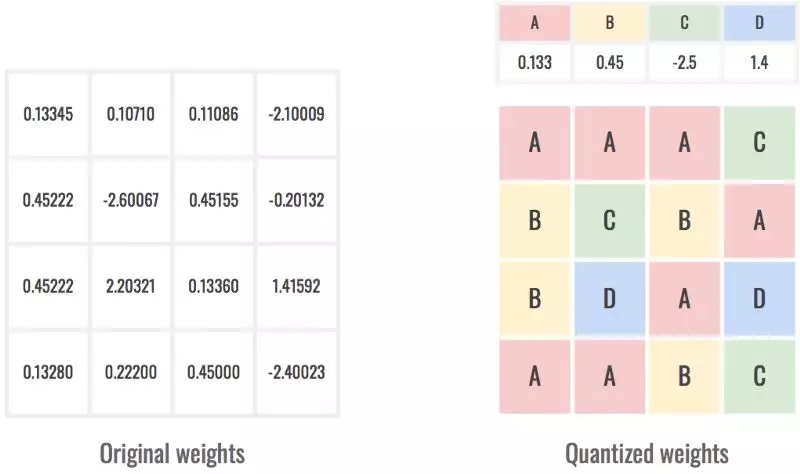
5. 离散化权重
为了在磁盘中保存神经网络,我们需要记录网络中每一个权重的值。这意味着我们需要为每一个参数保存一个浮点数,同时也意味着大量磁盘空间的消耗。举例说明,在 C 中一个浮点数占据 4 个字节,即 32 位。一个有着上亿参数的网络(如 Google-Net 或 VGG-16)会轻易占据上百兆字节的空间,而这样的消耗在移动设备中是不可接受的。
为了尽量减小网络存储的量,一种方法是通过离散化权重来降低权重的精度。在这个过程当中,我们更改数字的表示使其不再表示具体值,而是限制其为数值的子集。这样我们只需要存储一次经过离散化的值,然后将它们映射到网络的权重上。
离散化权重存储索引而非浮点值。
我们再次需要通过找到饱和点来决定到底使用多少个值。使用更多数值意味着准确性的提高,但也意味着更大的表征空间。举个例子:如果使用 256 个经过离散化的值,每一个权重只需要使用 1 个字节(即 8 位)就能表示。相比之前(32 位),我们将其大小缩减了四倍!
6. 模型表征的编码
我们已经对权重作了许多处理,但是还能进一步改进网络!这个特殊技巧源于权重分布不均的事实。一旦权重被离散化,我们就会失去相同数量的对应每一个离散化值的权重。这意味着在我们的模型表征中,某些索引的出现频率相对更高,我们可以利用这一点!
哈夫曼编码(Huffman coding)能完美地解决这个问题。它通过给最常用的值分配最小索引以及给最不常用的值分配最大索引来解决这些问题。这有助于减小设备上模型的体积,最关键的是不会降低准确性。
访问次数最多的符号只使用 1 位的空间,而访问次数最少的符号使用 3 位的空间。这是因为后者在数据表示中出现的次数很少,并由此可以达到一种空间上的平衡。
这个简单的技巧使我们能够进一步缩小神经网络占用的空间,通常能减少 30% 左右。
注意:每一层的离散化和编码可以是不同的,从而提供更大的灵活性。
修正准确率损失
通过我们使用的方法,神经网络已经十分精简了。我们删去了弱连接(修剪),甚至改变了一些权重(离散化)。在网络变得十分轻巧快速的同时,其准确率也不如以前了。
为了修正这一点,我们需要迭代地重新训练网络的每一步。这代表我们需要在修剪和离散化操作之后,再次训练网络使其可以拟合相应的变化,然后重复这一过程直到权重不再大幅变化为止。
结论
尽管智能手机没有优秀的台式机那样的磁盘空间、计算能力或者电池寿命,它们仍是深度学习应用程序的优秀实验对象。通过一系列方法,我们现在可以在这些多功能手持设备上运行强大的神经网络,准确性只是略有下降。这为数千个优秀的应用打开了大门。
如果有兴趣,你也可以了解一些面向移动设备的优秀神经网络,如 SqueezeNet(https://arxiv.org/abs/1602.07360)或 MobileNets(https://arxiv.org/abs/1704.04861)。
原文链接:https://heartbeat.fritz.ai/how-smartphones-manage-to-handle-huge-neural-networks-269debcb243d

 友情链接
友情链接