








公众号/将门创投
来源:https://arxiv.org/pdf/1902.02086.pdf
编译:Simons
对于任何移动机器人系统来说,确定自己与周围障碍在环境中的位置是环境感知的基本任务。通常人们使用深度相机或者Lidar来获取环境的深度信息,但都面临着一系列无法解决的困难,除了传感器需要庞大的计算外,高质量的激光雷达至今依旧售价高昂、而深度相机在室外光照变化的环境往往包含了难以去除的噪声。
为了解决这些问题,研究人员将目光投向了深度学习,利用生成模型实现了深度估计和定位任务,为机器人环境感知带来了全新的解决方案。来自福特的无人驾驶研究人员提出了一个基于深度学习的系统,可通过单目RGB传感器实现位姿估计和深度估计。整个系统基于传统的几何SLAM结果来训练,实现单个相机能够输出其在环境中的拓扑姿态,以及周围障碍物的深度图。
研究人员假设三维几何场景和二维相机图像共享同一个隐含空间编码,来自这一隐空间采样的编码和基于位姿的位置条件信息可以更好的恢复出深度图,以及与环境位姿对应的RGB图。作者使用CNN网络实现拓扑地图中的定位功能,并使用条件变分自编码器来输出相机图像的深度信息,采用拓扑位置作为条件输入。最后,通过仿真和真实数据集实验作者验证了单目定位和深度估计系统的有效性。

图1 GEN-SLAM结构
与传统的判别式模型求条件分布p(xdep|xrgb)相比,作者使用生成模型来学习彩色图像与深度图像之间的联合分布p(xrgb, xdep),这是首次在SLAM问题中引入生成式模型。作者认为三维几何场景(深度图)及其到相机平面的二维投影(彩色图像)拥有相同的隐子空间,采用变分自编码器(Variational Autoencoder, VAE)来输出彩色图像对应的深度图。如上图1所示,蓝色和橙色分别表示RGB和深度VAEs,网络中有2个编码器、2个解码器,训练过程中作者采用了如下4个重构损失,建立联合优化。

其中四项分别代表了rgb和深度图自身和相互之间的重构损失。作者认为添加位置信息作为额外标签会使得RGB到深度的转换效果更好,因此还使用了每幅图像对应的拓扑节点作为条件输入。如下图所示,给定一个确定的位置条件输入,我们就可以生成新的RGB和深度图,如果位置信息给的不好,就会产生较为虚幻的场景。

图2 Living Room数据集中,每个拓扑节点对应的RGB、深度, 抽样RGB、抽样深度图
在网络中,输入的彩色图,像一方面通过Topo CNN获得拓扑姿态,另一方面通过RGB编码器得到对应的隐向量,两者相互串联后通过Depth解码器即可获得彩色图像对应的深度图。具体的配置细节如下:
a. 数据采集。作者使用非真实游戏引擎UE4和UnrealCV插件来生成RGB和depth的仿真数据集;真实数据集作者希望场景中尽可能少动态目标,并且机器人的路径可以循环多次实验。最后,作者用StereoZed相机在手推车上完成了办公室场景的数据采集。
b. 拓扑地图生成。作者采用ORB-SLAM2算法获得相机运动轨迹,为确保路径可重复,作者先用ORB-SLAM2建图并保存,在后续实验中以此地图来实现定位功能,并让机器人按照同样的路径运动。
c. 网络模型。Topo CNN是由在ImageNet上预训练好的Alex-net网络修改而得,移除最后的分类层,并将输出数量与拓扑节点数一致。作者采用PyTorch框架来实现条件变分自编码器,如下图所示,使用卷积和反卷积,以及instance norm (INS)、leaky RELU 和 residual (Res)层。
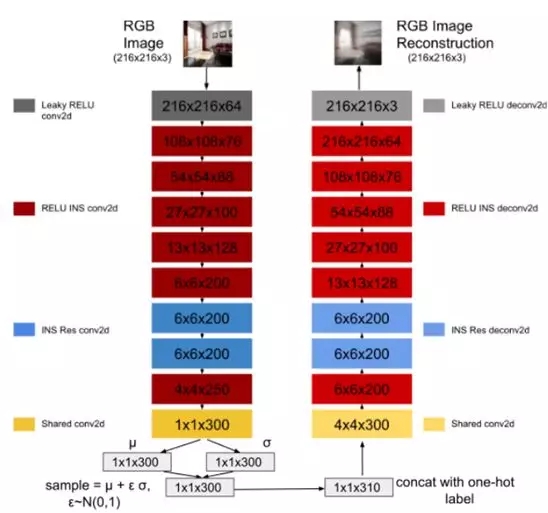
图3 RGB-VAE的结构示意图
实验结果:
如下图所示,是Lab数据集上的拓扑定位和深度图估计结果。四行小图从左到右分别是输入RGB图像、深度真实值图像、深度估计值图像。中间绿色表示拓扑节点,红色轨迹代表定位结果,数字按顺序分别代表了四行图像从上到下,从RGB到深度图重构的拓扑位置。
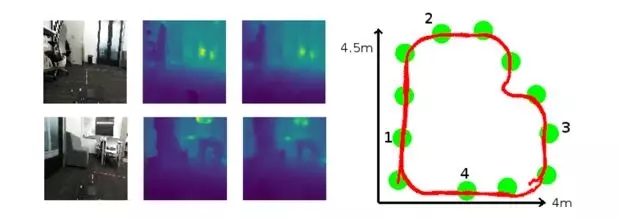
图4 Lab数据集上的拓扑定位和深度图估计结果
作者采用了下表中的多种指标来评估提出的深度估计器方法的有效性。其中,作者计算了每个数据集的真实深度平均值来描述不同场景的尺度。Corridor的Mean depth最大,自然而然它的RMSE也要比其他两个数据集的结果要大的多。作者提出的拓扑CNN的定位方法在数据集上的准确率接近了100%
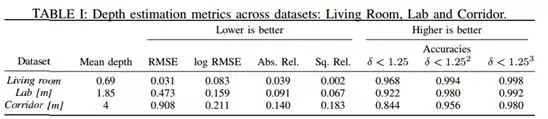
表1 Living Room, Lab和Corridor数据集上的深度估计结果度量

表2 Living Room, Lab和Corridor数据集上拓扑CNN的定位准确率
效果这么好让我们不禁要问,为什么选用VAE而不选用常规的编码解码网络结构呢?
这是因为VAE硬性要求隐向量服从高斯分布,在本文的问题中,场景的3D几何(深度图)和2D投影(RGB图)在拓扑姿态上的条件概率强制服从同分布。而VAE双网络可以让我们通过弱监督的方式训练网络。本文中的拓扑姿态还可以作为目标检测以及光照的额外先验,在不同的光照条件和动态场景下得到更好的深度估计。
本文预先建好的地图相对简单,路径也是单个圈的轨迹。未来可以基于此设计更复杂的路径和地图生成算法,这就会更加适用于工厂或物流场景中的移动机器人应用了。 物流中心一般都是拥有数十万平方米货架和仓储的工厂环境,里面有成百上千移动机器人被用来搬运货物。在如此复杂的环境中实现它们的自主导航功能是十分必要的,而且需要控制每个机器人的传感器成本,毕竟都配备昂贵的激光雷达是不现实的。基于这篇文章提出的方案可以先使用深度传感器和传统几何SLAM方法进行一次预先构建地图,然后用该地图作为先验结合本文的模型进行训练。随后这些移动机器人只需要配备低成本的单目相机,就可以利用训练好的模型来实现复杂工厂环境下的感知与导航了。
随着深度学习的快速发展,网络模型的准确性和有效性也越来越高,个体机器人也逐渐可以从低成本、便捷、低功耗的传感器中获得丰富的环境感知信息,这将大大促进机器人的智能化发展,让小块头也有大作为。
更多详情请观看作者的介绍视频:https://youtu.be/WGuB1cO0mCY
更多参考:
https://twitter.com/greenfieldlabs
paper:https://arxiv.org/pdf/1902.02086.pdf

 友情链接
友情链接