








雷锋网(编译)
文/三川
日前,知名 AI 博主、爱尔兰国立大学 NLP 博士生 Sebastian Ruder 以“迁移学习:机器学习的下一个前线”为题,对迁移学习的技术原理、重要性与意义、应用方法做了详细阐述。本文对其中讨论迁移学习的原理、重要性,以及吴恩达的预测的部分做了节选。
Sebastian Ruder:在训练深度神经网络、学习输入到输出的精准映射上,近年来我们做得越来越好。不管是针对图像、语句,还是标签预测,有了大量做过标记的样例,都已不再是难题。

Sebastian Ruder
今天的深度学习算法仍然欠缺的,是在新情况(不同于训练集的情况)上的泛化能力。
在什么时候,这项能力是必须的呢?——当你把模型应用于现实情形,而非小心翼翼整理好的数据集的时候。现实世界是相当混乱的,包含无数的特殊情形,会有许多在训练阶段模型没有遇到过的情况。因而未必适于对新情况做预测。
把别处学得的知识,迁移到新场景的能力,就是迁移学习。
在机器学习的传统监督学习情况下,如果我们准备为某个任务/领域 A 来训练模型,获取任务/领域 A 里标记过的数据,会是前提。图 1 把这表现的很清楚:model A 的训练、测试数据的任务/领域是一致的。
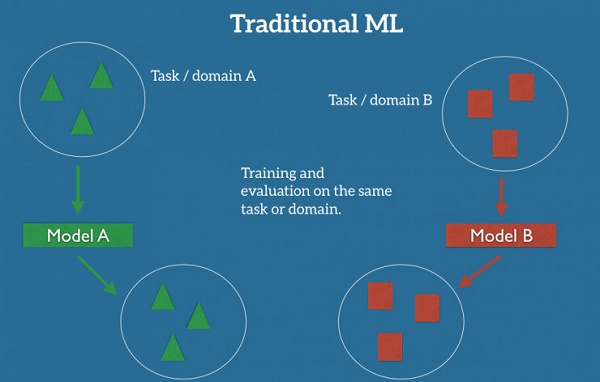
图 1: 传统的 ML 监督学习
可以预期,我们在该数据集上训练的模型 A,在相同任务/领域的新数据上也能有良好表现。另一方面,对于给定任务/领域 B,我们需要这个领域的标记数据,来训练模型 B,然后才能在该任务/领域取得不错的效果。
但传统的监督学习方法也会失灵——在缺乏某任务/领域标记数据的情况下,它往往无法得出一个可靠的模型。举个例子,如果我们想要训练出一个模型,对夜间的行人图像进行监测,我们可以应用一个相近领域的训练模型——白天的行人监测。理论上这是可行的。但实际上,模型的表现效果经常会大幅恶化,甚至崩溃。这很容易理解,模型从白天训练数据获取了一些偏差,不知道怎么泛化到新场景。
如果我们想要执行全新的任务,比如监测自行车骑手,重复使用原先的模型是行不通的。这里有一个很关键的原因:不同任务的数据标签不同。但有了迁移学习,我们能够在一定程度上解决这个问题,并充分利用相近任务/领域的现有数据。迁移学习试图把处理源任务获取的知识,应用于新的目标难题,见图 2。
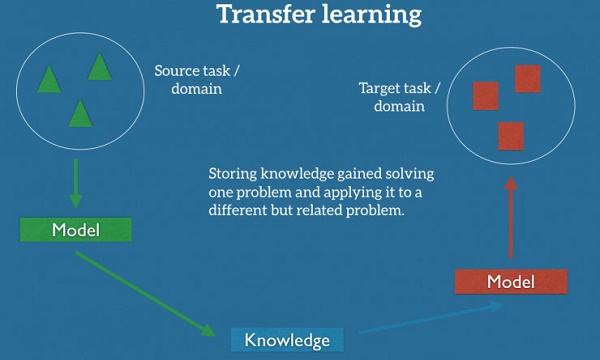
图 2: 迁移学习
实践中,我们会试图把源场景尽可能多的知识,迁移到目标任务或者场景。这里的知识可以有许多种表现形式,而这取决于数据:它可以是关于物体的组成部分,以更轻易地找出反常物体;它也可以是人们表达意见的普通词语。
在去年的 NIPS 2016 讲座上,吴恩达表示:“在监督学习之后,迁移学习将引领下一波机器学习技术商业化浪潮。”
雷锋网(公众号:雷锋网)获知,当时,吴恩达在白板上画了一副草图,对他的立场进行解释。Sebastian Ruder 将其用电脑绘制了出来,便是下图:
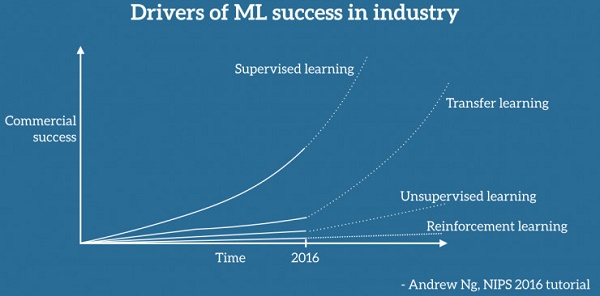
该图是吴恩达眼中,推动机器学习取得商业化成绩的主要驱动技术。从中可以看出,吴老师认为下一步将是迁移学习的商业应用大爆发。
有一点是毋庸置疑的:迄今为止,机器学习在业界的应用和成功,主要由监督学习推动。而这又是建立在深度学习的进步、更强大的计算设施、做了标记的大型数据集的基础上。近年来,这一波公众对人工智能技术的关注、投资收购浪潮、机器学习在日常生活中的商业应用,主要是由监督学习来引领。如果我们忽略“AI 冬天”的说法,相信吴恩达的预测,机器学习的这一波商业化浪潮应该会继续。
另外一点却不是那么清楚:为什么迁移学习已经存在数十年了,但却在业界没什么人用?更进一步,吴恩达预测的迁移学习商业应用爆发式增长,究竟是否会发生?
相比无监督学习和强化学系,迁移学习目前的曝光程度不高,但越来越多的人正把目光投向它。
对于前两者,比如说被认为是“通用 AI”(General AI)关键的无监督学习,其重要性随着 Yann LeCun 的布道以及“蛋糕论”越来越受到认可,激起又一波关注。生成对抗网络在其中扮演技术先锋角色。对于强化学习,最显著的推动力量是谷歌 DeepMind。没错,我指的是 AlphaGo。强化学习技术已经在现实场景取得成功应用,比如降低了 40% 的谷歌数据中心温控成本。
Yann LeCun 蛋糕论。在他看来,强化学习是樱桃,监督学习是糖衣,无监督学习才是糕体。但耐人寻味的是,其中并没有迁移学习。
这两个领域都前景光明。但是,在可预期的将来,它们恐怕只会产出相对有限的商业化成果——更多是学术成果,存在于尖端研究和论文中。这是因为这两个领域面临的技术挑战仍然非常严峻。
当前,业界对机器学习的应用呈现二元化:
尖端模型的性能已强到什么程度呢?
最新的残差网络(residual networks)已经能在 ImageNet 上取得超人类的水平;谷歌 Smart Reply 能自动处理 10% 的手机回复;语音识别错误率一直在降低,精确率已超过打字员;机器对皮肤癌的识别率以达到皮肤科医生的水平;谷歌 NMT 系统已经应用于谷歌翻译的产品端;百度 DeepVoice 已实现实时语音生成……
这个列表可以搞得很长。我要表达的意思是:这个水平的成熟度,已经让面向数百万用户的大规模模型部署变得可能。
同时,当机器学习模型被应用于现实情形,它会遇到无数的、此前未遭遇过的情况;也不知道该如何应付。每个客户、用户都有他们的偏好,会产生异于训练集的数据。模型需要处理许多与此前训练的任务目标相近、但不完全一样的任务。当今的尖端模型虽然在训练过的任务上有相当于人类或超人类的能力,但在这些情况下,性能会大打折扣甚至完全崩溃。
迁移学习是对付这些特殊情况的杀手锏。许多产品级的机器学习应用,需要进入标记数据稀缺的任务领域,对于这类商业应用,迁移学习无疑是必需的。今天,数据的“低树果实”基本已经被摘光,接下来,必须要把学得的东西迁移到新的任务与领域中。


 友情链接
友情链接